🇹🇭 Chinda Thai LLM 4B
แบบจำลองล่าสุด คิดเป็นภาษาไทย ตอบเป็นภาษาไทย สร้างโดยสตาร์ทอัพไทย
Chinda Thai LLM 4B คือแบบจำลองภาษาไทยที่ล้ำสมัยของบริษัท ไอแอพพ์เทคโนโลยี จำกัด ซึ่งนำความสามารถในการคิดขั้นสูงมาสู่ระบบนิเวศ AI ของไทย สร้างขึ้นบนสถาปัตยกรรม Qwen3-4B ล่าสุด Chinda สะท้อนถึงความมุ่งมั่นของเราในการพัฒนาโซลูชัน AI อธิปไตยสำหรับประเทศไทย
🚀 ลิงก์ด่วน
- 🌐 เดโม: https://chindax.iapp.co.th (เลือก ChindaLLM 4b)
- 📦 ดาวน์โหลดโมเดล: https://huggingface.co/iapp/chinda-qwen3-4b
- 🐋 Ollama: https://ollama.com/iapp/chinda-qwen3-4b
- 📄 ใบอนุญาต: Apache 2.0
📚 บทแนะนำ
- การใช้งาน Chinda LLM 4B กับ LM Studio - คู่มือผู้ใช้ฉบับสมบูรณ์
- การใช้งาน Chinda LLM 4B กับ OpenWebUI - คู่มือผู้ใช้ฉบับสมบูรณ์
- การใช้งาน Chinda LLM 4B กับ Ollama - คู่มือผู้ใช้ฉบับสมบูรณ์
- การใช้งาน Chinda LLM 4B กับ n8n - คู่มือการทำงานอัตโนมัติฉบับสมบูรณ์
✨ คุณสมบัติหลัก
🆓 0. ฟรีและโอเพนซอร์สสำหรับทุกคน
Chinda LLM 4B เป็นแบบโอเพนซอร์สและใช้งานได้ฟรีทั้งหมด ช่วยให้นักพัฒนา นักวิจัย และธุรกิจสามารถสร้างแอปพลิเคชัน AI ภาษาไทยได้โดยไม่มีข้อจำกัด
🧠 1. แบบจำลองการคิดขั้นสูง
- คะแนนสูงสุดในบรรดา LLM ภาษาไทยในกลุ่ม 4B
- สลับโหมดการคิดและการไม่คิดได้อย่างราบรื่น
- ความสามารถในการให้เหตุผลที่เหนือกว่าสำหรับปัญหาที่ซับซ้อน
- สามารถปิดเพื่อการสนทนาทั่วไปที่มีประสิทธิภาพ
🇹🇭 2. ความแม่นยำของภาษาไทยที่ยอดเยี่ยม
- ความแม่นยำ 98.4% ในการสร้างผลลัพธ์ภาษาไทย
- ป้องกันการแสดงผลภาษาจีนและภาษาต่างประเทศที่ไม่ต้องการ
- ปรับแต่งมาโดยเฉพาะสำหรับรูปแบบภาษาไทย
🆕 3. สถาปัตยกรรมล่าสุด
- ใช้โมเดล Qwen3-4B ล่าสุด
- ผสานรวมความก้าวหน้าล่าสุดในการสร้างแบบจำลองภาษา
- ปรับให้เหมาะสมทั้งประสิทธิภาพและประสิทธิภาพ
📜 4. ใบอนุญาต Apache 2.0
- อนุญาตให��้ใช้ในเชิงพาณิชย์
- อนุญาตให้ดัดแปลงและเผยแพร่ได้
- ไม่มีข้อจำกัดในการใช้งานส่วนตัว
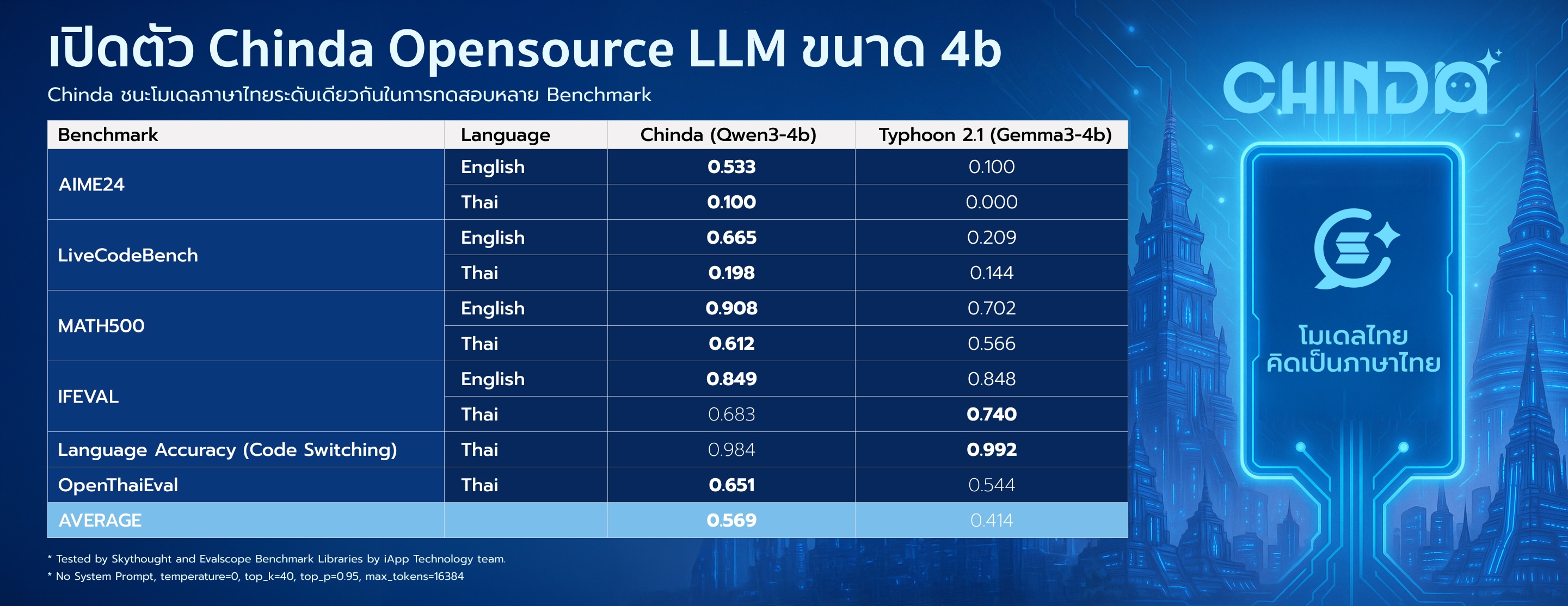
📊 ผลการทดสอบ
Chinda LLM 4B แสดงประสิทธิภาพที่เหนือกว่าเมื่อเทียบกับแบบจำลองภาษาไทยอื่น ๆ ในกลุ่มเดียวกัน:
| การทดสอบ | ภาษา | Chinda LLM 4B | ทางเลือก* |
|---|---|---|---|
| AIME24 | ภาษาอังกฤษ | 0.533 | 0.100 |
| ภาษาไทย | 0.100 | 0.000 | |
| LiveCodeBench | ภาษาอังกฤษ | 0.665 | 0.209 |
| ภาษาไทย | 0.198 | 0.144 | |
| MATH500 | ภาษาอังกฤษ | 0.908 | 0.702 |
| ภาษาไทย | 0.612 | 0.566 | |
| IFEVAL | ภาษาอังกฤษ | 0.849 | 0.848 |
| ภาษาไทย | 0.683 | 0.740 | |
| ความแม่นยำภาษา | ภาษาไทย | 0.984 | 0.992 |
