LoRA Adaptor Training
Customize large language models efficiently by training only a fraction of the parameters. LoRA delivers impressive results at a fraction of the cost and time of full finetuning.
Get Started
What is LoRA?
LoRA (Low-Rank Adaptation) is a parameter-efficient finetuning technique that freezes the original model weights and injects small, trainable low-rank matrices into the model's attention layers. Instead of updating billions of parameters, LoRA trains only 0.1-1% of the total parameters while achieving comparable performance to full finetuning.
The key insight is that weight updates during finetuning have a low intrinsic rank. By decomposing weight changes into two small matrices (A and B), where W = W₀ + BA, LoRA dramatically reduces memory requirements and training time. Multiple LoRA adaptors can be swapped at inference time, enabling one base model to serve many different tasks.
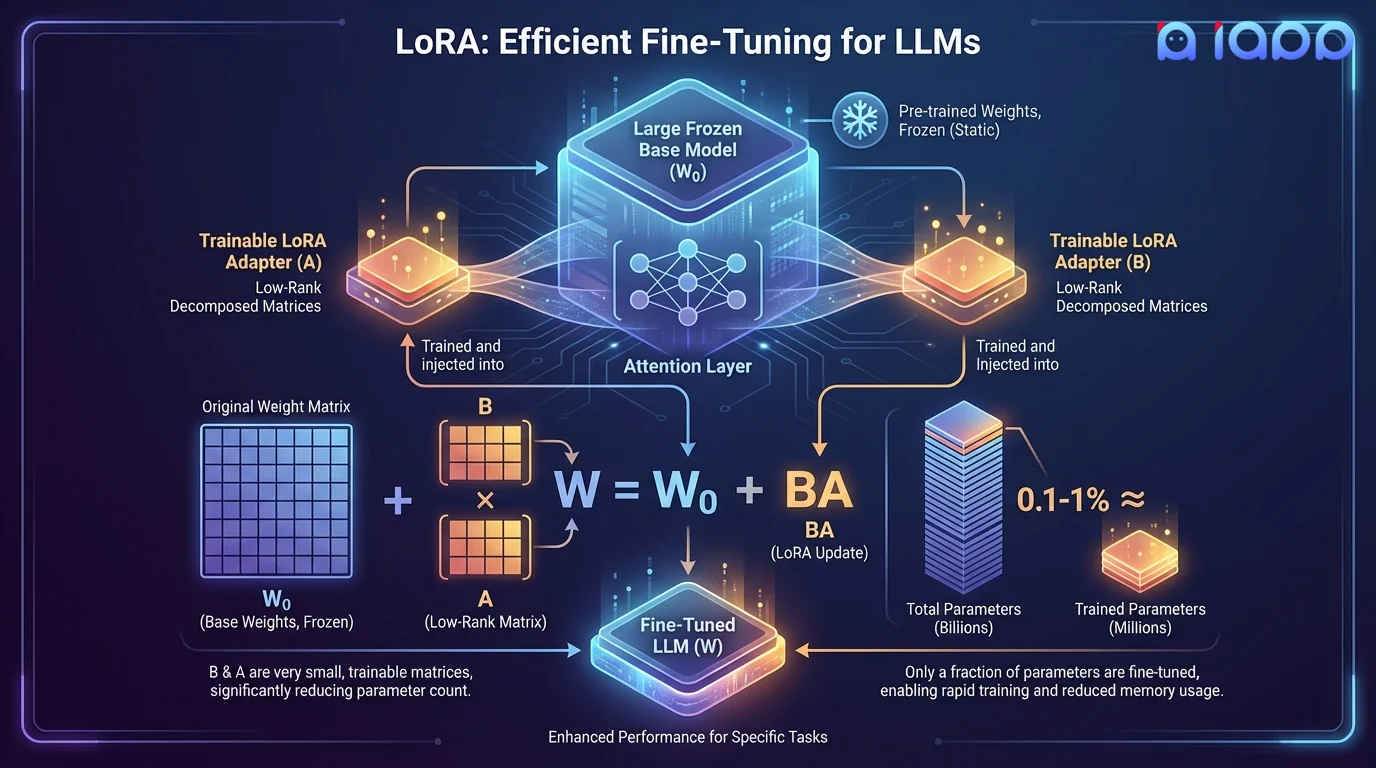
How It Works
Efficient customization without modifying the base model
Task Definition
Define target tasks and prepare instruction-response training pairs
Rank Selection
Choose optimal LoRA rank (r) and target modules based on task complexity
Adaptor Training
Train lightweight adaptor matrices on your data with rapid iteration cycles
Merge or Swap
Merge adaptors into base model for deployment or keep them separate for multi-task serving
Key Advantages
10x Faster Training
Train in hours instead of days. LoRA's small parameter footprint enables rapid experimentation and iteration on your model.
Cost Effective
Dramatically lower GPU memory and compute requirements. Train 70B+ parameter models on a single node.
Hot-Swappable Adaptors
Load different LoRA adaptors at inference time. One base model can serve customer service, translation, coding, and more.
Near Full-FT Performance
Achieve 95-100% of full finetuning quality with QLoRA (quantized LoRA) for even greater efficiency.
Use Cases
Perfect for rapid customization and multi-tenant deployments
Multi-Tenant SaaS
Serve different customers with personalized model behavior using separate LoRA adaptors on a shared base model.
Rapid Prototyping
Quickly test hypotheses and iterate on model behavior without the cost and time of full finetuning.
Multi-Task Models
Create specialized adaptors for translation, summarization, classification, and more on a single base model.
Edge Deployment
Keep the base model on device and swap tiny LoRA adaptors (a few MB) for different functionalities.
Language Adaptation
Add new language capabilities to any base model with a lightweight LoRA adaptor, without degrading the model's existing language performance.
A/B Testing Models
Train multiple LoRA variants with different data or hyperparameters and A/B test them in production to find the optimal model behavior.
Why Choose iApp Technology?
Thailand's leading AI company with proven LLM expertise
World-Class Infrastructure
We operate NVIDIA H100, B200, and GB200 supercomputers. Our infrastructure supports LoRA, QLoRA, and DoRA training on models up to 400B+ parameters.
Proven Track Record
We are the makers of production LLMs trusted by enterprises across Thailand and Southeast Asia.
Pricing
Project-Based Pricing
LoRA training is significantly more cost-effective than full finetuning. Pricing depends on base model size, number of adaptors, and training data volume.
- ✓ Free initial consultation and task assessment
- ✓ Transparent pricing with no hidden fees
- ✓ Fast turnaround - days, not weeks
- ✓ Post-delivery support included