Teacher-Student Model Distillation
บีบอัดความฉลาดของโมเดล Teacher ขนาดใหญ่ลงในโมเดล Student ที่เล็กกว่าและเร็วกว่า ได้ประส�ิทธิภาพ 90%+ ด้วยขนาดและต้นทุนที่น้อยลงหลายเท่า
เริ่มต้นใช้งาน
Model Distillation คืออะไร?
Knowledge Distillation คือกระบวนการถ่ายทอดความรู้จากโมเดล "Teacher" ขนาดใหญ่ที่มีประสิทธิภาพสูง ไปยังโมเดล "Student" ที่เล็กกว่าและมีประสิทธิภาพมากกว่า โมเดล Student ไม่เพียงเรียนรู้จาก Hard Label เท่านั้น แต่ยังเรียนรู้จาก Soft Probability Distribution ของ Teacher ที่ครอบคลุมผลลัพธ์ที่เป็นไปได้ทั้งหมด ซึ่งจับรูปแบบและความสัมพันธ์ที่ละเอียดอ่อนที่ Teacher ได้เรียนรู้
ตัวอย่างเช่น ความฉลาดของโมเดล Teacher ขนาด 70B พารามิเตอร์ สามารถกลั่นกรองลงในโมเดล Student ขนาด 7B ที่ทำงานเร็วกว่า 10 เท่า ใช้หน่วยความจำน้อยกว่า 10 เท่า และต้นทุนการให้บริการต่ำกว่า 10 เท่า ในขณะที่ยั��งคงคุณภาพ 90-95% ของ Teacher นี่คือเทคนิคเบื้องหลังโมเดลอย่าง Llama 3.2 1B/3B และ Gemma 2 2B
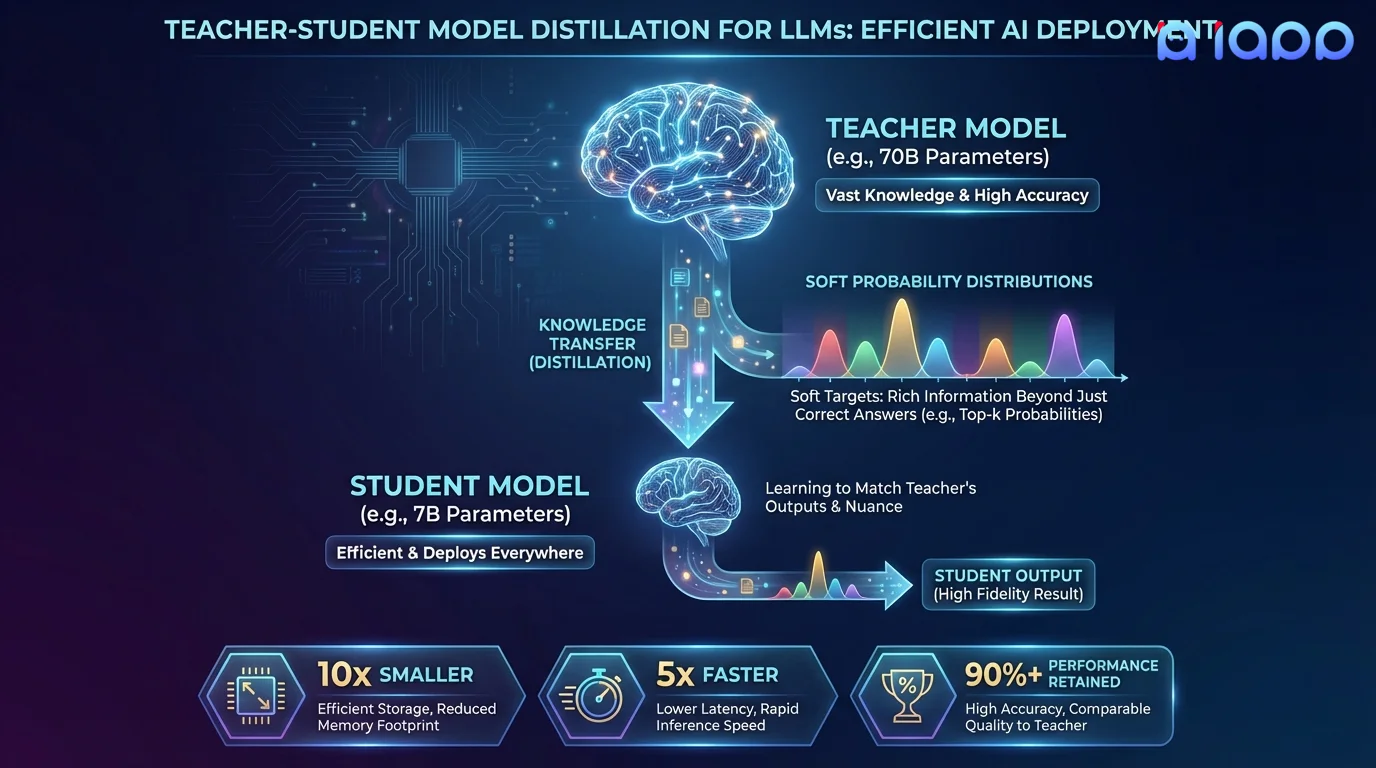
วิธีการทำงาน
จากโมเดล Teacher ขนาดใหญ่สู่โมเดล Student ที่มีประสิทธิภาพ
เลือกโมเดล Teacher
เลือกหรือฝึกโมเดล Teacher ที่เป็นตัวแทนเป้าหมายคุณภาพของคุณ
สถาปัตยกรรม Student
ออกแบบสถาปัตยกรรมโมเดล Student ที่เหมาะสมกับข้อจำกัดในการ Deploy ของคุณ
สร้างข้อมูล
สร้างข้อมูลฝึกจาก Teacher รวมถึง Soft Label และร่องรอยการให้เหตุผล
ฝึก Distillation
ฝึก Student ให้ตรงกับการกระจายผลลัพธ์ของ Teacher โดยใช้ KL Divergence Loss
ตรวจสอบคุณภาพ
ทดสอบ Student เทียบกับ Teacher ด้ว��ยชุดการประเมินของคุณ
ข้อดีหลัก
Inference เร็วขึ้น 10 เท่า
โมเดลที่เล็กกว่าสร้างโทเค็นได้เร็วกว่ามาก ลดเวลาตอบสนองจากหลายวินาทีเหลือมิลลิวินาทีสำหรับแอปพลิเคชันแบบเรียลไทม์
ต้นทุนต่ำกว่า 10 เท่า
ให้บริการผู้ใช้มากขึ้น 10 เท่าบนฮาร์ดแวร์เดียวกัน ลดค่า GPU ได้อย่างมากสำหรับการ Deploy ที่มีปริมาณสูง
Deploy บน Edge
Deploy โมเดลบนอุปกรณ์มือถือ Edge Server และสภาพแวดล้อมที่มีทรัพยากรจำกัดที่โมเดลขนาดใหญ่ไม่สามารถทำงานได้