| OpenThaiEval | ภาษาไทย | 0.651 | 0.544 |
| เฉลี่ย | 0.569 | 0.414 |
- ทางเลือก: scb10x_typhoon2.1-gemma3-4b
ทดสอบโดย Skythought และ Evalscope Benchmark Libraries โดยทีมงานไอแอพพ์เทคโนโลยี ผลการทดสอบแสดงให้เห็นว่า Chinda LLM 4B มี ประสิทธิภาพโดยรวมดีกว่า 37% เมื่อเทียบกับทางเลือกที่ใกล้เคียงที่สุด
✅ เหมาะสำหรับ
🔍 1. แอปพลิเคชัน RAG (AI อธิปไตย)
เหมาะอย่างยิ่งสำหรับการสร้างระบบ Retrieval-Augmented Generation ที่ช่วยให้การประมวลผลข้อมูลอยู่ภายใต้อธิปไตยของไทย
📱 2. แอปพลิเคชันมือถือและแล็ปท็อป
แบบจำลองภาษาขนาดเล็กที่เชื่อถือได้ ปรับให้เหมาะสมสำหรับการประมวลผลที่ปลายทางและอุปกรณ์ส่วนตัว
🧮 3. การคำนวณทางคณิตศาสตร์
ประสิทธิภาพที่ยอดเยี่ยมในการให้เหตุผลทางคณิตศาสตร์และการแก้ปัญหา
💻 4. ผู้ช่วยโค้ด
ความสามารถที่แข็งแกร่งในการสร้างโค้ดและความช่วยเหลือด้านการเขียนโปรแกรม
⚡ 5. ประสิทธิภาพทรัพยากร
การอนุมานที่รวดเร็วมากโดยใช้หน่วยความจำ GPU น้อยที่สุด เหมาะสำหรับการใช้งานจริง
❌ ไม่เหมาะสำหรับ
📚 คำถามเชิงข้อเท็จจริงที่ไม่มีบริบท
เนื่องจากเป็นแบบจำลองพารามิเตอร์ 4B อาจเกิดการหลอนเมื่อถูกถามเกี่ยวกับข้อเท็จจริงเฉพาะโดยไม่มีบริบทที่ให้ไว้ ควรใช้ร่วมกับ RAG หรือให้บริบทที่เกี่ยวข้องสำหรับคำถามเชิงข้อเท็จจริงเสมอ
🛠️ เริ่มต้นอย่างรวดเร็ว
การติดตั้ง
pip install transformers torch
การใช้งานพื้นฐาน
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "iapp/chinda-qwen3-4b"
# โหลด tokenizer และ model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# เตรียม input สำหรับ model
prompt = "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # เปิดโหมดคิดสำหรับการให้เหตุผลที่ดีขึ้น
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# สร้าง response
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
temperature=0.6,
top_p=0.95,
top_k=20,
do_sample=True
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# แยกเนื้อหาการคิด (หากเปิดใช้งาน)
try:
# หา token </think> (151668)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("🧠 คิด:", thinking_content)
print("💬 ตอบ:", content)
สลับระหว่างโหมดคิดและโหมดไม่คิด
เปิดใช้งานโหมดคิด (ค่าเริ่มต้น)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # เปิดใช้งานการให้เหตุผลโดยละเอียด
)
ปิดใช้งานโหมดคิด (เพื่อประสิทธิภาพ)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # โหมดตอบสนองรวดเร็ว
)
การใช้งาน API
ใช้ vLLM
pip install vllm>=0.8.5
