
什么是继续预训练?
继续预训练(也称为领域自适应预训练,DAPT)是在大量领域特定文本语料库上进一步训练基础模型的过程。与使用指令-响应对的微调不同,继续预训练使用原始文本数据来教会模型您特定领域的词汇、概念、写作风格和知识。
当您的领域拥有通用模型所缺乏的专业术语、独特模式或专有知识时,这种方法尤为强大。经过继续预训练后,模型将对您的领域获得基本理解,使后续的微调更加有效。
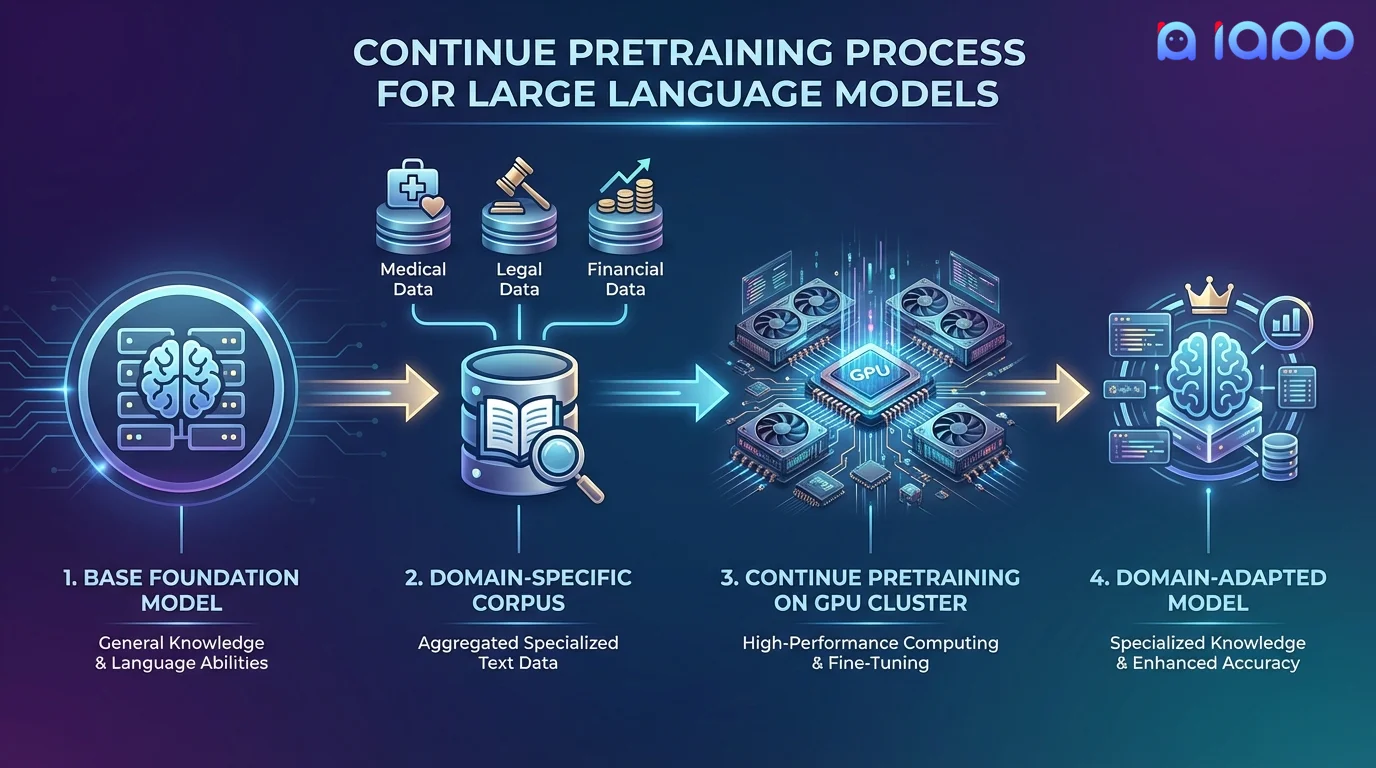
工作流程
从原始领域数据到知识增强的基础模型
语料库收集
收集和整理您的领域特定文档、论文、手册和文本数据
数据清洗
通过质量评分和分词进行去重、过滤和语料库准备
词汇扩展
可选择使用领域特定术语扩展分词器,以提高编码效率
预训练
使用下一个词预测方法在您的语料库上进行训练,并精心调整学习率调度
验证
验证领域�知识的保留情况,确保通用能力得到保持
核心能力
领域知识注入
将对您行业术语、关系和概念的深入理解直接嵌入模型权重中。
词汇扩展
向词汇表中添加领域特定的标记,实现更高效的专业术语和行话编码。
微调的坚实基础
为后续微调创建更强的基础模型,以更少的特定任务数据获得更好的效果。
多语言自适应
增强模型在泰语、区域语言或任何具有充足训练数据的语言方面的能力。
应用场景
当您的领域需要的不仅仅是微调所能提供的
法律领域自适应
使用法律法规、法院判决和监管文件进行训练,创建深刻理解法律语言和推理的模型。
医学知识整合
使用医学文献、临床笔记和药物数据库进行预训练,应用于医疗健康 AI。
金融智能
整合财务报告、市场数据和监管申报,构建原生理解金融概念的模型。
泰语能力增强
使用精选的泰语语料库增强任何基础模型的泰语能力,提升流畅度和文化理解力。
制造业与工程
使用技术手册、规格说明和维护日志进行预训练,构建理解工业术语和流程的模型。
科学研究
整合科学论文、研究数据和学术出版物,创建对特定科学领域有深入理解的模型。
为什么选择 iApp Technology?
泰国领先的 AI 公司,拥有经过验证的 LLM 专业能力
世界级基础设施
我们运营 NVIDIA H100、B200 和 GB200 超级计算机,专为大规模模型训练而设计。继续预训练需要大量算力,我们的基础设施完全能够胜任。
成熟的行业经验
我们是泰国及东南亚企业信赖的生产级 LLM 的创造者。
价格
按项目定价
继续预训练的费用取决于语料库大小、模型参数、训练时长和计算需求。请联系我们获取详细报价。
- ✓ 免费初步咨询和语料库评估
- ✓ 透明定价,无隐藏费用
- ✓ 基于里程碑的交付和付款
- ✓ 包含交付后支持