
什么是模型蒸馏?
知识蒸馏是将大型、强大的"教师"模型的知识转移到更小、更高效的"学生"模型的过程。学生不仅从硬标签中学习,还从教师对所有可能输出的软概率分布中学习,捕获教师所学到的细微关系和模式。
例如,一个 700 亿参数的教师模型的智能可以蒸馏到一个 70 亿参数的学生模型中,后者运行速度快 10 倍、内存占用少 10 倍、服务成本低 10 倍——同时保留教师模型 90-95% 的质量。这正是 Llama 3.2 1B/3B 和 Gemma 2 2B 等模型背后的技术。
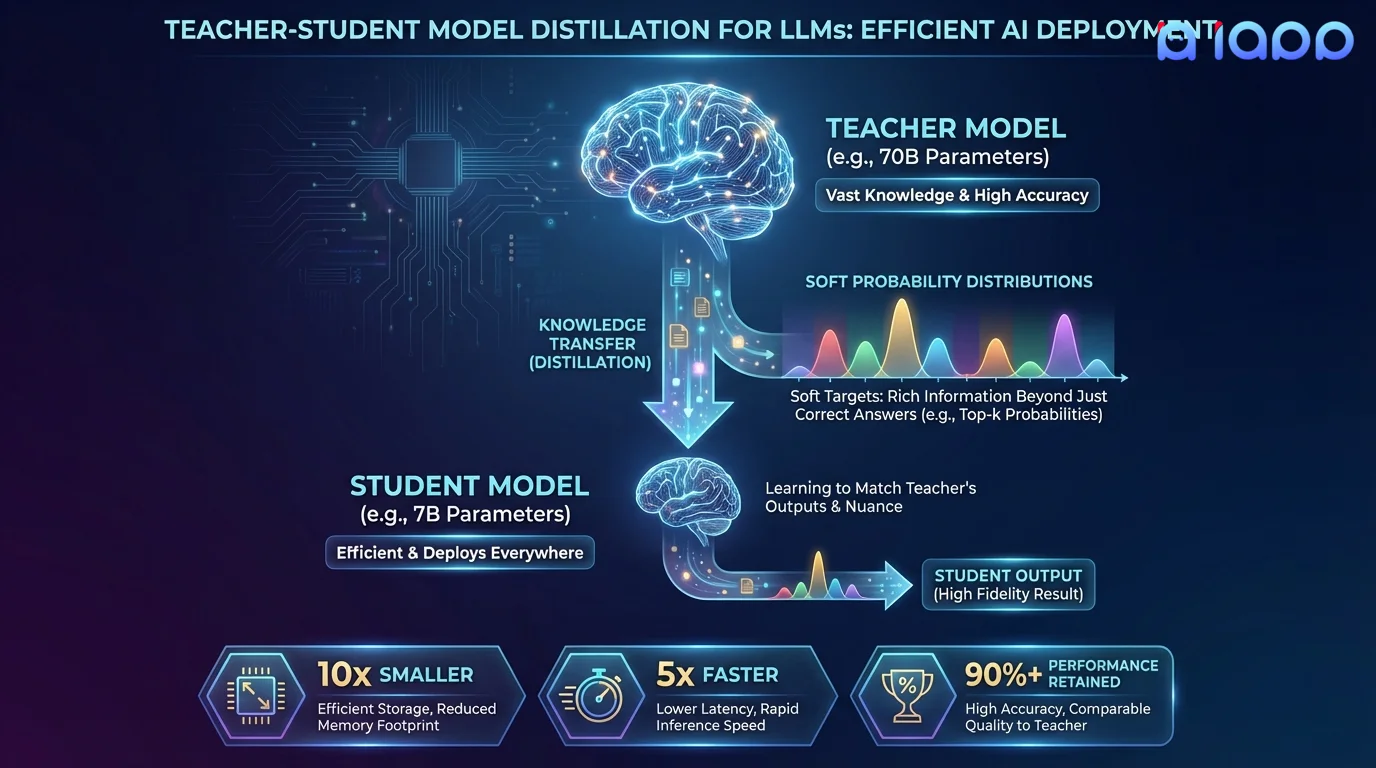
工作原理
从大型教师到高效学生
教师选择
选择或训练代表您质量目标的教师模型
学生架构
设计针对您部署约束优化的学生模型架构
数据生成
从教师模型生成包含软标签和推理轨迹的训练数据
蒸馏训练
使用 KL divergence 损失训练学生匹配教师的输出分布
质量验证
在您的评估套件中将学生模型与教师模型进行基准对比
核心优势
10 倍推理速度
更小的模型生成 Token 速度更快。将实时应用的延迟从秒级降低到毫秒级。
10 倍成本降低
在相同硬件上服务 10 倍的用户。大幅降低大规模生产部署的 GPU 成本。
边缘部署
在移动设备、边缘服务器和资源受限环境中部署模型——大型模型无法在这些环境中运行。
90% 以上质量保留
学生模型保留了教师模型的绝大部分能力。质量与效率的权衡非常有利。
应用场景
以学生级成本获得教师级质量
生产成本降低
用蒸馏后的 70-80 亿参数模型替代昂贵的 700 亿以上参数模型,以 10 倍低的服务成本提供相当的质量。
移动 AI 应用
将云端模型蒸馏为 10-30 亿参数的模型,直接在智能手机上运行,实现离线 AI 功能。
实时应用
为聊天机器人、自动补全和交互式 AI 功能实现低于 100 毫秒的响应时间,满足即时反馈需求。
专有模型压缩
将您专有的大型模型能力蒸馏到更小的模型中,以便分发给合作伙伴或客户。
多模型合并
将多个专业教师模型的优势合并到一个通用的学生模型中,处理您的所有任务。
API 成本优化
将昂贵的专有 API 模型(GPT-4、Claude)蒸馏到您自托管的模型中,在规模化时消除按 Token 计费的 API 成本。
为什么选择 iApp Technology?
泰国领先的 AI 公司,拥有成熟的 LLM 专业技术
世界级基础设施
我们运营 NVIDIA H100、B200 和 GB200 超级计算机。蒸馏需要同时运行教师和学生模型,我们的基础设施可大规模处理。
经过验证的成功案例
我们是深受泰国和东南亚企业信赖的生产级 LLM 的开发者。