ขอแนะนำ GPT-OSS-120B และ GPT-OSS-20B พร้อมรองรับรูปแบบ OpenAI Harmony

OpenAI กลับมาสู่การพัฒนา AI แบบโอเพนซอร์สอีกครั้งด้วยการเปิดตัวโมเดลใหม่ที่ทรงพลังสองรุ่น: GPT-OSS-120B และ GPT-OSS-20B โมเดลการให้เหตุผลแบบโอเพนเวทเหล่านี้มีให้ใช้งานภายใต้ใบอนุญาต Apache 2.0 และนำเสนอความก้าวหน้าอย่างมากในด้านความสามารถในการให้เหตุผล พร้อมกับการรองรับรูปแบบการตอบสนอง OpenAI Harmony แบบเนทีฟ
โมเดล GPT-OSS คืออะไร?
โมเดล GPT-OSS แสดงถึงการกลับมาสู่การพัฒนาแบบโอเพนซอร์สของ OpenAI โดยมีสถาปัตยกรรม Mixture-of-Experts (MoE) ขั้นสูงที่ออกแบบมาเพื่อมอบประสิทธิภาพการให้เหตุผลระดับองค์กร ในขณะที่ยังคงรักษาประสิทธิภาพไว้ เปิดตัวในเดือนสิงหาคม 2025 ภายใต้ใบอนุญาต Apache 2.0 โมเดลเหล่านี้มีการแลกเปลี่ยนประสิทธิภาพ-ประสิทธิผลที่แตกต่างกัน ซึ่งปรับให้เหมาะสมสำหรับสถานการณ์การใช้งานที่หลากหลาย ตั้งแต่เซิร์ฟเวอร์ขององค์กรไปจนถึงอุปกรณ์ของผู้บริโภค
GPT-OSS-120B: ประสิทธิภาพระดับองค์กร
โมเดลพารามิเตอร์ 117 พันล้านพารามิเตอร์ (116.8 พันล้านพารามิเตอร์ทั้งหมด โดยมีพารามิเตอร์ที่ใช้งานอยู่ 5.1 พันล้านพารามิเตอร์ต่อโทเค็น) มอบ:
- การให้เหตุผลขั้นสูง: มีประสิทธิภาพเหนือกว่า OpenAI o3-mini และเทียบเท่ากับ o4-mini ในการเขียนโค้ดการแข่งขัน (Codeforces) และการแก้ปัญหา (MMLU)
- สถาปัตยกรรม MoE: การออกแบบแบบ Mixture-of-Experts ที่มีรูปแบบการ attention แบบหนาแน่นและแบบกระจัดกระจายแบบแถบในพื้นที่สลับกัน
- หน้าต่างบริบทที่ยาว: รองรับความยาวบริบทสูงสุด 128k แบบเนทีฟ ด้วย Rotary Positional Embedding (RoPE)
- การผสานรวมองค์กร: ปรับให้เหมาะสมสำหรับการให้เหตุผล งานแบบเอเจนต์ และกรณีการใช้งานของนักพัฒนา
- การหาปริมาณ MXFP4: น้ำหนัก MoE ถูกหาปริมาณเป็นรูปแบบ MXFP4 ทำให้สามารถใช้งานบน GPU 80GB เดียวได้
