Continue Pretraining
ฉีดความรู้เฉพาะโดเมนของคุณเข้าสู่ความเข้าใจของโมเดลพื้นฐานโดยตรง Continue Pretraining สอนให้ LLM เรียนรู้ภา�ษา แนวคิด และรูปแบบของอุตสาหกรรมคุณในระดับลึกที่สุด
เริ่มต้นใช้งาน
Continue Pretraining คืออะไร?
Continue Pretraining (หรือเรียกว่า Domain-Adaptive Pretraining หรือ DAPT) คือกระบวนการฝึกสอนโมเดลพื้นฐานเพิ่มเติมด้วยข้อมูลข้อความเฉพาะโดเมนจำนวนมาก ต่างจาก Finetuning ที่ใช้คู่คำสั่ง-คำตอบ Continue Pretraining ใช้ข้อมูลข้อความดิบเพื่อสอนให้โมเดลเรียนรู้คำศัพท์ แนวคิด สไตล์การเขียน และความรู้ของโดเมนเฉพาะของคุณ
วิธีนี้มีประสิทธิภาพอย่างยิ่งเมื่อโดเมนของคุณมีศัพท์เทคนิคเฉพาะทาง รูปแบบเฉพาะ หรือความรู้ที่เป็นกรรมสิทธิ์ซึ่งโมเดลทั่วไปไม่มี หลังจาก Continue Pretraining โมเดลจะมีความเข้าใจพื้นฐานในโดเมนของคุณ ทำให้การ Finetuning ในขั้นตอนถัดไปมีประสิทธิผลมากขึ้น
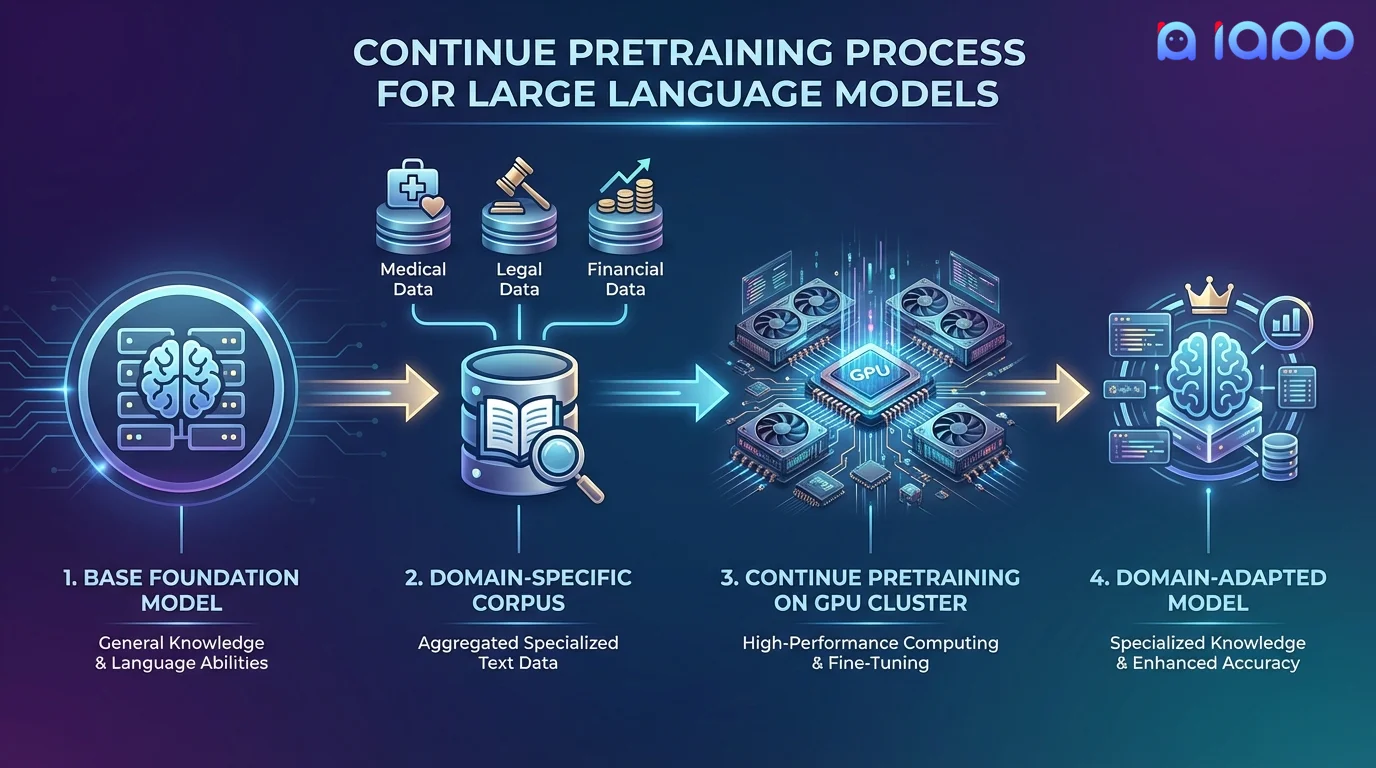
ขั้นตอนการทำงาน
จากข้อมูลดิบเฉพาะโดเมนสู่โมเดลพื้นฐานที่เสริมความรู้
รวบรวมข้อมูล
รวบรวมและจัดระเบียบเอกสาร บทความ คู่มือ และข้อมูลข้อความเฉพาะโดเมนของคุณ
ทำความสะอาดข้อมูล
กำจัดข้อมูลซ้ำ กรอง และเตรียมข้อมูลด้วยการให้คะแนนคุณภาพและ Tokenization
ขยายคลังคำศัพท์
เพิ่มคำศัพท์เฉพาะโดเมนเข้าสู่ Tokenizer เพื่อเพิ่มประสิทธิภาพการเข้ารหัส (ตามความเหมาะสม)
Pretraining
ฝึกสอนด้วยข้อมูลของคุณโดยใช้ Next-Token Prediction พร้อมการปรับ Learning Rate อย่างระมัดระวัง
ตรวจสอบผลลัพธ์
ยืนยันว่าโมเดลเก็บรักษาความรู้เฉพาะโดเมนและรักษาความสามารถทั่วไปไว้ได้
ความสามารถหลัก
ฉีดความรู้เฉพาะโดเมน
ฝังความเข้าใจเชิงลึกเกี่ยวกับศัพท์เทคนิค ความสัมพันธ์ และแนวคิดของอุตสาหกรรมคุณเข้าสู่น้ำหนักของโมเดลโดยตรง
ขยายคลังคำศัพท์
เพิ่ม Token เฉพาะโดเมนเข้าสู่คลังคำศัพท์เพื่อให้เข้ารหัสคำศัพท์เฉพาะทางและศัพท์เทคนิคได้มีประสิทธิภาพยิ่งขึ้น
รากฐานสำหรับ Finetuning
สร้างโมเดลพื้นฐานที่แข็งแกร่งกว่าสำหรับการ Finetuning ในขั้นตอนถัดไป ให้ผลลัพธ์ที่ดีกว่าด้วยข้อมูลเฉพาะงานที่น้อยกว่า
