Reinforcement Learning: DPO, GRPO & PPO
Align your language model with human preferences. We use state-of-the-art reinforcement learning techniques to make your LLM helpful, harmless, and honest.
Get Started
What is RLHF?
Reinforcement Learning from Human Feedback (RLHF) is the process of training a language model to align its outputs with human preferences. After supervised finetuning, RLHF is the critical step that transforms a model from merely generating plausible text to producing outputs that are helpful, safe, and aligned with your desired behavior.
We offer three state-of-the-art alignment methods: PPO (the classical approach used by ChatGPT), DPO (a simpler, more stable alternative), and GRPO (the latest breakthrough from DeepSeek that eliminates the need for a separate reward model).
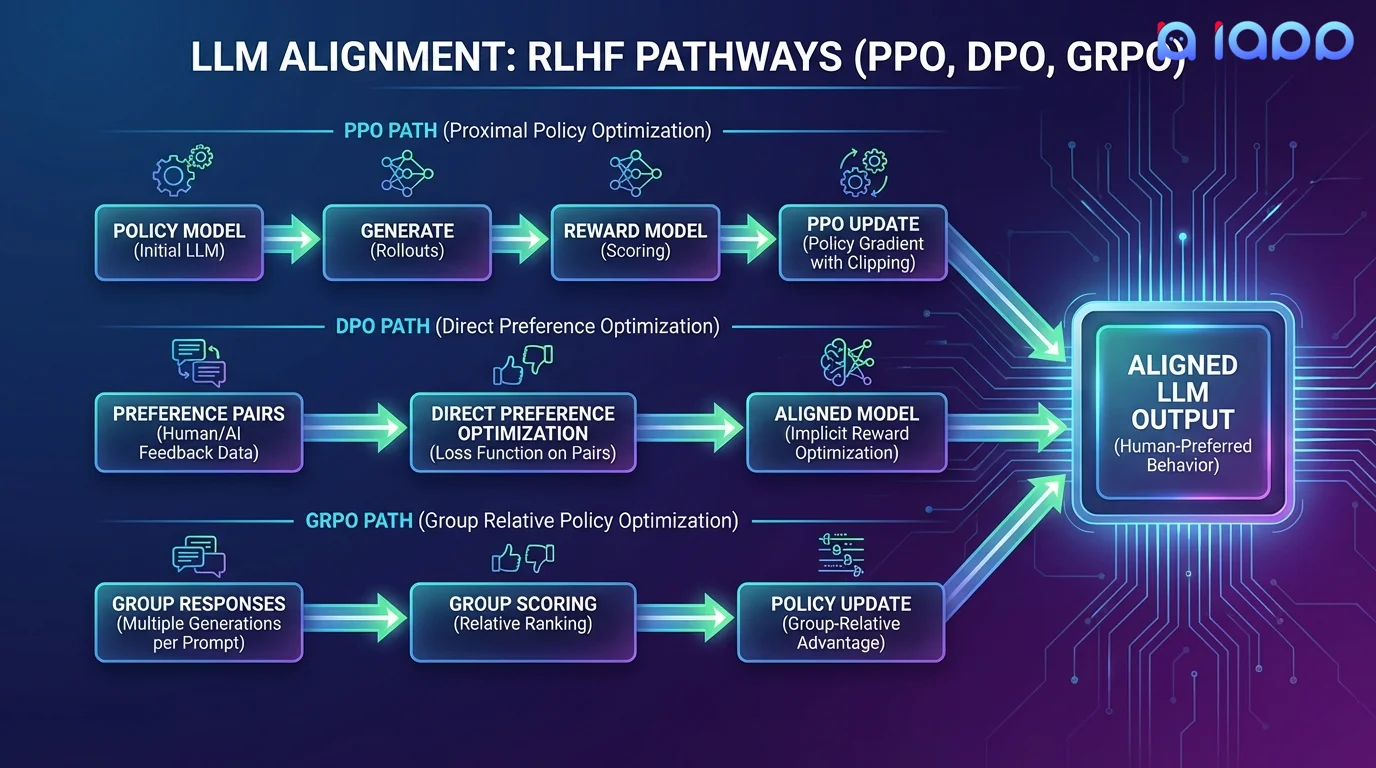
Three Alignment Methods
Choose the right approach for your alignment needs
DPO - Direct Preference Optimization
DPO eliminates the need for a separate reward model. It directly optimizes the policy using preference pairs (chosen vs. rejected responses). Simpler to implement, more stable training, and often achieves comparable or better results than PPO. Ideal when you have clear preference data.
GRPO - Group Relative Policy Optimization
Developed by DeepSeek, GRPO generates multiple responses per prompt and uses group-relative scoring to optimize the policy. No reward model needed. It naturally encourages exploration and diversity, making it excellent for reasoning and math tasks. The technique behind DeepSeek-R1.
PPO - Proximal Policy Optimization
The classical RLHF approach used by ChatGPT and many leading models. PPO trains a separate reward model from human preferences, then optimizes the LLM policy using the reward signal. Most flexible approach, supports complex reward shaping and multi-objective optimization.
How It Works
Our alignment pipeline from preference data to aligned model
Preference Collection
Collect human preference data: chosen/rejected pairs or ranking of model responses
Method Selection
Choose DPO, GRPO, or PPO based on your data, objectives, and performance requirements
Alignment Training
Train the model to maximize alignment with human preferences while preserving capabilities
Safety Evaluation
Comprehensive safety and alignment benchmarks to verify the model meets your standards
Iteration
Refine alignment through multiple rounds until target behavior is achieved
Use Cases
Alignment is critical for any customer-facing LLM deployment
Chatbot Safety
Ensure your chatbot refuses harmful requests, avoids generating inappropriate content, and stays on-topic for your business use case.
Tone & Style Alignment
Train your model to communicate in your brand voice - professional, friendly, technical, or casual - consistently across all interactions.
Reasoning Enhancement
Use GRPO to improve chain-of-thought reasoning, mathematical problem-solving, and logical deduction capabilities.
Regulatory Compliance
Align model outputs with industry regulations, ensuring responses comply with financial, medical, or legal requirements.
Hallucination Reduction
Use preference training to penalize fabricated information, teaching the model to say "I don't know" rather than generating plausible-sounding but false answers.
Instruction Following
Improve the model's ability to follow complex, multi-step instructions precisely without deviating, omitting steps, or adding unwanted elaboration.
Why Choose iApp Technology?
Thailand's leading AI company with proven LLM expertise
World-Class Infrastructure
RLHF training is compute-intensive. We operate NVIDIA H100, B200, and GB200 supercomputers that handle PPO's multi-model training, GRPO's multi-response generation, and DPO's large-batch optimization with ease.
Proven Track Record
We are the makers of production LLMs trusted by enterprises across Thailand and Southeast Asia.
Pricing
Project-Based Pricing
RLHF pricing depends on the alignment method chosen, preference data volume, model size, and number of training iterations required.
- ✓ Free initial consultation and alignment strategy
- ✓ Preference data collection guidance
- ✓ Multiple iteration rounds included
- ✓ Comprehensive safety evaluation report