GPT-OSS-20B: มีประสิทธิภาพและเข้าถึงได้
โมเดลพารามิเตอร์ 21 พันล้านพารามิเตอร์ (20.9 พันล้านพารามิเตอร์ทั้งหมด โดยมีพารามิเตอร์ที่ใช้งานอยู่ 3.6 พันล้านพารามิเตอร์ต่อโทเค็น) เน้นที่:
- ฮาร์ดแวร์ของผู้บริโภค: ทำงานบนแล็ปท็อปและอุปกรณ์ Apple Silicon ที่มีหน่วยความจำเพียง 16GB
- ประสิทธิภาพการแข่งขัน: เทียบเท่าหรือเหนือกว่า o3-mini แม้จะมีขนาดเล็กลง โดยมีประสิทธิภาพเหนือกว่าในด้านคณิตศาสตร์
- การใช้งานแบบ Edge: เหมาะอย่างยิ่งสำหรับแอปพลิเคชันบนอุปกรณ์และฮาร์ดแวร์ของผู้บริโภค
- ประสิทธิภาพ MXFP4: ต้องการหน่วยความจำเพียง 16GB เนื่องจากน้ำหนัก MoE ที่ถูกหาปริมาณแล้ว
เกณฑ์มาตรฐานประสิทธิภาพ
โมเดล GPT-OSS ทั้งสองรุ่นแสดงให้เห็นถึงประสิทธิภาพที่ยอดเยี่ยมในเกณฑ์มาตรฐานการประเมินต่างๆ ทำให้เป็นตัวเลือกที่แข่งขันได้สูงในภูมิทัศน์ AI แบบโอเพนซอร์ส
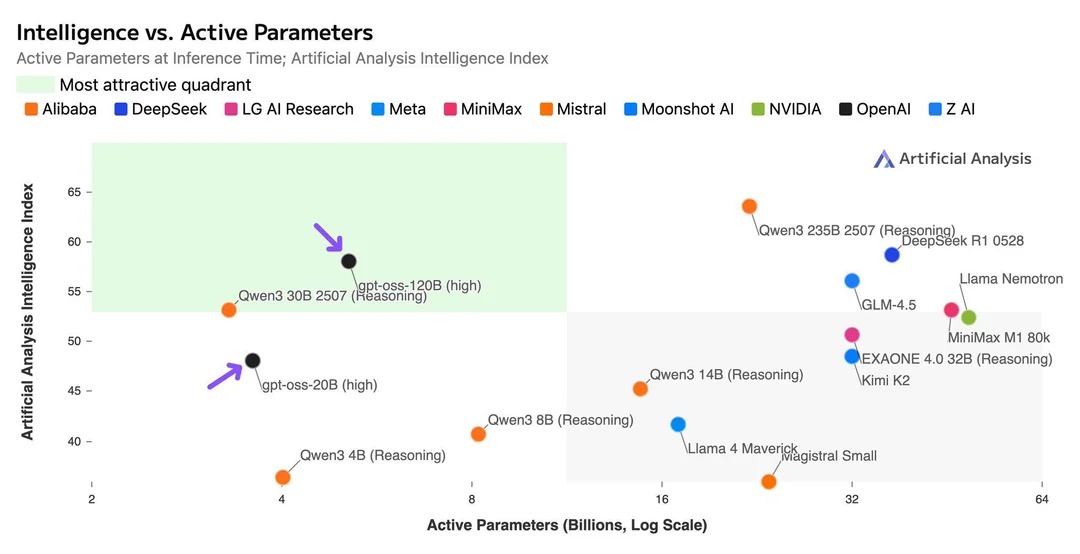
ผลลัพธ์เกณฑ์มาตรฐาน
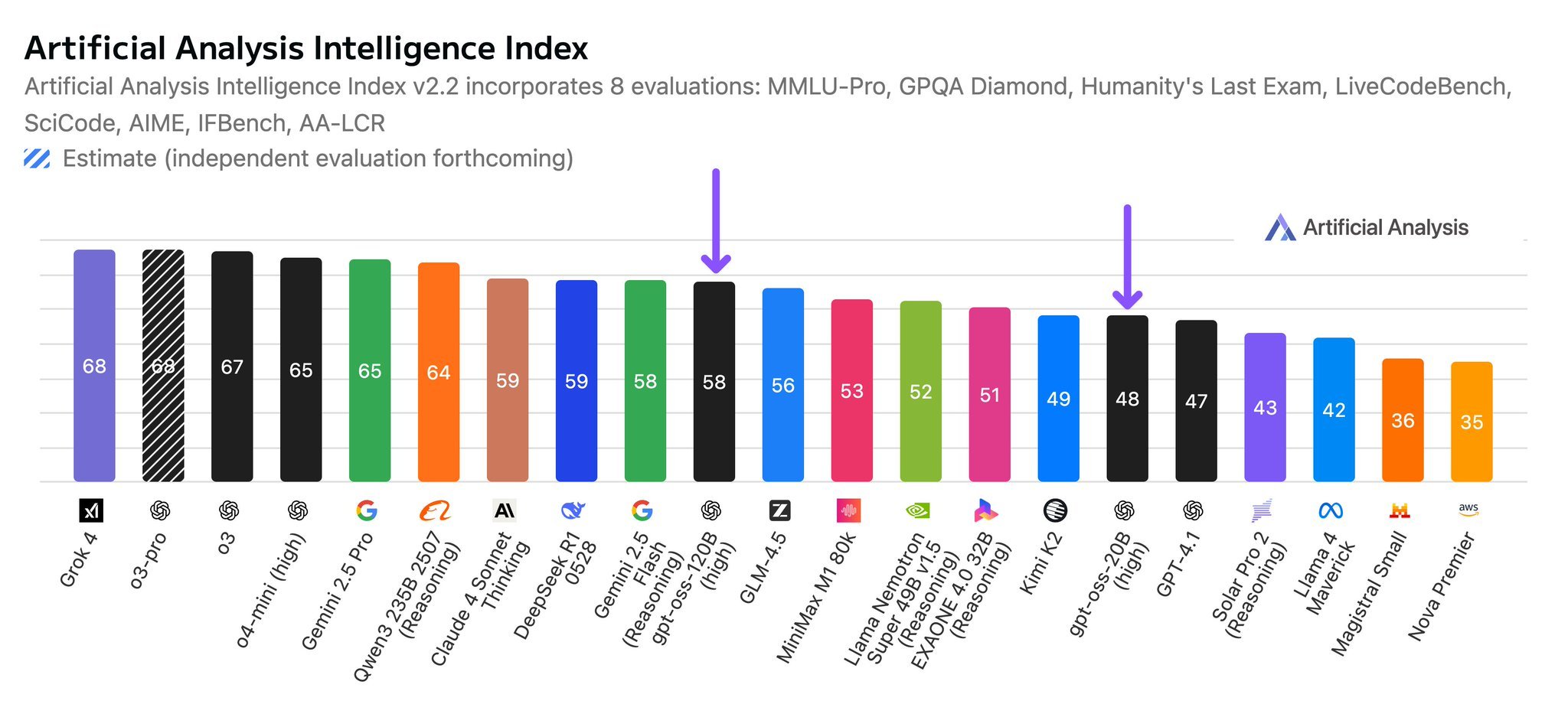
ผลลัพธ์เกณฑ์มาตรฐานแสดงให้เห็นว่า:
- GPT-OSS-120B มีประสิทธิภาพเหนือกว่า OpenAI o3-mini และเทียบเท่ากับ o4-mini ในการเขียนโค้ดการแข่งขันและการแก้ปัญหาทั่วไป
- GPT-OSS-20B มีประสิทธิภาพเทียบเท่าหรือเหนือกว่า o3-mini แม้จะมีขนาดเล็กลง โดยเฉพาะอย่างยิ่งในด้านคณิตศาสตร์
- โมเดลทั้งสองรุ่นแสดงให้เห็นถึงประสิทธิภาพที่แข็งแกร่งในหมวดหมู่การประเมินที่หลากหลาย รวมถึงการให้เหตุผล การเขียนโค้ด และงานด้านความรู้
- โมเดลยังคงรักษาประสิทธิภาพการแข่งขันไว้ ในขณะที่นำเสนอข้อดีของการเข้าถึงแบบโอเพนซอร์สและการใช้งานในสถานที่
ผลลัพธ์เหล่านี้ทำให้โมเดล GPT-OSS เป็นทางเลือกที่ทรงพลังสำหรับโซลูชันแบบเป็นกรรมสิทธิ์ โดยเฉพาะอย่างยิ่งสำหรับองค์กรที่ต้องการความสามารถด้าน AI ที่มีประสิทธิภาพสูงพร้อมการควบคุมสภาพแวดล้อมการใช้งานอย่างเต็มที่
รูปแบบ OpenAI Harmony: การสนทนาแบบมีโครงสร้าง
