
什么是上下文蒸馏?
上下文蒸馏是训练模型内化由特定上下文(系统提示、少样本示例或思维链指令)所引发的行为的过程,使其在推理时无需该上下文即可产生同样高质量的输出。
策略内上下文蒸馏 (OPCD) 更进一步,使用模型自身的生成结果(策略内)而非静态数据集。模型在丰富上下文下生成响应,然后学习在没有上下文的情况下复现这些响应。这种方法更为有效,因为训练数据与模型的实际输出分布相匹配。
最终效果:更快的推理速度(无需冗长的系统提示)、更低的 Token 成本、更一致的行为,以及将复杂推理模式嵌入模型本身的能力。
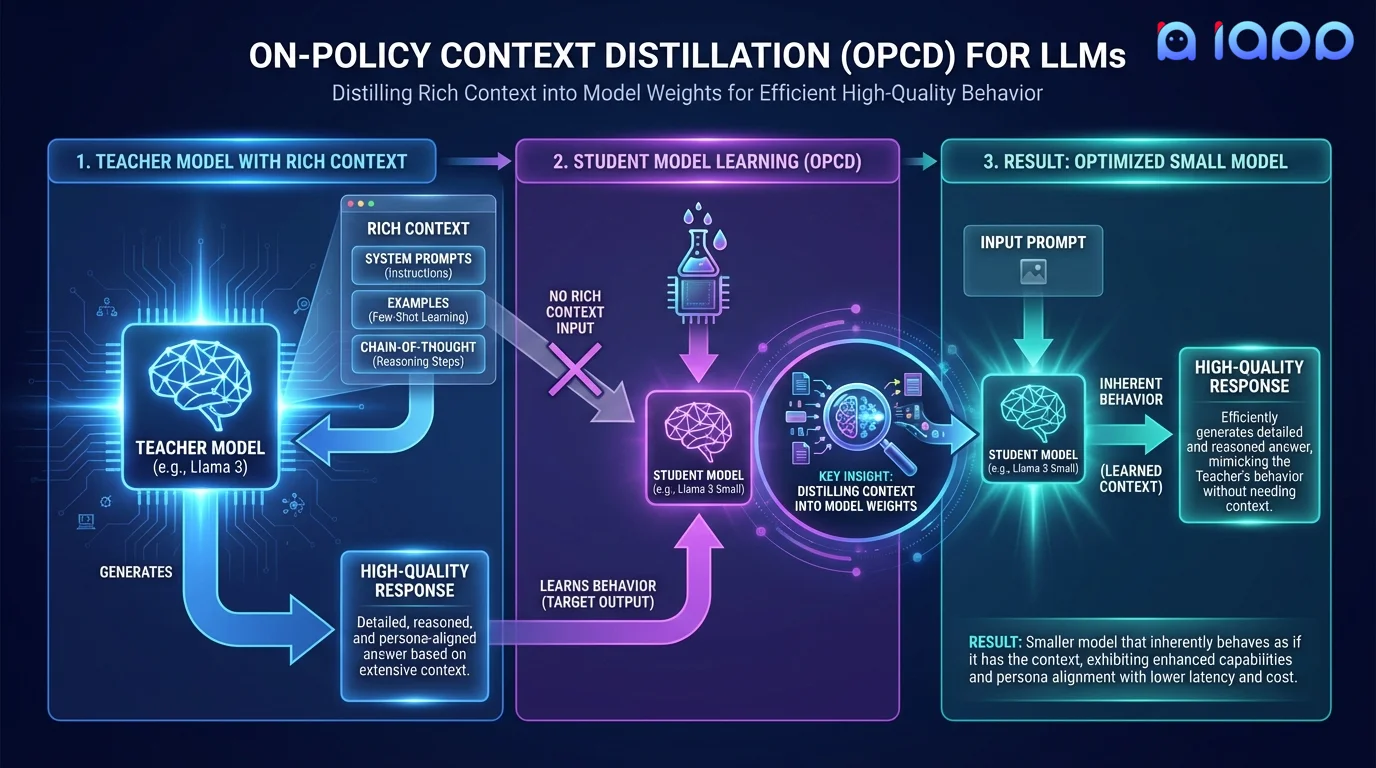
工作原理
从依赖上下文到无需上下文的行为
上下文设计
定义能够产生目标模型行为的系统提示、示例和指令
策略内生成
模型使用完整上下文在多样化提示上生成高质量响应
蒸馏训练
训练模型在没有上下文的情况下复现同样的响应
验证
验证无上下文模型是否匹配依赖上下文模型的质量和行为
核心优势
更快的推理速度
消除每次请求中冗长的系统提示和少样本示例。减少 50-90% 的输入 Token,显著降低延迟和成本。
更低的 Token 成本
无需再为每次 API 调用支付数千个系统提示 Token 的费用。行为已内置于模型本身。
一致的行为表现
无论提示格式如何,模型始终按预期运作。不再有提示敏感性问题。
知识产权保护
您精心设计的系统提示嵌入在权重中,而非暴露在 API 中。保护您的提示工程知识产权。
应用场景
适用于大规模生产部署
消除系统提示
无需再使用定义角色、行为规则和响应格式的冗长系统提示。将一切内置于模型中。
少样本内化
停止在每次请求中发送 5-10 个示例。模型只需学习一次模式,即可应用于所有未来输入。
思维链嵌入
将复杂的推理模式蒸馏到模型中,使其无需显式 CoT 提示即可逐步思考。
安全行为内化
将安全准则和内容策略直接嵌入模型行为,使其比基于提示的防护措施更加稳健。
品牌语调编码
将您品牌的语调、个性和沟通风格蒸馏到模型中,使每次响应都符合品牌形象,无需风格提示。
输出格式标准化
教会模型始终生成结构化输出(JSON、表格、特定模板),无需在每次请求中附加格式指令。
为什么选择 iApp Technology?
泰国领先的 AI 公司,拥有成熟的 LLM 专业技术
世界级基础设施
我们运营 NVIDIA H100、B200 和 GB200 超级计算机。OPCD 需要生成大量策略内数据,我们的基础设施可大规模处理。
经过验证的成功案例
我们是深受泰国和东南亚企业信赖的生产级 LLM 的开发者。
价格
按项目定价
上下文蒸馏的定价取决于待蒸馏上下文的复杂度、模型大小以及所需的策略内数据量。
- ✓ 免费初始咨询和上下文分析
- ✓ 透明定价,无隐藏费用
- ✓ 质量匹配保证,对标依赖上下文的基线
- ✓ 包含交付后支持