vllm serve iapp/chinda-qwen3-4b --enable-reasoning --reasoning-parser deepseek_r1
ใช้ SGLang
pip install sglang>=0.4.6.post1
python -m sglang.launch_server --model-path iapp/chinda-qwen3-4b --reasoning-parser qwen3
ใช้ Ollama (ตั้งค่าง่ายๆ บนเครื่อง)
การติดตั้ง:
# ติดตั้ง Ollama (หากยังไม่ได้ติดตั้ง)
curl -fsSL https://ollama.com/install.sh | sh
# ดึงโมเดล Chinda LLM 4B
ollama pull iapp/chinda-qwen3-4b
การใช้งานพื้นฐาน:
# เริ่มแชทกับ Chinda LLM
ollama run iapp/chinda-qwen3-4b
# ตัวอย่างบทสนทนา
ollama run iapp/chinda-qwen3-4b "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
API Server:
# เริ่ม Ollama API server
ollama serve
# ใช้กับ curl
curl http://localhost:11434/api/generate -d '{
"model": "iapp/chinda-qwen3-4b",
"prompt": "สวัสดีครับ",
"stream": false
}'
ข้อมูลจำเพาะของโมเดล:
- ขนาด: 2.5GB ( quantized)
- Context Window: 40K tokens
- สถาปัตยกรรม: ปรับให้เหมาะสมสำหรับการติดตั้งในเครื่อง
- ประสิทธิภาพ: การอนุมานที่รวดเร็วบนฮาร์ดแวร์ทั่วไป
🔧 การกำหนดค่าขั้นสูง
การประมวลผลข้อความยาว
Chinda LLM 4B รองรับสูงสุด 32,768 โทเค็นโดยธรรมชาติ สำหรับบริบทที่ยาวขึ้น ให้เปิดใช้งาน YaRN scaling:
{
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
พารามิเตอร์ที่แนะนำ
สำหรับโหมดคิด:
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
- Min-P: 0
สำหรับโหมดไม่คิด:
- Temperature: 0.7
- Top-P: 0.8
- Top-K: 20
- Min-P: 0
📝 ความยาวบริบท & รูปแบบเทมเพลต
การรองรับความยาวบริบท
- ความยาวบริบทดั้งเดิม: 32,768 โทเค็น
- ความยาวบริบทขยาย: สูง��สุด 131,072 โทเค็น (พร้อม YaRN scaling)
- อินพุต + เอาต์พุต: ความยาวบทสนทนารวมที่รองรับ
- การใช้งานที่แนะนำ: เก็บการสนทนาไว้ต่ำกว่า 32K โทเค็นเพื่อประสิทธิภาพสูงสุด
รูปแบบ Chat Template
Chinda LLM 4B ใช้รูปแบบเทมเพลตแชทมาตรฐานสำหรับการโต้ตอบที่สอดคล้องกัน:
# โครงสร้างเทมเพลตพื้นฐาน
messages = [
{"role": "system", "content": "คุณเป็นผู้ช่วย AI ภาษาไทยที่มีประโยชน์"},
{"role": "user", "content": "สวัสดีครับ"},
{"role": "assistant", "content": "สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ"},
{"role": "user", "content": "ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย"}
]
# ใช้เทมเ�พลตพร้อมโหมดคิด
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
โครงสร้างเทมเพลต
เทมเพลตเป็นไปตามรูปแบบการสนทนามาตรฐาน:
<|im_start|>system