โมเดลทั้งสองรุ่นมีการรองรับรูปแบบการตอบสนอง OpenAI Harmony แบบเนทีฟ ซึ่งนำเสนอข้อดีที่สำคัญหลายประการ:
การสื่อสารแบบหลายช่องทาง
รูปแบบ Harmony จัดระเบียบการตอบสนองในสามช่องทางที่แตกต่างกัน:
- ช่องทางสุดท้าย: การตอบสนองที่ผู้ใช้เห็น ซึ่งให้ข้อมูลที่ชัดเจนและสามารถดำเนินการได้
- ช่องทางการวิเคราะห์: กระบวนการให้เหตุผลและลำดับความคิดภายใน
- ช่องทางคำอธิบาย: การเรียกใช้ฟังก์ชัน การใช้งานเครื่องมือ และรายละเอียดการใช้งาน
ลำดับชั้นตามบทบาท
บทบาทที่กำหนดไว้ห้าบทบาทสร้างลำดับชั้นข้อมูลที่ชัดเจน:
- ระบบ: การกำหนดค่าและข้อจำกัดที่มีลำดับความสำคัญสูงสุด
- นักพัฒนา: คำแนะนำในการใช้งานและข้อกำหนดทางเทคนิค
- ผู้ใช้: คำขอและความต้องการของผู้ใช้ปลาย��ทาง
- ผู้ช่วย: การตอบสนองและการให้เหตุผลที่สร้างโดย AI
- เครื่องมือ: การเรียกใช้ฟังก์ชันภายนอกและการดึงข้อมูล
ความสามารถในการให้เหตุผลที่ดียิ่งขึ้น
รูปแบบนี้รองรับระดับความพยายามในการให้เหตุผลหลายระดับ:
- ความพยายามต่ำ: การตอบสนองอย่างรวดเร็วสำหรับคำถามง่ายๆ
- ความพยายามปานกลาง: การให้เหตุผลที่สมดุลสำหรับงานมาตรฐาน
- ความพยายามสูง: การวิเคราะห์เชิงลึกสำหรับการแก้ปัญหาที่ซับซ้อน
การใช้งานจริง
การประมวลผลเอกสารขององค์กร
<|channel|>analysis<|message|>
ผู้ใช้ร้องขอการประมวลผลรายงานทางการเงินรายไตรมาส ต้องวิเคราะห์โครงสร้างเอกสาร ระบุตัวชี้วัดทางการเงินที่สำคัญ เชื่อมโยงกับข้อมูลในอดีตเพื่อให้ได้บริบทและแนวโน้ม
<|end|>
<|start|>assistant<|channel|>final<|message|>
รายงานทางการเงินไตรมาสที่ 3 แสดงให้เห็นถึงการเติบโตของรายได้ 15% พร้อมกับอัตรากำไรที่ดีขึ้นในแผนกบริการ AI
<|return|>
การสนับสนุนลูกค้าหลายภาษา
โมเดลมีความโดดเด่นในการให้การสนับสนุนแบบมีโครงสร้างในหลายภาษา โดยรักษาความสอดคล้องในขณะที่ปรับให้เข้ากับบริบททางวัฒนธรรม
