On-Policy Context Distillation (OPCD)
Distill complex system prompts, few-shot examples, and chain-of-thought reasoning directly into the model's weights. Your model learns to behave as if it always has the perfect context.
Get Started
What is Context Distillation?
Context Distillation is the process of training a model to internalize the behavior induced by a specific context (system prompt, few-shot examples, or chain-of-thought instructions) so that it produces the same high-quality outputs without needing that context at inference time.
On-Policy Context Distillation (OPCD) takes this further by using the model's own generations (on-policy) rather than static datasets. The model generates responses with the rich context, then learns to reproduce those same responses without the context. This approach is more effective because the training data matches the model's actual output distribution.
The result: faster inference (no long system prompts), lower token costs, more consistent behavior, and the ability to embed complex reasoning patterns into the model itself.
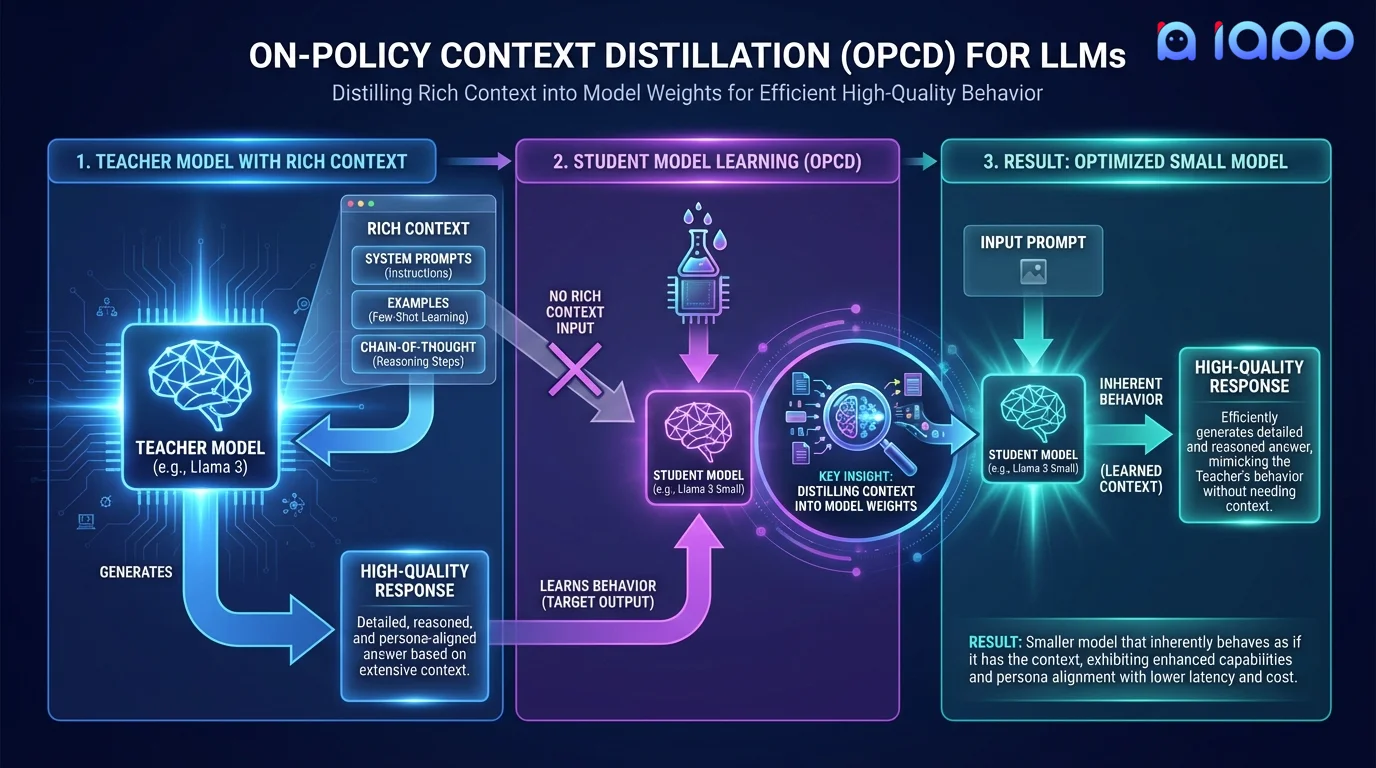
How It Works
From context-dependent to context-free behavior
Context Design
Define the system prompts, examples, and instructions that produce your desired model behavior
On-Policy Generation
The model generates high-quality responses using the full context on diverse prompts
Distillation Training
Train the model to reproduce those same responses without the context
Validation
Verify the context-free model matches the context-dependent model's quality and behavior
Key Benefits
Faster Inference
Eliminate long system prompts and few-shot examples from every request. Reduce input tokens by 50-90%, dramatically lowering latency and cost.
Lower Token Costs
No more paying for thousands of system prompt tokens on every API call. The behavior is baked into the model itself.
Consistent Behavior
The model always behaves as intended, regardless of how the prompt is formatted. No more prompt sensitivity issues.
IP Protection
Your carefully crafted system prompts are embedded in the weights, not exposed in the API. Protect your prompt engineering IP.
Use Cases
Ideal for high-volume production deployments
System Prompt Elimination
Remove the need for lengthy system prompts that define persona, behavior rules, and response format. Bake it all into the model.
Few-Shot Internalization
Stop sending 5-10 examples with every request. The model learns the pattern once and applies it to all future inputs.
Chain-of-Thought Embedding
Distill complex reasoning patterns into the model so it thinks step-by-step without explicit CoT prompting.
Safety Behavior Internalization
Embed safety guidelines and content policies directly into model behavior, making them more robust than prompt-based guardrails.
Brand Voice Encoding
Distill your brand's tone, personality, and communication style into the model so every response is on-brand without needing style prompts.
Output Format Standardization
Teach the model to consistently produce structured outputs (JSON, tables, specific templates) without format instructions in every request.
Why Choose iApp Technology?
Thailand's leading AI company with proven LLM expertise
World-Class Infrastructure
We operate NVIDIA H100, B200, and GB200 supercomputers. OPCD requires generating large volumes of on-policy data, and our infrastructure handles this at scale.
Proven Track Record
We are the makers of production LLMs trusted by enterprises across Thailand and Southeast Asia.
Pricing
Project-Based Pricing
Context distillation pricing depends on the complexity of the context being distilled, model size, and the volume of on-policy data needed.
- ✓ Free initial consultation and context analysis
- ✓ Transparent pricing with no hidden fees
- ✓ Quality-matched guarantee vs. context-dependent baseline
- ✓ Post-delivery support included