🇹🇭 Chinda Thai LLM 4B
最新模型,用泰语思考,用泰语回答,由泰国初创公司打造
Chinda Thai LLM 4B 是艾艾普科技 (iApp Technology) 的尖端泰语语言模型,为泰国人工智能生态系统带来了先进的思考能力。Chinda 基于最新的 Qwen3-4B 架构构建,体现了我们为泰国开发主权人工智能解决方案的承诺。
🚀 快速链接
- 🌐 演示: https://chindax.iapp.co.th (选择 ChindaLLM 4b)
- 📦 模型下载: https://huggingface.co/iapp/chinda-qwen3-4b
- 🐋 Ollama: https://ollama.com/iapp/chinda-qwen3-4b
- 📄 许可: Apache 2.0
📚 教程
- 使用 LM Studio 的 Chinda LLM 4B - 完整用户指南
- 使用 OpenWebUI 的 Chinda LLM 4B - 完整用户指南
- 使用 Ollama 的 Chinda LLM 4B - 完整用户指南
- 使用 n8n 的 Chinda LLM 4B - 完整工作流自动化指南
✨ 主要功能
🆓 0. 免费开源,人人可用
Chinda LLM 4B 完全免费且开源,使开发人员、研究人员和企业能够无限制地构建泰语人工智能应用程序。
🧠 1. 先进的思考模型
- 4B 类别中泰语 LLM 的最高得分
- 在思考模式和非思考模式之间无缝切换
- 卓越的推理能力,可解决复杂问题
- 可关闭以实现高效通用对话
🇹🇭 2. 出色的泰语准确性
- 泰语输出准确率达到 98.4%
- 防止不必要的中文和外语输出
- 专门针对泰语语言模式进行了微调
🆕 3. 最新架构
- 基于最先进的 Qwen3-4B 模型
- 整合了语言模型的最新进展
- 针对性能和效率进行了优化
📜 4. Apache 2.0 许可证
- 允许商业使用
- 允许修改和分发
- 私人使用无限制
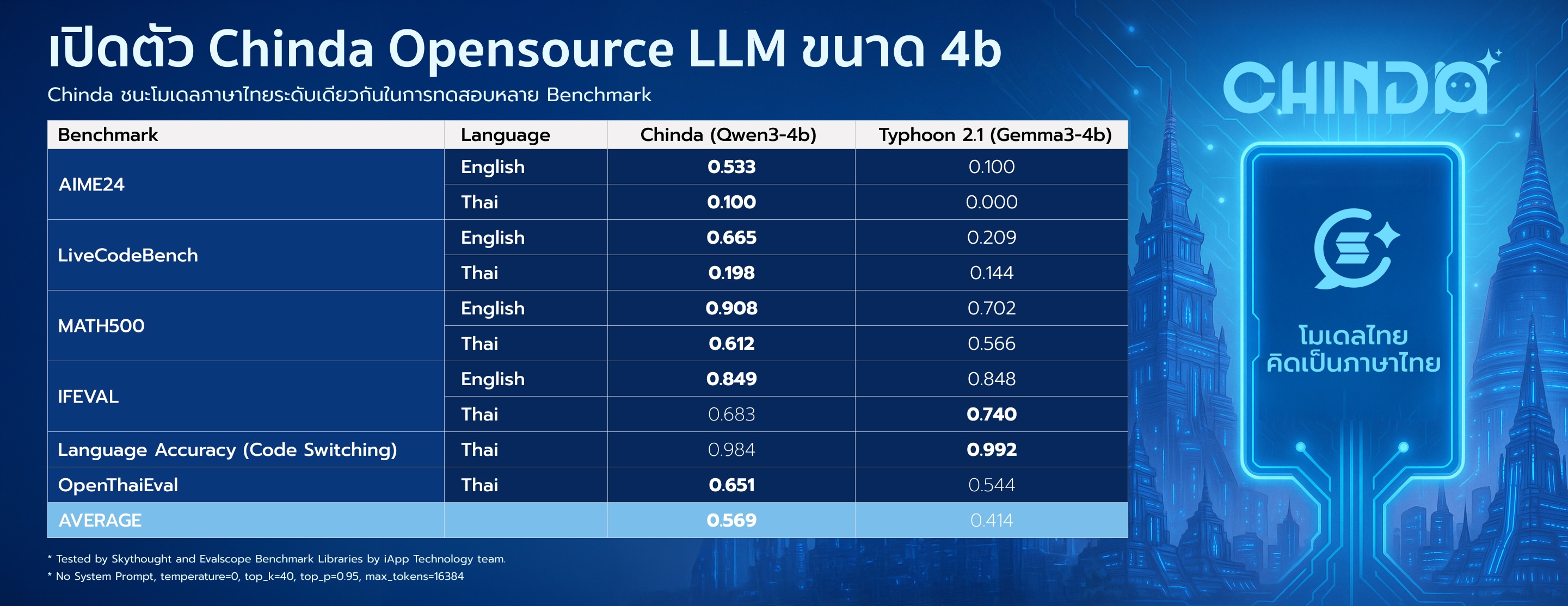
📊 基准测试结果
Chinda LLM 4B 在其所属类别中展现出优于其他泰语语言模型的性能:
| 基准测试 | 语言 | Chinda LLM 4B | 其他选项* |
|---|---|---|---|
| AIME24 | 英语 | 0.533 | 0.100 |
| 泰语 | 0.100 | 0.000 | |
| LiveCodeBench | 英语 | 0.665 | 0.209 |
| 泰语 | 0.198 | 0.144 | |
| MATH500 | 英语 | 0.908 | 0.702 |
| 泰语 | 0.612 | 0.566 | |
| IFEVAL | 英语 | 0.849 | 0.848 |
| 泰语 | 0.683 | 0.740 | |
| 语言准确性 | 泰语 | 0.984 | 0.992 |
| OpenThaiEval | 泰语 | 0.651 | 0.544 |
| 平均 | 0.569 | 0.414 |
- 其他选项: scb10x_typhoon2.1-gemma3-4b
由艾艾普科技 (iApp Technology) 团队使用 Skythought 和 Evalscope Benchmark Libraries 进行测试。结果显示 Chinda LLM 4B 的总体性能比最近的替代品高出 37%。
✅ 适用场景
🔍 1. RAG 应用 (主权 AI)
非常适合构建检索增强生成 (RAG) 系统,将数据处理保留在泰国主权范围内。
📱 2. 移动和笔记本电脑应用
可靠的小型语言模型,针对边缘计算和个人设备进行了优化。
🧮 3. 数学计算
在数学推理和解决问题方面表现出色。
💻 4. 代码助手
在代码生成和编程辅助方面具有强大的能力。
⚡ 5. 资源效率
推理速度非常快,GPU 内存消耗极少,非常适合生产部署。
❌ 不适用场景
📚 无上下文的事实性问题
作为一个 4B 参数模型,在被要求提供无上下文的具体事实时,可能会产生幻觉。请始终与 RAG 一起使用,或为事实查询提供相关上下文。
🛠️ 快速入门
安装
pip install transformers torch
基本用法
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "iapp/chinda-qwen3-4b"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 准备模型输入
prompt = "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 启用思考模式以获得更好的推理能力
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成响应
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
temperature=0.6,
top_p=0.95,