คุณเป็นผู้ช่วย AI ภาษาไทยที่มีประโยชน์<|im_end|>
<|im_start|>user
สวัสดีครับ<|im_end|>
<|im_start|>assistant
สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ<|im_end|>
<|im_start|>user
ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย<|im_end|>
<|im_start|>assistant
การใช้งานเทมเพลตขั้นสูง
# การสนทนาหลายรอบพร้อมการควบคุมการคิด
def create_conversation(messages, enable_thinking=True):
# เพิ่มข้อความระบบหากยังไม่มี
if not messages or messages[0]["role"] != "system":
system_msg = {
"role": "system",
"content": "คุณเป็น AI ผู้ช่วยที่ฉลาดและเป็นประโยชน์ พูดภาษาไทยได้อย่างเป็นธรรมชาติ"
}
messages = [system_msg] + messages
# ใช้ chat template
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=enable_thinking
)
return text
# ตัวอย่างการใช้งาน
conversation = [
{"role": "user", "content": "คำนวณ 15 × 23 = ?"},
]
prompt = create_conversation(conversation, enable_thinking=True)
การสลับโหมดแบบไดนามิก
คุณสามารถควบคุมโหมดคิดภายในบทสนทนาได้โดยใช้คำสั่งพิเศษ:
# เปิดใช้งานการคิดสำหรับปัญหาที่ซับซ้อน
messages = [
{"role": "user", "content": "/think แก้สมการ: x² + 5x - 14 = 0"}
]
# ปิดใช้งานการคิดสำหรับการตอบสนองอย่างรวดเร็ว
messages = [
{"role": "user", "content": "/no_think สวัสดี"}
]
แนวทางปฏิบัติที่ดีที่สุดในการจัดการบริบท
- ตรวจสอบจำนวนโทเค็น: ติดตามจำนวนโทเค็นทั้งหมด (อินพุต + เอาต์พุต)
- ตัดข้อความเก่า: ลบข้อความที่เก่าที่สุดเมื่อใกล้ถึงขีดจำกัด
- ใช้ YaRN สำหรับบริบทที่ยาว: เปิดใช้งาน rope scaling สำหรับเอกสาร > 32K โทเค็น
- การประมวลผลเป็นชุด: สำหรับข้อความที่ยาวมาก ให้พิจารณาแบ่งส่วนและประมวลผลเป็นชุด
def manage_context(messages, max_tokens=30000):
"""ฟังก์ชันจัดการบริบทอย่างง่าย"""
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
while total_tokens > max_tokens and len(messages) > 2:
# เก็บข้อความระบบและลบคู่ user/assistant ที่เก่าที่สุด
if messages[1]["role"] == "user":
messages.pop(1) # ลบข้อความ user
if len(messages) > 1 and messages[1]["role"] == "assistant":
messages.pop(1) # ลบคู่ข้อความ assistant ที่สอดคล้องกัน
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
return messages
🏢 การสนับสนุนองค์กร
สำหรับการใช้งานในองค์กร การฝึกอบรมแบบกำหนดเอง หรือการสนับสนุนเชิงพาณิชย์ โปรดติดต่อเราที่:
- อีเมล: sale@iapp.co.th
- เว็บไซต์: iapp.co.th
❓ คำถามที่พบบ่อย
🏷️ ทำไมถึงชื่อ "Chinda"?