คงคุณภาพไว้ 90%+
โมเดล Student ยังคงความสามารถส่วนใหญ่ของ Teacher ไว้ได้ การแลกเปลี่ยนระหว่างคุณภาพและประสิทธิภาพนั้นคุ้มค่าอย่างมาก
กรณีการใช้งาน
เมื่อคุณต้องการคุณภาพระดับ Teacher ในต้นทุนระดับ Student
ลดต้นทุนการใช้งานจริง
แทนที่โมเดลขนาด 70B+ ที่มีราคาแพงด้วยโมเดลที่ผ่าน Distillation ขนาด 7-8B ที่ให้คุณภาพเทียบเคียงได้ในต้นทุนที่ต่ำกว่า 10 เท่า
แอปพลิเคชัน AI บนมือถือ
กลั่นกรองโมเดลบนคลาวด์ลงในโมเดลขนาด 1-3B ที่ทำงานบนสมาร์ทโฟนได้โดยตรง สำหรับฟีเจอร์ AI ที่ใช้งานออฟไลน์ได้
แอปพลิเคชันแบบเรียลไทม์
ให้เวลาตอบสนองต่ำกว่า 100 มิลลิวินาที สำหรับแชทบอท การเติมข้อความอัตโนมัติ และฟีเจอร์ AI แบบโต้ตอบที่ต้องการผลตอบรับทันที
บีบอัดโมเดลที่เป็นกรรมสิทธิ์
กลั่นกรองความสามารถของโมเดลขนาดใหญ่ที่เป็นกรรมสิทธิ์ลงในโมเดลที่เล็กกว่า เพื่อแจกจ่ายให้พาร์ทเนอร์หรือลูกค้า
รวมหลายโมเดลเป็นหนึ่ง
รวมจุดแข็งของโมเดล Teacher เฉพาะทางหลายตัวเข้าเป็นโมเดล Student อเนกประสงค์ตัวเดียวที่จัดการงานทั้งหมดของคุณ
ลดต้นทุน API
กลั่นกรองโมเดล API ที่มีราคาแพง (GPT-4, Claude) ลงในโมเดลของคุณเองที่โฮสต์เอง ลดค่าใช้จ่าย API ต่อโทเค็นในระดับใหญ่
ทำไมต้องเลือก iApp Technology?
บริษัท AI ชั้นนำของประเทศไทยที่มีความเชี่ยวชาญด้าน LLM ที่พิสูจน์แล้ว
โครงสร้างพื้นฐานระดับโลก
เราดำเนินการซูเปอร์คอมพิวเตอร์ NVIDIA H100, B200 และ GB200 Distillation ต้องการรันทั้งโมเดล Teacher และ Student พร้อมกัน และโครงสร้างพื้นฐานของเราสามารถรองรับได้ในระดับใหญ่
ผลงานที่พิสูจน์แล้ว
เราเป็นผู้สร้าง LLM สำหรับใช้งานจริงที่ได้รับความไว้วางใจจากองค์กรทั่วประเทศไทยและเอเชียตะวันออกเฉียงใต้
ราคา
ราคาตามโปรเจกต์
ราคา Distillation ขึ้นอยู่กับขนาดโมเดล Teacher ขนาดเป้าหมายของ Student ปริมาณข้อมูลฝึก และข้อกำหนดการคงคุณภาพ
- ✓ ให้คำปรึกษาเบื้องต้นและวิเคราะห์ความเป็นไปได้ฟรี
- ✓ ราคาโปร่งใสไม่มีค่าใช้จ่ายแอบแฝง
- ✓ รับประกันการคงคุณภาพ
- ✓ สนับสนุนและปรับปรุงหลังส่งมอบ