ปรับแต่งหลายภาษา
เสริมความแข็งแกร่งของโมเดลในภาษาไทย ภาษาในภูมิภาค หรือภาษาใดๆ ที่มีข้อมูลฝึกสอนเพียงพอ
กรณีการใช้งาน
เมื่อโดเมนของคุณต้องการมากกว่าที่ Finetuning อย่างเดียวสามารถให้ได้
ปรับแต่งสำหรับโดเมนกฎหมาย
ฝึกสอนด้วยประมวลกฎหมาย คำพิพากษา และเอกสารกฎระเบียบ เพื่อสร้างโมเดลที่เข้าใจภาษาและการให้เหตุผลทางกฎหมายอย่างลึกซึ้ง
บูรณาการความรู้ทางการแพทย์
Pretrain ด้วยวรรณกรรมทางการแพทย์ บันทึกทางคลินิก และฐานข้อมูลยา สำหรับแอปพลิเคชัน AI ด้านสาธารณสุข
ปัญญาทางการเงิน
ผนวกรายงานการเงิน ข้อมูลตลาด และเอกสารกำกับดูแล เพื่อสร้างโมเดลที่เข้าใจแนวคิดทางการเงินโดยธรรมชาติ
เสริมความสามารถภาษาไทย
เสริมความแข็งแกร่งของภาษาไทยในโมเดลพื้นฐานใดๆ โดยใช้ข้อมูลภาษาไทยที่คัดสรร เพิ่มความคล่องแคล่วและความเข้าใจเชิงวัฒนธรรม
การผลิตและวิศวกรรม
Pretrain ด้วยคู่มือเทคนิค ข้อกำหนด และบันทึกการบำรุงรักษา เพื่อสร้างโมเดลที่เข้าใจศัพท์และขั้นตอนทางอุตสาหกรรม
การวิจัยทางวิทยาศาสตร์
ผนวกบทความวิทยาศาสตร์ ข้อมูลวิจัย และสิ่งพิมพ์ทางวิชาการ เพื่อสร้างโมเดลที่เข้าใจโดเมนวิทยาศาสตร์เฉพาะทางอย่างลึกซึ้ง
ทำไมต้องเลือก iApp Technology?
บริษัท AI ชั้นนำของประเทศไทยที่มีความเชี่ยวชาญด้าน LLM
โครงสร้างพื้นฐานระดับโลก
เราดำเนินการซูเปอร์คอมพิวเตอร์ NVIDIA H100, B200 และ GB200 ที่ออกแบบมาเฉพาะสำหรับการฝึกสอนโมเดลขนาดใหญ่ Continue Pretraining ต้องการพลังประมวลผลมหาศาล และโครงสร้างพื้นฐานของเราพร้อมรองรับ
ผลงานที่พิสูจน์แล้ว
เราคือผู้สร้าง LLM ที่ใช้งานจริงในระดับองค์กร ได้รับความไว้วางใจจากองค์กรทั่วประเทศไทยและเอเชียตะวันออกเฉียงใต้
ราคา
ราคาตามโปรเจกต์
ค่าใช้จ่าย Continue Pretraining ขึ้นอยู่กับขนาดข้อมูล จำนวนพารามิเตอร์ของโมเดล ระยะเวลาการฝึกสอน และความต้องการพลังประมวลผล ติดต่อเราเพื่อรับใบเสนอราคาโดยละเอียด
- ✓ ปรึกษาเบื้องต้นและประเมินข้อมูลฟรี
- ✓ ราคาโปร่งใส ไม่มีค่าใช้จ่ายแอบแฝง
- ✓ ส่งมอบและชำระเงินตามเป้าหมาย
- ✓ รวมการสนับสนุนหลังส่งมอบ