top_k=20,
do_sample=True
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思考内容(如果已启用)
try:
# 查找 </think> 标记 (151668)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("🧠 思考:", thinking_content)
print("💬 回复:", content)
在思考模式和非思考模式之间切换
启用思考模式(默认)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 启用详细推理
)
禁用思考模式(为了效率)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # 快速响应模式
)
API 部署
使用 vLLM
pip install vllm>=0.8.5
vllm serve iapp/chinda-qwen3-4b --enable-reasoning --reasoning-parser deepseek_r1
使用 SGLang
pip install sglang>=0.4.6.post1
python -m sglang.launch_server --model-path iapp/chinda-qwen3-4b --reasoning-parser qwen3
使用 Ollama(简单的本地设置)
安装:
# 如果尚未安装 Ollama,请安装
curl -fsSL https://ollama.com/install.sh | sh
# 拉取 Chinda LLM 4B 模型
ollama pull iapp/chinda-qwen3-4b
基本用法:
# 开始与 Chinda LLM 聊天
ollama run iapp/chinda-qwen3-4b
# 示例对话
ollama run iapp/chinda-qwen3-4b "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
API 服务器:
# 启动 Ollama API 服务器
ollama serve
# 使用 curl 进行调用
curl http://localhost:11434/api/generate -d '{
"model": "iapp/chinda-qwen3-4b",
"prompt": "สวัสดีครับ",
"stream": false
}'
模型规格:
- 大小: 2.5GB(量化后)
- 上下文窗口: 40K 令牌
- 架构: 针对本地部署进行了优化
- 性能: 在消费级硬件上实现快速推理
🔧 高级配置
处理长文本
Chinda LLM 4B 原生支持高达 32,768 个令牌。对于更长的上下文,请启用 YaRN 缩放:
{
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
推荐参数
用于思考模式:
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
- Min-P: 0
用于非思考模式:
- Temperature: 0.7
- Top-P: 0.8
- Top-K: 20
- Min-P: 0
📝 上下文长度和模板格式
上下文长度支持
- 原生上下文长度: 32,768 令牌
- 扩展上下文长度: 高达 131,072 令牌(使用 YaRN 缩放)
- 输入 + 输出: 支持的总对话长度
- 推荐用法: 为获得最佳性能,请将对话保持在 32K 令牌以下
聊天模板格式
Chinda LLM 4B 使用标准化的聊天模板格式以实现一致的交互:
# 基本模板结构
messages = [
{"role": "system", "content": "You are a helpful Thai AI assistant."},
{"role": "user", "content": "สวัสดีครับ"},
{"role": "assistant", "content": "สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ"},
{"role": "user", "content": "ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย"}
]
# 应用带思考模式的模板
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
模板结构
模板遵循标准的对话格式:
<|im_start|>system
You are a helpful Thai AI assistant.<|im_end|>
<|im_start|>user
สวัสดีครับ<|im_end|>
<|im_start|>assistant
สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ<|im_end|>
<|im_start|>user
ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย<|im_end|>
<|im_start|>assistant
高级模板用法
# 带思考控制的多轮对话
def create_conversation(messages, enable_thinking=True):
# 如果不存在,添加系统消息
if not messages or messages[0]["role"] != "system":
system_msg = {
"role": "system",
"content": "คุณเป็น AI ผู้ช่วยที่ฉลาดและเป็นประโยชน์ พูดภาษาไทยได้อย่างเป็นธรรมชาติ"
}
messages = [system_msg] + messages
# 应用聊天模板
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=enable_thinking
)
return text
# 用法示例
conversation = [
{"role": "user", "content": "คำนวณ 15 × 23 = ?"},
]
prompt = create_conversation(conversation, enable_thinking=True)
动态模式切换
您可以使用特殊命令在对话中控制思考模式:
# 为复杂问题启用思考
messages = [
{"role": "user", "content": "/think แก้สมการ: x² + 5x - 14 = 0"}
]
# 为快速响应禁用思考
messages = [
{"role": "user", "content": "/no_think สวัสดี"}
]
上下文管理最佳实践
- 监控令牌数: 跟踪总令牌数(输入 + 输出)
- 截断旧消息: 接近限制时删除最旧的消息
- 长上下文使用 YaRN: 对于大于 32K 令牌的文档,启用 rope 缩放
- 批量处理: 对于非常长的文本,请考虑分块并分批处理
def manage_context(messages, max_tokens=30000):
"""简单的上下文管理函数"""
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
while total_tokens > max_tokens and len(messages) > 2:
# 保留系统消息并删除最旧的用户/助手对
if messages[1]["role"] == "user":
messages.pop(1) # 删除用户消息
if len(messages) > 1 and messages[1]["role"] == "assistant":
messages.pop(1) # 删除对应的助手消息
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
return messages
🏢 企业支持
对于企业部署、定制培训或商业支持,请通过以下方式联系我们:
- 电子邮件: sale@iapp.co.th
- 网站: iapp.co.th
❓ 常见问题解答
🏷️ 为什么命名为“Chinda”?
“Chinda”(จินดา)这个名字来源于“Chindamani”(จินดามณี),被认为是泰国素可泰时期由 Phra Horathibodi(Sri Dharmasokaraja)撰写的首部书籍。正如 จินดามณี 是泰国文学和学习的奠基文本一样,Chinda LLM 代表了我们泰国主权 AI 的基础——一个真正理解并能用泰语思考的模型,在数字时代保存和提升泰语能力。
⚖️ 我可以将 Chinda LLM 4B 用于商业目的吗?
可以!Chinda LLM 4B 是在 Apache 2.0 许可证下发布的,该许可证允许:
- ✅ 商业用途 - 用于商业产品和服务
- ✅ 研究用途 - 学术和研究应用
- ✅ 修改 - 调整和修改模型
- ✅ 分发 - 分享和重新分发模型
- ✅ 私人用途 - 用于公司内部项目
商业应用无限制 - 自由构建和部署!
🧠 思考模式和非思考模式有什么区别?
思考模式 (enable_thinking=True):
- 模型在
<think>...</think>块中展示其推理过程 - 更适合解决复杂问题、数学、编码、逻辑推理
- 响应速度较慢但更准确
- 推荐用于需要深度分析的任务
非思考模式 (enable_thinking=False):
- 直接回答,不展示推理过程
- 适用于一般对话的快速响应
- 更适合简单查询和聊天应用
- 资源使用更高效
您可以通过 /think 和 /no_think 命令在模式之间切换,或让用户动态控制。
📊 Chinda LLM 4B 与其他泰语语言模型相比如何?