ชื่อ "Chinda" (จินดา) มาจาก "จินดามณี" ซึ่งถือเป็นหนังสือเล่มแรกของประเทศไทยที่แต่งโดยพระโหราธิบดี (สมเด็จพระบรมราชาธิราชที่ 4) ในสมัยสุโขทัย เช่นเดียวกับที่จินดามณีเป็นรากฐานของวรรณคดีและการเรียนรู้ของไทย Chinda LLM เป็นรากฐานสำหรับ AI อธิปไตยของไทยของเรา - โมเดลที่เข้าใจและคิดเป็นภาษาไทยอย่างแท้จริง รักษาและพัฒนาความสามารถทางภาษาไทยในยุคดิจิทัล
⚖️ ฉันสามารถใช้ Chinda LLM 4B เพื่อการค้าได้หรือไม่?
ได้! Chinda LLM 4B เผยแพร่ภายใต้ ใบอนุญาต Apache 2.0 ซึ่งอนุญาตให้:
- ✅ การใช้งานเชิงพาณิชย์ - ใช้ในผลิตภัณฑ์และบริการเชิงพาณิชย์
- ✅ การใช้งานเพื่อการวิจัย - แอปพลิเคชันทางวิชาการและการวิจัย
- ✅ การดัดแปลง - ปรับและแก้ไขโมเดล
- ✅ การเผยแพร่ - แชร์และเผยแพร่โมเดลอีกครั้ง
- ✅ การใช้งานส่วนตัว - ใช้สำหรับโครงการภายในบริษัท
ไม่มีข้อจำกัดในการใช้งานเชิงพาณิชย์ - สร้างและใช้งานได้อย่างอิสระ!
🧠 ความแตกต่างระหว่างโหมดคิดและโหมดไม่คิดคืออะไร?
โหมดคิด (enable_thinking=True):
- โมเดลแสดงกระบวนการให้เหตุผลในบล็อก
<think>...</think> - เหมาะสำหรับปัญหาที่ซับซ้อน คณิตศาสตร์ การเขียนโค้ด การให้เหตุผลเชิงตรรกะ
- การตอบสนองช้ากว่าแต่แม่นยำกว่า
- แนะนำสำหรับงานที่ต้องการการวิเคราะห์เชิงลึก
โหมดไม่คิด (enable_thinking=False):
- คำตอบโดยตรงโดยไม่แสดงเหตุผล
- การตอบสนองที่รวดเร็วกว่าสำหรับการสนทนาทั่วไป
- เหมาะสำหรับคำถามง่ายๆ แล��ะแอปพลิเคชันแชท
- การใช้ทรัพยากรมีประสิทธิภาพมากขึ้น
คุณสามารถสลับระหว่างโหมดหรือให้ผู้ใช้ควบคุมแบบไดนามิกโดยใช้คำสั่ง /think และ /no_think
📊 Chinda LLM 4B เปรียบเทียบกับแบบจำลองภาษาไทยอื่นๆ อย่างไร?
