ฝึกสอน LoRA Adaptor
ปรับแต่งโมเดลภาษาขนาดใหญ่อย่างมีประสิทธิภาพโดยฝึกสอนเพียงเศษเสี้ยวของพารามิเตอร์ LoRA ให้��ผลลัพธ์ที่น่าประทับใจด้วยต้นทุนและเวลาที่น้อยกว่า Full Finetuning อย่างมาก
เริ่มต้นใช้งาน
LoRA คืออะไร?
LoRA (Low-Rank Adaptation) คือเทคนิค Finetuning ที่มีประสิทธิภาพในการใช้พารามิเตอร์ โดยจะแช่แข็งน้ำหนักเดิมของโมเดลและฉีดเมทริกซ์ Low-Rank ขนาดเล็กที่สามารถฝึกสอนได้เข้าสู่ชั้น Attention ของโมเดล แทนที่จะอัปเดตพารามิเตอร์หลายพันล้านตัว LoRA ฝึกสอนเพียง 0.1-1% ของพารามิเตอร์ทั้งหมด แต่ให้ประสิทธิภาพเทียบเท่า Full Finetuning
แนวคิดสำคัญคือการอัปเดตน้ำหนักระหว่าง Finetuning มี Intrinsic Rank ต่ำ โดยการแยกการเปลี่ยนแปลงน้ำหนักเป็นเมทริกซ์ขนาดเล็กสองตัว (A และ B) โดยที่ W = W₀ + BA LoRA ช่วยลดความต้องการหน่วยความจำและเวลาฝึกสอนลงอย่างมาก LoRA Adaptor หลายตัวสามารถสลั��บใช้งานได้ในขั้นตอน Inference ทำให้โมเดลพื้นฐานเดียวสามารถให้บริการได้หลายงาน
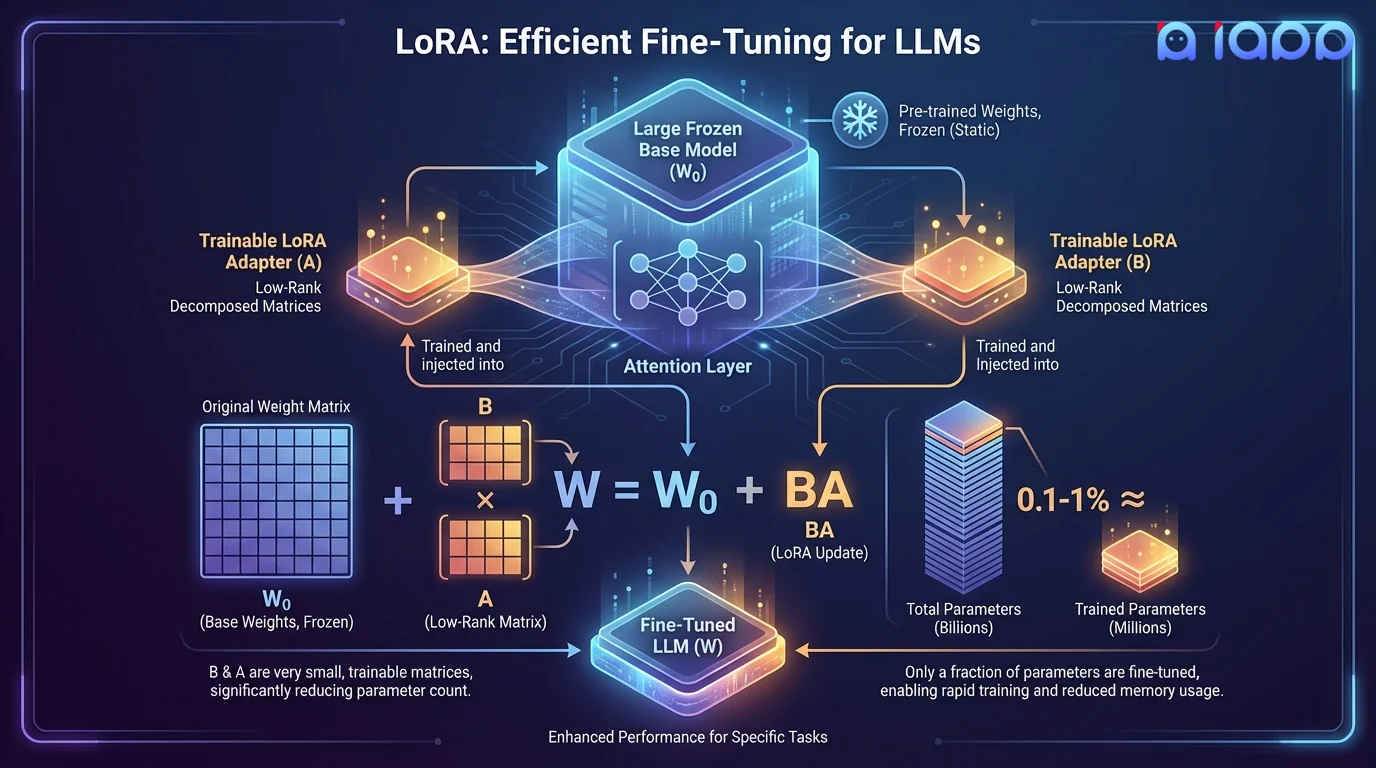
ขั้นตอนการทำงาน
ปรับแต่งอย่างมีประสิทธิภาพโดยไม่ต้องแก้ไขโมเดลพื้นฐาน
กำหนดงาน
กำหนดงานเป้าหมายและเตรียมคู่ข้อมูลคำสั่ง-คำตอบสำหรับฝึกสอน
เลือก Rank
เลือก LoRA Rank (r) และโมดูลเป้าหมายที่เหมาะสมตามความซับซ้อนของงาน
ฝึกสอน Adaptor
ฝึกสอนเมทริกซ์ Adaptor น้ำหนักเบาด้วยข้อมูลของคุณ พร้อมรอบการปรับปรุงที่รวดเร็ว
รวมหรือสลับ
รวม Adaptor เข้ากับโมเดลพื้นฐานสำหรับการ Deploy หรือแยกไว้สำหรับการให้บริการหลายงาน
ข้อได้เปรียบสำคัญ
ฝึกสอนเร็วขึ้น 10 เท่า
ฝึกสอนเสร็จในหลักชั่วโมงแทนที่จะเป็นวัน พารามิเตอร์ที่น้อยของ LoRA ช่วยให้ทดลองและปรับปรุงโมเดลได้อย่างรวดเร็ว
คุ้มค่าต้นทุน
ลดความต้องการหน่วยความจำ GPU และพลังประมวลผลอย่างมาก ฝึกสอนโมเดล 70B+ พารามิเตอร์ได้บนโหนดเดียว
สลับ Adaptor ได้ทันที
โหลด LoRA Adaptor ต่างๆ ได้ในขั้นตอน Inference โมเดลพื้นฐานเดียวสามารถให้บริการลูกค้า แปลภาษา เขียนโค้ด และอื่นๆ
