Continue Pretraining
Inject your domain knowledge directly into a foundation model's understanding. Continue pretraining teaches the LLM your industry's language, concepts, and patterns at the deepest level.
Get Started
What is Continue Pretraining?
Continue Pretraining (also called Domain-Adaptive Pretraining or DAPT) is the process of further training a foundation model on a large corpus of domain-specific text. Unlike finetuning which uses instruction-response pairs, continue pretraining uses raw text data to teach the model the vocabulary, concepts, writing style, and knowledge of your specific domain.
This approach is especially powerful when your domain has specialized terminology, unique patterns, or proprietary knowledge that general-purpose models lack. After continue pretraining, the model gains a fundamental understanding of your domain, making subsequent finetuning far more effective.
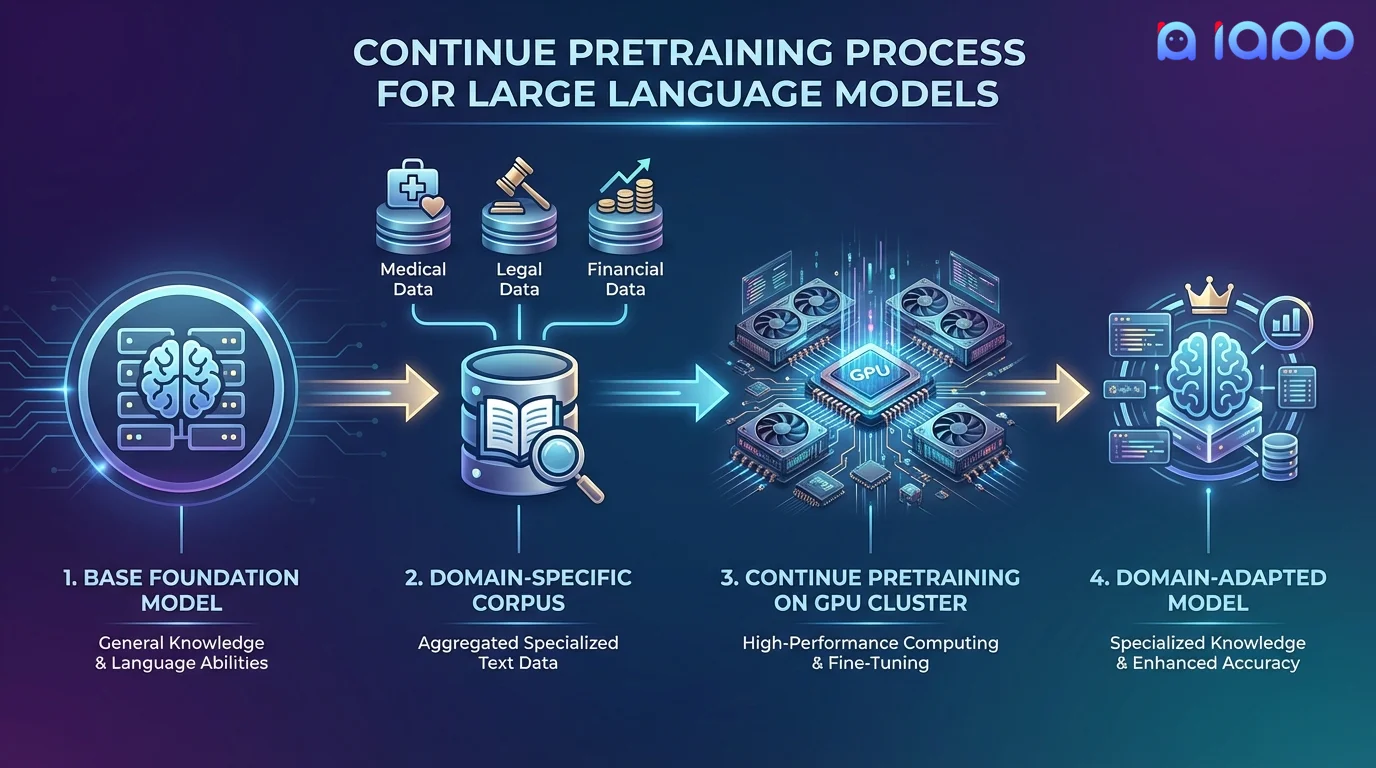
How It Works
From raw domain data to a knowledge-enriched foundation model
Corpus Collection
Gather and organize your domain-specific documents, papers, manuals, and text data
Data Cleaning
Deduplicate, filter, and prepare the corpus with quality scoring and tokenization
Vocabulary Expansion
Optionally extend the tokenizer with domain-specific terms for better efficiency
Pretraining
Train on your corpus using next-token prediction with careful learning rate scheduling
Validation
Verify domain knowledge retention and ensure general capabilities are preserved
Key Capabilities
Domain Knowledge Injection
Embed deep understanding of your industry's terminology, relationships, and concepts directly into the model weights.
Vocabulary Expansion
Add domain-specific tokens to the vocabulary for more efficient encoding of specialized terms and jargon.
Foundation for Finetuning
Creates a stronger base model for subsequent finetuning, yielding better results with less task-specific data.
Multi-Lingual Adaptation
Strengthen a model's capabilities in Thai, regional languages, or any language with sufficient training data.
Use Cases
When your domain needs more than what finetuning alone can provide
Legal Domain Adaptation
Train on legal codes, court rulings, and regulatory documents to create a model that deeply understands legal language and reasoning.
Medical Knowledge Integration
Pretrain on medical literature, clinical notes, and drug databases for healthcare AI applications.
Financial Intelligence
Incorporate financial reports, market data, and regulatory filings to build models that understand financial concepts natively.
Thai Language Enhancement
Strengthen Thai language capabilities of any foundation model using curated Thai corpora, improving fluency and cultural understanding.
Manufacturing & Engineering
Pretrain on technical manuals, specifications, and maintenance logs to build models that understand industrial terminology and procedures.
Scientific Research
Incorporate scientific papers, research data, and academic publications to create models with deep understanding of specific scientific domains.
Why Choose iApp Technology?
Thailand's leading AI company with proven LLM expertise
World-Class Infrastructure
We operate NVIDIA H100, B200, and GB200 supercomputers purpose-built for large-scale model training. Continue pretraining requires massive compute, and our infrastructure delivers.
Proven Track Record
We are the makers of production LLMs trusted by enterprises across Thailand and Southeast Asia.
Pricing
Project-Based Pricing
Continue pretraining costs depend on corpus size, model parameters, training duration, and compute requirements. Contact us for a detailed quote.
- ✓ Free initial consultation and corpus assessment
- ✓ Transparent pricing with no hidden fees
- ✓ Milestone-based delivery and payments
- ✓ Post-delivery support included