Chinda LLM 4B บรรลุ ประสิทธิภาพโดยรวมดีกว่า 37% เมื่อเทียบกับทางเลือกที่ใกล้เคียงที่สุด:
- ค่าเฉลี่ยโดยรวม: 0.569 เทียบกับ 0.414 (ทางเลือก)
- คณิตศาสตร์ (MATH500): 0.908 เทียบกับ 0.702 (ภาษาอังกฤษ), 0.612 เทียบกับ 0.566 (ภาษาไทย)
- โค้ด (LiveCodeBench): 0.665 เทียบกับ 0.209 (ภาษาอังกฤษ), 0.198 เทียบกับ 0.144 (ภาษาไทย)
- ความแม่นยำภาษาไทย: 98.4% (ป้องกันการแสดงผลภาษาจีน/ภาษาต่างประเทศ)
- OpenThaiEval: 0.651 เทียบกับ 0.544
ปัจจุบันเป็น LLM ภาษาไทยที่มีคะแนนสูงสุดในกลุ่มพารามิเตอร์ 4B
💻 ข้อกำหนดระบบในการรัน Chinda LLM 4B คืออะไร?
ข้อกำหนดขั้นต่ำ:
- GPU: VRAM 8GB (RTX 3070/4060 Ti หรือดีกว่า)
- RAM: หน่วยความจำระบบ 16GB
- พื้นที่เก็บข้อมูล: พื้นที่ว่าง 8GB สำหรับดาวน์โหลดโมเดล
- Python: 3.8+ พร้อม PyTorch
แนะนำสำหรับการใช้งานจริง:
- GPU: VRAM 16GB+ (RTX 4080/A4000 หรือดีกว่า)
- RAM: หน่วยความจำระบบ 32GB+
- พื้นที่เก็บข้อมูล: SSD สำหรับการโหลดที่เร็วขึ้น
โหมด CPU เท่านั้น: ทำได้แต่จะช้าลงอย่างมาก (ไม่แนะนำสำหรับการใช้งานจริง)
🔧 ฉันสามารถ fine-tune Chinda LLM 4B สำหรับกรณีใช้งานเฉพาะของฉันได้หรือไม่?
ได้! ในฐานะที่เป็นโมเดลโอเพนซอร์สภายใต้ใบอนุญาต Apache 2.0 คุณสามารถ:
- Fine-tune บนข้อมูลเฉพาะโดเมนของคุณ
- ปรับแต่งสำหรับงานหรืออุตสาหกรรมที่เฉพาะเจาะจง
- แก้ไขสถาปัตยกรรมได้หากจำเป็น
- สร้างส่วนที่ได้สำหรับแอปพลิเคชันเฉพาะทาง
เฟรมเวิร์ก fine-tuning ยอดนิยมที่ใช้งานได้กับ Chinda:
- Unsloth - รวดเร็วและประหยัดหน่วยความจำ
- LoRA/QLoRA - การ fine-tuning ที่ประหยัดพารามิเตอร์
- Hugging Face Transformers - การ fine-tuning เต็มรูปแบบ
- Axolotl - การกำหนดค่าการฝึกขั้นสูง
ต้องการความช่วยเหลือในการ fine-tune? ติดต่อทีมงานของเราที่ sale@iapp.co.th
🌍 Chinda LLM 4B รองรับภาษาอะไรบ้าง?
ภาษาหลัก:
- ภาษาไทย - ความเข้าใจและการสร้างระดับภาษาแม่ (ความแม่นยำ 98.4%)
- ภาษาอังกฤษ - ประสิทธิภาพที่แข็งแกร่งในการทดสอบทั้งหมด
ภาษาเพิ่มเติม:
- รองรับ 100+ ��ภาษา (สืบทอดมาจาก Qwen3-4B พื้นฐาน)
- เน้นการปรับให้เหมาะสมสำหรับงานสองภาษาไทย-อังกฤษ
- การสร้างโค้ดในภาษาโปรแกรมต่างๆ
คุณสมบัติพิเศษ:
- การสลับภาษา (Code-switching) ระหว่างไทยและอังกฤษ
- การแปลระหว่างภาษาไทยและภาษาอื่น ๆ
- ความสามารถในการ ให้เหตุผลแบบหลายภาษา
🔍 ชุดข้อมูลการฝึกอบรมสามารถเข้าถึงได้แบบสาธารณะหรือไม่?