ประสิทธิภาพใกล้เคียง Full-FT
ได้คุณภาพ 95-100% ของ Full Finetuning ด้วย QLoRA (Quantized LoRA) เพื่อประสิทธิภาพที่ดียิ่งขึ้น
กรณีการใช้งาน
เหมาะอย่างยิ่งสำหรับการปรับแต่งอย่างรวดเร็วและการ Deploy แบบหลายผู้ใช้
SaaS หลายผู้เช่า
ให้บริการลูกค้าแต่ละรายด้วยพฤติกรรมโมเดลที่ปรับแต่งเฉพาะ โดยใช้ LoRA Adaptor แยกกันบนโมเดลพื้นฐานร่วม
สร้างต้นแบบอย่างรวดเร็ว
ทดสอบสมมติฐานและปรับปรุงพฤติกรรมโมเดลอย่างรวดเร็ว โดยไม่ต้องเสียต้นทุนและเวลาของ Full Finetuning
โมเดลหลายงาน
สร้าง Adaptor เฉพาะทางสำหรับการแปลภาษา สรุปความ จำแนกประเภท และอื่นๆ บนโมเดลพื้นฐานเดียว
ใช้งานบนอุปกรณ์ Edge
เก็บโมเดลพื้นฐานไว้บนอุปกรณ์และสลับ LoRA Adaptor ขนาดเล็ก (ไม่กี่ MB) สำหรับฟังก์ชันการทำงานที่แตกต่างกัน
ปรับแต่งภาษา
เพิ่มความสามารถทางภาษาใหม่ให้โมเดลพื้นฐานใดๆ ด้วย LoRA Adaptor น้ำหนักเบา โดยไม่ทำให้ประสิทธิภาพภาษาเดิมลดลง
ทดสอบ A/B โมเดล
ฝึกสอน LoRA หลายเวอร์ชันด้วยข้อมูลหรือ Hyperparameter ที่แตกต่างกัน และทดสอบ A/B ในการใช้งานจริงเพื่อหาพฤติกรรมโมเดลที่ดีที่สุด
ทำไมต้องเลือก iApp Technology?
บริษัท AI ชั้นนำของประเทศไทยที่มีความเชี่ยวชาญด้าน LLM
โครงสร้างพื้นฐานระดับโลก
เราดำเนินการซูเปอร์คอมพิวเตอร์ NVIDIA H100, B200 และ GB200 โครงสร้างพื้นฐานของเรารองรับการฝึกสอน LoRA, QLoRA และ DoRA บนโมเดลขนาดสูงสุด 400B+ พารามิเตอร์
ผลงานที่พิสูจน์แล้ว
เราคือผู้สร้าง LLM ที่ใช้งานจริงในระดับองค์กร ได้รับความไว้วางใจจากองค์กรทั่วประเทศไทยและเอเชียตะวันออกเฉียงใต้
ราคา
ราคาตามโปรเจกต์
การฝึกสอน LoRA มีความคุ้มค่ากว่า Full Finetuning อย่างมาก ราคาขึ้นอยู่กับขนาดโมเดลพื้นฐาน จำนวน Adaptor และปริมาณข้อมูลฝึกสอน
- ✓ ปรึกษาเบื้องต้นและประเมินงานฟรี
- ✓ ราคาโปร่งใส ไม่มีค่าใช้จ่ายแอบแฝง
- ✓ ส่งมอบรวดเร็ว - เป็นวัน ไม่ใช่สัปดาห์
- ✓ รวมการสนับสนุนหลังส่งมอบ