Reinforcement Learning: DPO, GRPO และ PPO
ปรับแต่งโมเดลภาษาให้สอดคล้องกับความต้องการของมนุษย์ เราใช้เทคนิค Reinforcement Learning ล่าสุดเพื่อ��ทำให้ LLM ของคุณเป็นประโยชน์ ปลอดภัย และซื่อสัตย์
เริ่มต้นใช้งาน
RLHF คืออะไร?
Reinforcement Learning from Human Feedback (RLHF) คือกระบวนการฝึกสอนโมเดลภาษาให้ปรับผลลัพธ์ให้สอดคล้องกับความต้องการของมนุษย์ หลังจาก Supervised Finetuning แล้ว RLHF เป็นขั้นตอนสำคัญที่เปลี่ยนโมเดลจากการสร้างข้อความที่ดูสมเหตุสมผล ไปสู่การสร้างผลลัพธ์ที่เป็นประโยชน์ ปลอดภัย และสอดคล้องกับพฤติกรรมที่คุณต้องการ
เรานำเสนอวิธี Alignment ล่าสุดสามวิธี: PPO (วิธีคลาสสิกที่ ChatGPT ใช้), DPO (ทางเลือกที่ง่ายกว่าและเสถียรกว่า) และ GRPO (นวัตกรรมล่าสุดจาก DeepSeek ที่ไม่ต้องใช้ Reward Model แยกต่างหาก)
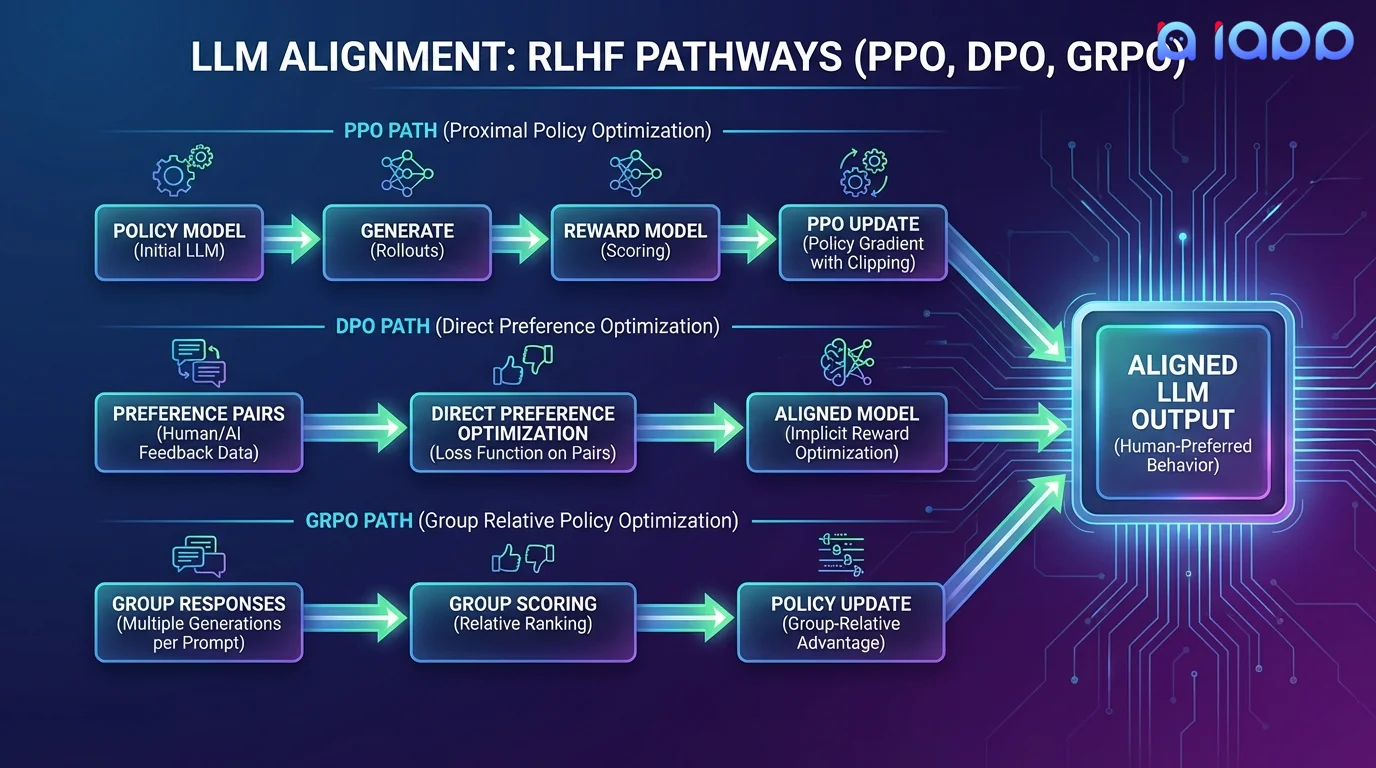
วิธี Alignment สามแบบ
เลือกแนวทางที่เหมาะสมกับความต้องการ Alignment ของคุณ
DPO - Direct Preference Optimization
DPO ไม่ต้องใช้ Reward Model แยกต่างหาก โดยจะ Optimize Policy โดยตรงด้วยคู่ความชอบ (คำตอบที่เลือก vs คำตอบที่ปฏิเสธ) ง่ายในการนำไปใช้ การฝึกสอนมีเสถียรภาพมากกว่า และมักให้ผลลัพธ์เทียบเท่าหรือดีกว่า PPO เหมาะอย่างยิ่งเมื่อคุณมีข้อมูลความชอบที่ชัดเจน
GRPO - Group Relative Policy Optimization
พัฒนาโดย DeepSeek, GRPO สร้างคำตอบหลายรายการต่อหนึ่งคำถาม และใช้คะแนนเปรียบเทียบภายในกลุ่มเพื่อ Optimize Policy ไม่ต้องใช้ Reward Model กระตุ้นการสำรวจและความหลากหลายโดยธรรมชาติ เหมาะอย่างยิ่งสำหรับงานการให้เหตุผลและคณิตศาสตร์ เทคนิคเบื้องหลัง DeepSeek-R1
PPO - Proximal Policy Optimization
วิธี RLHF คลาสสิกที่ ChatGPT และโมเดลชั้นนำหลายตัวใช้ PPO ฝึกสอน Reward Model แยกจากความชอบของมนุษย์ จากนั้น Optimize Policy ของ LLM ด้วยสัญญาณรางวัล เป็นวิธีที่ยืดหยุ่นที่สุด รองรับ Reward Shaping ที่ซับซ้อนและ Multi-Objective Optimization
ขั้นตอนการทำงาน
กระบวนการ Alignment ของเราจากข้อมูลความชอบสู่โมเดลที่ปรับแต่งแล้ว
รวบรวมข้อมูลความชอบ
รวบรวมข้อมูลความชอบของมนุษย์: คู่คำตอบที่เลือก/ปฏิเสธ หรือการจัดอันดับคำตอบของโมเดล
เลือกวิธีการ
เลือก DPO, GRPO หรือ PPO ตามข้อมูล วัตถุประสงค์ และความต้องการประสิทธิภาพของคุณ
