
什么是 RLHF?
RLHF(基于人类反馈的强化学习)是训练语言模型使其输出与人类偏好对齐的过程。在监督微调之后,RLHF 是将模型从仅仅生成合理文本转变为产出有帮助、安全且符合您期望行为的输出的关键步骤。
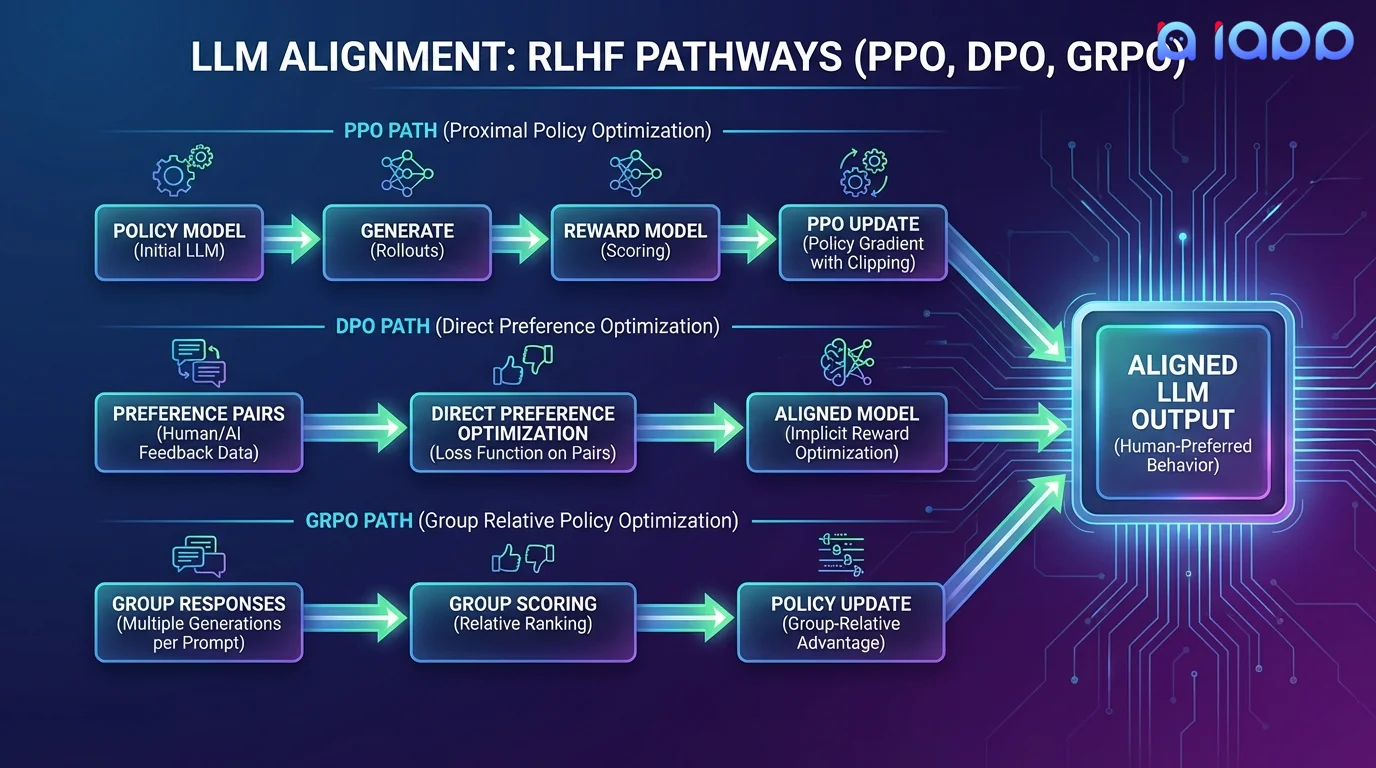
我们提供三种最先进的对齐方法:PPO(ChatGPT 使用的经典方法)、DPO(更简单、更稳定的替代方案)以及 GRPO(DeepSeek 的最新突破,无需单独的奖励模型)。
三种对齐方法
根据您的对齐需求选择合适的方法
DPO - 直接偏好优化
DPO 无需单独的奖励模型。它使用偏好对(选中与拒绝的响应)直接优化策略。实现更简单、训练更稳定,通常能达到与 PPO 相当甚至更好的效果。当您有明确的偏好数据时,这是理想的选择。
GRPO - 群体相对策略优化
由 DeepSeek 开发,GRPO 为每个提示生成多个响应,并使用群体相对评分来优化策略。无需奖励模型。它天然鼓励探索和多样性,特别适合推理和数学任务。这是 DeepSeek-R1 背后的技术。
PPO - 近端策略优化
ChatGPT 和许多领先模型使用的经典 RLHF 方法。PPO 从人类偏好中训练一个单独的奖励模型,然后使用奖励信号优化 LLM 策略。这是最灵活的方法,支持复杂的奖励塑造和多目标优化。
工作流程
从偏好数据到对齐模型的完整流程
偏好数据收集
收集人类偏好数据:选中/拒绝对或模型响应排名
方法选择
根据您的数据、目标和性能要求选择 DPO、GRPO 或 PPO
对齐训练
训练模型以最大化与人类偏好的对齐度,同时保持原有能力
安全评估
全面的安全性和对齐性基准测试,验证模型是否达到您的标准
迭代优化
通过多轮优化精调对齐效果,直到达到目标行为
应用场景
对齐是任何面向客户的 LLM 部署的关键环节
聊天机器人安全
确保您的聊天机器人拒绝有害请求、避免生成不当内容,并始终围绕您的业务用例保持主题。
语气与��风格对齐
训练模型以您的品牌语调进行沟通——无论是专业、友好、技术还是休闲风格——在所有交互中保持一致。
推理能力增强
使用 GRPO 提升思维链推理、数学问题解决和逻辑推导能力。
合规性保障
使模型输出与行业法规对齐,确保响应符合金融、医疗或法律要求。
减少幻觉
通过偏好训练惩罚虚构信息,教会模型在不确定时说"我不知道",而非生成听起来合理但实际错误的回答。
指令遵循
提升模型精确遵循复杂多步骤指令的能力,不偏离、不遗漏步骤、不添加不必要的展开。
为什么选择 iApp Technology?
泰国领先的 AI 公司,拥有经过验证的 LLM 专业能力
世界级基础设施
RLHF 训练对算力要求极高。我们运营 NVIDIA H100、B200 和 GB200 超级计算机,可轻松处理 PPO 的多模型训练、GRPO 的多响应生成和 DPO 的大批量优化。
成熟的行业经验
我们是泰国及东南亚企业信赖的生产级 LLM 的创造者。