น้ำหนักของโมเดลเป็นโอเพนซอร์ส แต่ชุดข้อมูลการฝึกอบรมเฉพาะจะไม่ถูกเปิดเผยต่อสาธารณะ อย่างไรก็ตาม:
- โมเดลพื้นฐาน: สร้างบน Qwen3-4B (มูลนิธิโอเพนซอร์สของ Alibaba)
- การปรับภาษาไทย: การคัดเลือกชุดข้อมูลที่กำหนดเองสำหรับงานภาษาไทย
- เน้นคุณภาพ: เลือกเนื้อหาภาษาไทยคุณภาพสูงอย่างระมัดระวัง
- เป็นไปต�ามความเป็นส่วนตัว: ไม่มีข้อมูลส่วนบุคคลหรือข้อมูลที่ละเอียดอ่อนรวมอยู่
สำหรับการร่วมมือด้านการวิจัยหรือสอบถามเกี่ยวกับชุดข้อมูล โปรดติดต่อทีมวิจัยของเรา
🆘 ฉันจะรับการสนับสนุนหรือรายงานปัญหาได้อย่างไร?
สำหรับปัญหาทางเทคนิค:
- GitHub Issues: รายงานข้อบกพร่องและปัญหาทางเทคนิค
- Hugging Face: คำถามและข้อถกเถียงเกี่ยวกับโมเดลเฉพาะ
- เอกสาร: ตรวจสอบคู่มือฉบับสมบูรณ์ของเรา
สำหรับการสนับสนุนเชิงพาณิชย์:
- อีเมล: sale@iapp.co.th
- การสนับสนุนองค์กร: การฝึกอบรมแบบกำหนดเอง ความช่วยเหลือในการใช้งาน
- การให้คำปรึกษา: บริการบูรณาการและการปรับให้เหมาะสม
การสนับสนุนชุมชน:
- ชุมชน AI ภาษาไทย: เข้าร่วมการสนทนาเกี่ยวกับการพัฒนา AI ของไทย
- เว็บบอร์ดนักพัฒนา: เชื่อมต่อกับผู้ใช้ Chinda คนอื่น ๆ
📥 ขนาดการดาวน์โหลดโมเดลมีเท่าใดและอยู่ในรูปแบบใด?
ข้อมูลจำเพาะของโมเดล:
- พารามิเตอร์: 4.02 พันล้าน (4B)
- ขนาดดาวน์โหลด: ~8GB (บีบอัด)
- รูปแบบ: Safetensors (แนะนำ) และ PyTorch
- ความแม่นยำ: BF16 (Brain Float 16)
ตัวเลือกการดาวน์โหลด:
- Hugging Face Hub:
huggingface.co/iapp/chinda-qwen3-4b - Git LFS: สำหรับการรวมระบบควบคุมเวอร์ชัน
- ดาวน์โหลดโดยตรง: ไฟล์โมเดลรายไฟล์
- เวอร์ชัน Quantized: มีให้เลือกเพื่อลดการใช้หน่วยความจำ (GGUF, AWQ)
ตัวเลือก Quantization:
- 4-bit (GGUF): ~2.5GB, รันบน VRAM 4GB
- 8-bit: ~4GB, ประสิทธิภาพ/หน่วยความจำสมดุล
- 16-bit (ดั้ง��เดิม): ~8GB, ประสิทธิภาพเต็มที่
📚 การอ้างอิง
หากคุณใช้ Chinda LLM 4B ในงานวิจัยหรือโครงการของคุณ โปรดอ้างอิง:
@misc{chinda-llm-4b,
title={Chinda LLM 4B: Thai Sovereign AI Language Model},
author={iApp Technology},
year={2025},
publisher={Hugging Face},
url={https://huggingface.co/iapp/chinda-qwen3-4b}
}
สร้างสรรค์ด้วย 🇹🇭 โดย บริษัท ไอแอพพ์เทคโนโลยี จำกัด - เพิ่มพลังให้กับธุรกิจไทยด้วยความเป็นเลิศด้าน AI อธิปไตย
![]()
ขับเคลื่อนโดย บริษัท ไอแอพพ์เทคโนโลยี จำกัด