Chinda LLM 4B 的整体性能比最近的替代品高出 37%:
- 总体平均: 0.569 对比 0.414(其他选项)
- 数学 (MATH500): 0.908 对比 0.702(英语),0.612 对比 0.566(泰语)
- 代码 (LiveCodeBench): 0.665 对比 0.209(英语),0.198 对比 0.144(泰语)
- 泰语准确性: 98.4%(防止中文/外语输出)
- OpenThaiEval: 0.651 对比 0.544
目前它是4B 参数类别中得分最高的泰语 LLM。
💻 运行 Chinda LLM 4B 需要什么系统要求?
最低要求:
- GPU: 8GB VRAM (RTX 3070/4060 Ti 或更高)
- RAM: 16GB 系统内存
- 存储: 8GB 免费空间用于模型下载
- Python: 3.8+ 及 PyTorch
生产环境推荐:
- GPU: 16GB+ VRAM (RTX 4080/A4000 或更高)
- RAM: 32GB+ 系统内存
- 存储: SSD 以加快加载速度
仅 CPU 模式: 可能,但速度会慢很多(不推荐用于生产�环境)
🔧 我可以为我的特定用例微调 Chinda LLM 4B 吗?
可以!作为 Apache 2.0 许可证下的开源模型,您可以:
- 在您的领域特定数据上进行微调
- 定制以适应特定任务或行业
- 根据需要修改架构
- 为专业应用创建衍生模型
适用于 Chinda 的流行微调框架:
- Unsloth - 快速且内存高效
- LoRA/QLoRA - 参数高效微调
- Hugging Face Transformers - 完全微调
- Axolotl - 高级训练配置
需要微调方面的帮助?请联系我们的团队:sale@iapp.co.th
🌍 Chinda LLM 4B 支持哪些语言?
主要语言:
- 泰语 - 原生水平的理解和生成(98.4% 准确率)
- 英语 - 在所有基准测试中表现强劲
其他语言:
- 支持 100 多种语言(继承自 Qwen3-4B 基础模型)
- 重点优化泰语-英语双语任务
- 支持多种编程语言的代码生成
特殊功能:
- 泰语和英语之间的代码切换
- 泰语与其他语言之间的翻译
- 多语言推理能力
🔍 训练��数据是否公开?
模型权重是开源的,但具体的训练数据集并未公开。但是:
- 基础模型: 基于 Qwen3-4B(阿里巴巴的开源基础模型)
- 泰语优化: 定制数据集 curation,用于泰语任务
- 质量重点: 精心挑选的高质量泰语内容
- 符合隐私规定: 不包含个人或敏感数据
对于研究合作或数据集的咨询,请联系我们的研究团队。
🆘 如何获得支持或报告问题?
技术问题:
- GitHub Issues: 报告错误和技术问题
- Hugging Face: 模型特定问题和讨论
- 文档: 查看我们全面的指南
商业支持:
- 电子邮件: sale@iapp.co.th
- 企业支持: 定制培训、部署协助
- 咨询: 集成和优化服务
社区支持:
- 泰国 AI 社区: 加入关于泰国 AI 开发的讨论
- 开发者论坛: 与其他 Chinda 用户交流
📥 模型下载有多大,是什么格式?
模型规格:
- 参数: 40.2 亿 (4B)
- 下载大小: ~8GB(压缩后)
- 格式: Safetensors(推荐)和 PyTorch
- 精度: BF16 (Brain Float 16)
下载选项:
- Hugging Face Hub:
huggingface.co/iapp/chinda-qwen3-4b - Git LFS: 用于版本控制集成
- 直接下载: 单个模型文件
- 量化版本: 可用,以减少内存使用(GGUF, AWQ)
量化选项:
- 4 位 (GGUF): ~2.5GB,可在 4GB VRAM 上运行
- 8 位: ~4GB,性能/内存平衡
- 16 位(原始): ~8GB,完整性能
📚 引用
如果您在研究或项目中使用 Chinda LLM 4B,请引用:
@misc{chinda-llm-4b,
title={Chinda LLM 4B: Thai Sovereign AI Language Model},
author={iApp Technology},
year={2025},
publisher={Hugging Face},
url={https://huggingface.co/iapp/chinda-qwen3-4b}
}
由艾艾普科技 (iApp Technology) 在 🇹🇭 建造 - 以主权 AI 卓越赋能泰国企业
![]()
由艾艾普科技 (iApp Technology) 提供支持