ฝึกสอน Alignment
ฝึกสอนโมเดลเพื่อเพิ่ม Alignment กับความชอบของมนุษย์ให้สูงสุด โดยรักษาความสามารถเดิมไว�้
ประเมินความปลอดภัย
ทดสอบความปลอดภัยและ Alignment อย่างครอบคลุมเพื่อยืนยันว่าโมเดลเป็นไปตามมาตรฐานของคุณ
ปรับปรุงซ้ำ
ปรับ Alignment ผ่านหลายรอบจนกว่าจะได้พฤติกรรมเป้าหมาย
กรณีการใช้งาน
Alignment เป็นสิ่งจำเป็นสำหรับการ Deploy LLM ที่ให้บริการลูกค้าทุกกรณี
ความปลอดภัยของแชทบอท
ทำให้แชทบอทของคุณปฏิเสธคำขอที่เป็นอันตราย หลีกเลี่ยงการสร้างเนื้อหาที่ไม่เหมาะสม และอยู่ในขอบเขตของกรณีการใช้งานธุรกิจ
ปรับโทนเสียงและสไตล์
ฝึกสอนโมเดลให้สื่อสารในเสียงของแบรนด์คุณ - เป็นทางการ เป็นกันเอง เชิงเทคนิค หรือสบายๆ - อย่างสม่ำเสมอในทุกการโต้ตอบ
เสริมการให้เหตุผล
ใช้ GRPO เพื่อปรับปรุง Chain-of-Thought Reasoning การแก้ปัญหาคณิตศาสตร์ และความสามารถในการอนุมานเชิงตรรกะ
ปฏิบัติตามกฎระเบียบ
ปรับผลลัพธ์ของโมเดลให้สอดคล้องกับกฎระเบียบของอุตสาหกรรม เพื่อให้คำตอบเป็นไปตามข้อกำหนดทางการเงิน การแพทย์ หรือกฎหมาย
ลดการสร้างข้อมูลเท็จ
ใช้การฝึกสอนด้วยความชอบเพื่อลงโทษข้อมูลที่แต่งขึ้น สอนให้โมเดลบอกว่า "ไม่ทราบ" แทนที่จะสร้างคำตอบที่ฟังดูสมเหตุสมผลแต่ไม่ถูกต้อง
ทำตามคำสั่งได้แม่นยำ
ปรับปรุงความสามารถของโมเดลในการทำตามคำสั่งที่ซับซ้อนและมีหลายขั้นตอนอย่างแม่นยำ โดยไม่เบี่ยงเบน ข้ามขั้นตอน หรือเพิ่มรายละเอียดที่ไม่จำเ�ป็น
ทำไมต้องเลือก iApp Technology?
บริษัท AI ชั้นนำของประเทศไทยที่มีความเชี่ยวชาญด้าน LLM
โครงสร้างพื้นฐานระดับโลก
การฝึกสอน RLHF ต้องใช้พลังประมวลผลสูง เราดำเนินการซูเปอร์คอมพิวเตอร์ NVIDIA H100, B200 และ GB200 ที่รองรับการฝึกสอนหลายโมเดลของ PPO การสร้างคำตอบหลายรายการของ GRPO และ Optimization ขนาดใหญ่ของ DPO ได้อย่างง่ายดาย
ผลงานที่พิสูจน์แล้ว
เราคือผู้สร้าง LLM ที่ใช้งานจริงในระดับองค์กร ได้รับความไว้วางใจจากองค์กรทั่วประเทศไทยและเอเชียตะวันออกเฉียงใต้
ราคา
ราคาตามโปรเจกต์
ราคา RLHF ขึ้นอยู่กับวิธี Alignment ที่เลือก ปริมาณข้อมูลความชอบ ขนาดโมเดล และจำนวนรอบการฝึกสอนที่ต้องการ
- ✓ ปรึกษาเบื้องต้นและวางกลยุทธ์ Alignment ฟรี
- ✓ แนะนำการรวบรวมข้อมูลความชอบ
- ✓ รวมการปรับปรุงหลายรอบ
- ✓ รายงานประเมินความปลอดภัยอย่างครอบคลุม