
什么是 LoRA?
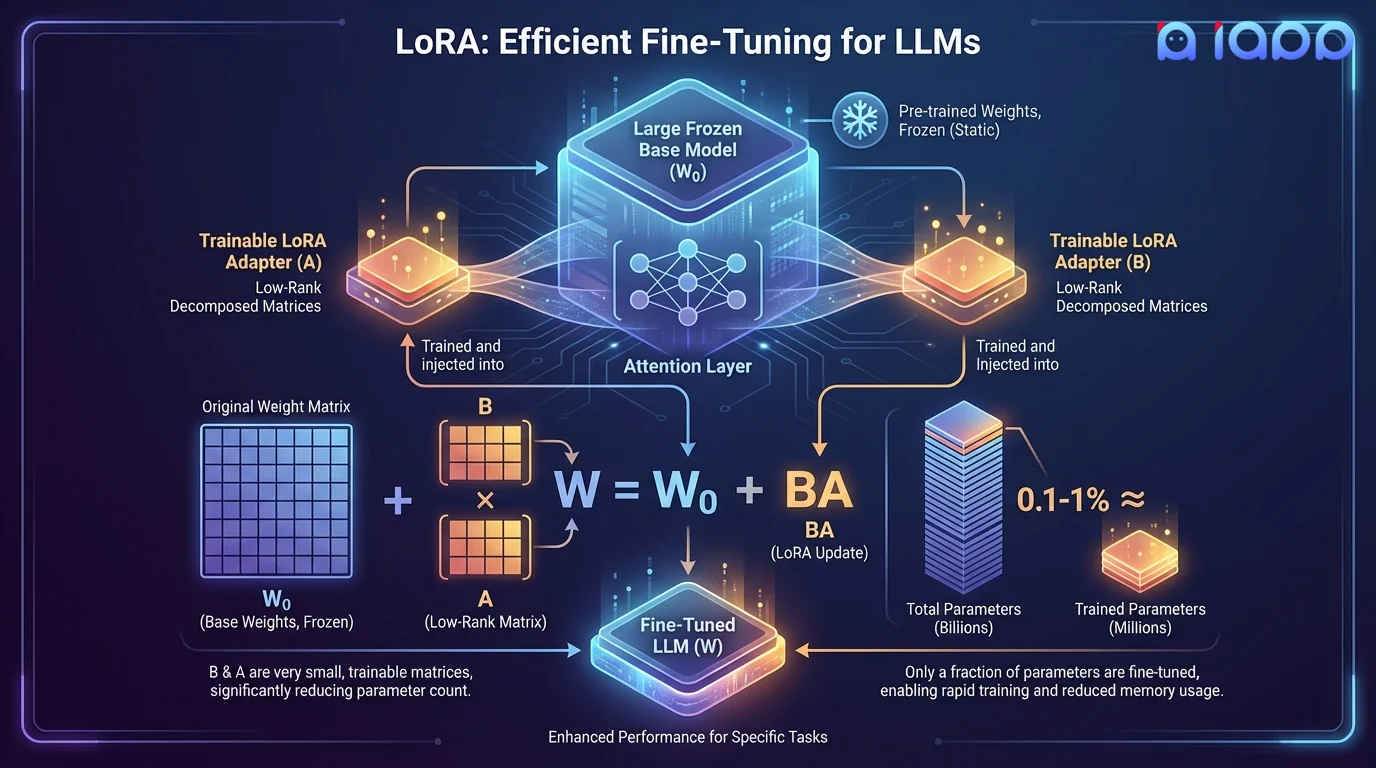
LoRA(低秩自适应)是一种参数高效微调技术,它冻结原始模型权重,并在模型的注意力层中注入小型可训练的低秩矩阵。LoRA 仅训练总参数的 0.1-1%,而不是更新数十亿个参数,同时实现与全量微调相当的性能。
其核心思想是,微调过程中的权重更新具有低内在秩。通过将权重变化分解为两个小矩阵(A 和 B),其中 W = W₀ + BA,LoRA 大幅降低了内存需求和训练时间。多个 LoRA 适配器可以在推理时动态切换,使一个基础模型能够服务于多种不同的任务。
工作流程
无需修改基础模型即可实现高效定制
任务定义
定义目标任务并准备指令-响应训练对
秩选择
根据任务复杂度选择最优的 LoRA 秩(r)和目标模块
适配器训练
使用您的数据训练轻量级适配器矩阵,实现快速迭代循环
合并或切换
将适配器合并到基础模型中进行部署,或保持独立以实现多任务服务
核心优势
训练速度提升 10 倍
数小时而非数天完成训练。LoRA 的小参数占用使您能够快速实验和迭代模型。
高性价比
大幅降低 GPU 内存和计算需求。在单节点上即可训练 700 亿以上参数的模型。
热插拔适配器
在推理时加载不同的 LoRA 适配器。一个基础模型即可服务于客服、翻译、编程等多种任务。
接近全量微调的性能
使用 QLoRA(量化 LoRA)可达到全量微调 95-100% 的质量,效率更高。
应用场景
适用于快速定制和多租户部署
多租户 SaaS
在共享基础模型上使用独立的 LoRA 适配器,为不同客户提供个性化的模型行为。
快速原型开发
无需全量微调的成本和时间,即可快速测试假设并迭代模型行为。
多任务模型
在单个基础模型上为翻译、摘要、分类等任务创建专用适配器。
边缘部署
将基础模型保存在设备上,切换微型 LoRA 适配器(仅几 MB)以实现不同功能。
语言自适应
通过轻量级 LoRA 适配器为任何基础模型添加新语言能力,而不会降低模型现有的语言性能。
模型 A/B 测试
使用不同数据或超参数训练多个 LoRA 变体,在生产环境中进行 A/B 测试以找到最优模型行为。
为什么选择 iApp Technology?
泰国领先的 AI 公司,拥有经过验证的 LLM 专业能力
世界级基础设施
我们运营 NVIDIA H100、B200 和 GB200 超级计算机。我们的基础设施支持 LoRA、QLoRA 和 DoRA 训练,可处理高达 4000 亿以上参数的模型。
成熟的行业经验
我们是泰国及东南亚企业信赖的生产级 LLM 的创造者。
价格
按项目定价
LoRA 训练比全量微调更具性价比。价格取决于基础模型大小、适配器数量和训练数据量。
- ✓ 免费初步咨询和任务评估
- ✓ 透明定价,无隐藏费用
- ✓ 快速交付——以天计,而非以周计
- ✓ 包含交付后支持