Teacher-Student Model Distillation
Compress the intelligence of a large teacher model into a smaller, faster student model. Get 90%+ of the performance at a fraction of the size and cost.
Get Started
What is Model Distillation?
Knowledge Distillation is the process of transferring the knowledge from a large, powerful "teacher" model to a smaller, more efficient "student" model. The student learns not just from hard labels, but from the teacher's soft probability distributions over all possible outputs, capturing nuanced relationships and patterns that the teacher has learned.
For example, a 70B parameter teacher model's intelligence can be distilled into a 7B student model that runs 10x faster, uses 10x less memory, and costs 10x less to serve - while retaining 90-95% of the teacher's quality. This is the technique behind models like Llama 3.2 1B/3B and Gemma 2 2B.
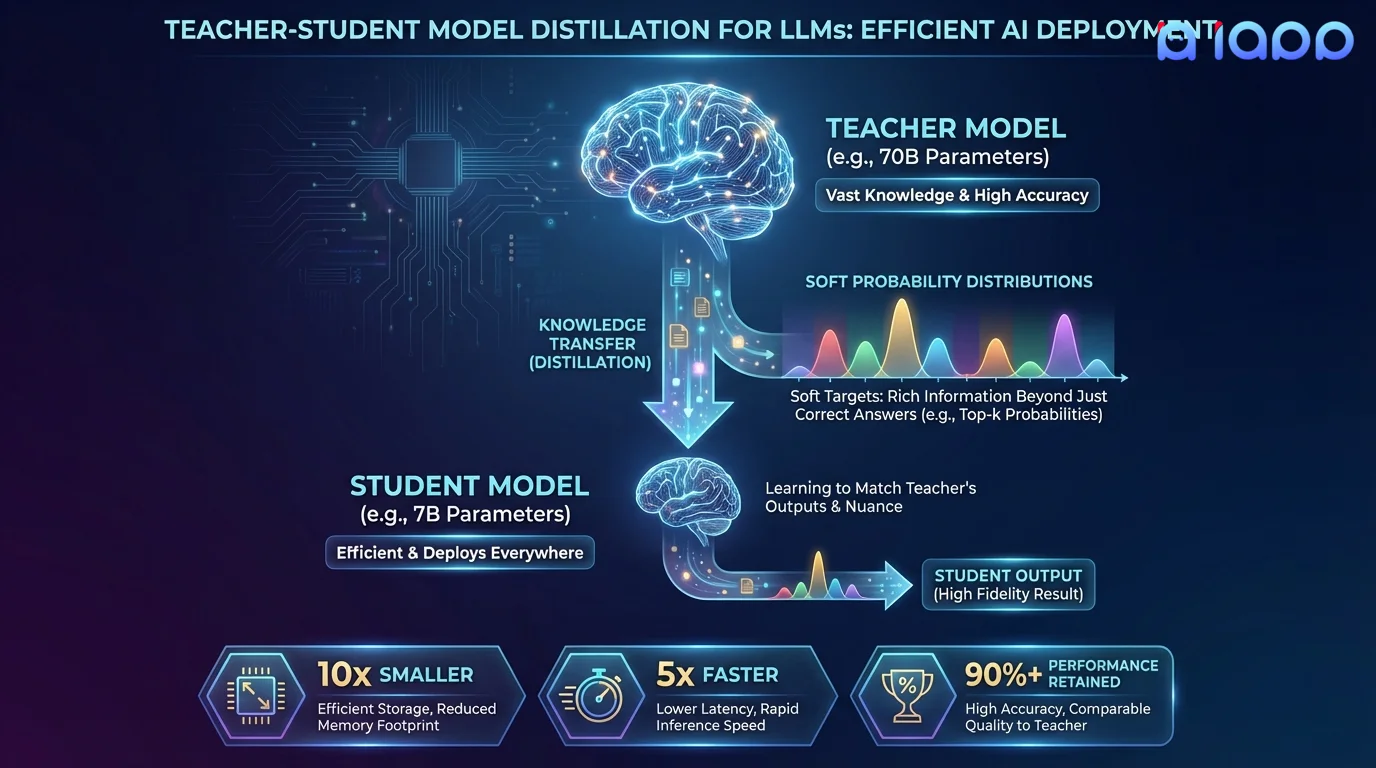
How It Works
From large teacher to efficient student
Teacher Selection
Choose or train the teacher model that represents your quality target
Student Architecture
Design the student model architecture optimized for your deployment constraints
Data Generation
Generate training data from the teacher including soft labels and reasoning traces
Distillation Training
Train the student to match the teacher's output distributions using KL divergence loss
Quality Verification
Benchmark the student against the teacher across your evaluation suite
Key Benefits
10x Faster Inference
Smaller models generate tokens much faster. Reduce latency from seconds to milliseconds for real-time applications.
10x Lower Cost
Serve 10x more users on the same hardware. Dramatically reduce GPU costs for high-volume production deployments.
Edge Deployment
Deploy models on mobile devices, edge servers, and resource-constrained environments where large models cannot run.
90%+ Quality Retention
Student models retain the vast majority of the teacher's capabilities. The quality-efficiency tradeoff is highly favorable.
Use Cases
When you need teacher-level quality at student-level cost
Production Cost Reduction
Replace expensive 70B+ models with distilled 7-8B models that deliver comparable quality at 10x lower serving cost.
Mobile AI Applications
Distill cloud models into 1-3B models that run directly on smartphones for offline-capable AI features.
Real-Time Applications
Achieve sub-100ms response times for chatbots, autocomplete, and interactive AI features that require instant feedback.
Proprietary Model Compression
Distill your proprietary large model's capabilities into a smaller model you can distribute to partners or customers.
Multi-Model Consolidation
Combine the strengths of multiple specialized teacher models into a single versatile student model that handles all your tasks.
API Cost Optimization
Distill expensive proprietary API models (GPT-4, Claude) into your own self-hosted model, eliminating per-token API costs at scale.
Why Choose iApp Technology?
Thailand's leading AI company with proven LLM expertise
World-Class Infrastructure
We operate NVIDIA H100, B200, and GB200 supercomputers. Distillation requires running both teacher and student models simultaneously, and our infrastructure handles this at scale.
Proven Track Record
We are the makers of production LLMs trusted by enterprises across Thailand and Southeast Asia.
Pricing
Project-Based Pricing
Distillation pricing depends on teacher model size, target student size, training data volume, and quality retention requirements.
- ✓ Free initial consultation and feasibility analysis
- ✓ Transparent pricing with no hidden fees
- ✓ Quality retention guarantees
- ✓ Post-delivery support and optimization