การเรียกใช้เครื่องมือและการผสานรวมฟังก์ชัน
รูปแบบ Harmony มีความโดดเด่นในการเรียกใช้เครื่องมือและการผสานรวมฟังก์ชันแบบมีโครงสร้าง:
<|channel|>analysis<|message|>
ผู้ใช้ต้องการข้อมูลสภาพอากาศสำหรับโตเกียว ต้องเรียกใช้ API สภาพอากาศ วิเคราะห์การตอบสนอง และจัดรูปแบบสำหรับผู้ใช้
<|end|>
<|start|>assistant<|channel|>commentary<|message|>
กำลังเรียกใช้ weather_api(location="Tokyo", units="celsius")
<|end|>
<|start|>tool<|channel|>commentary<|message|>
{"temperature": 24, "condition": "sunny", "humidity": 65, "wind_speed": 12}
<|end|>
<|start|>assistant<|channel|>final<|message|>
สภาพอากาศในโตเกียวปัจจุบันอยู่ที่ 24°C และมีแดด อุณหภูมิ 65% และความเร็วลม 12 กม./ชม.
<|return|>
การวิจัยและพัฒนา
ช่องทางการวิเคราะห์ให้ความโปร่งใสในกระบวนการให้เหตุผลของโมเดล ซึ่งมีความสำคัญสำหรับการใช้งานด้านการวิจัยและการตีความโมเดล
ข้อควรพิจารณาในการใช้งาน
ข้อกำหนดด้านโครงสร้างพื้นฐาน
- GPT-OSS-120B: ทำงานบน GPU 80GB เดียว (H100, A100 หรือ AMD MI300X) เนื่องจากการหาปริมาณน้ำหนัก MoE เป็นรูปแบบ MXFP4
- GPT-OSS-20B: ต้องการหน่วยความจำเพียง 16GB เหมาะสำหรับฮาร์ดแวร์ของผู้บริโภค แล็ปท็อป และอุปกรณ์พกพา
กลยุทธ์การผสานรวม
โมเดลทั้งสองรุ่นรองรับ API การอนุมานมาตรฐาน ในขณะที่ให้ความสามารถที่ดียิ่งขึ้นผ่านการผสานรวมรูปแบบ Harmony คุณสมบัติทางเทคนิคที่สำคัญ ได้แก่:
- สถาปัตยกรรม Transformer: ใช้ประโยชน์จากการ attention แบบ multi-query ที่จัดกลุ่ม โดยมีขนาดกลุ่มเท่ากับ 8 เพื่อประสิทธิภาพหน่วยความจำ
- การออกแบบ MoE: แต่ละโมเดลใช้ mixture-of-experts เพื่อลดพารามิเตอร์ที่ใช้งานอยู่ต่อโทเค็น
- รูปแบบ Attention: การ attention แบบหนาแน่นและแบบกระจัดกระจายแบบแถบในพื้นที่สลับกัน คล้ายกับ GPT-3
- การเข้ารหัสตำแหน่ง: Rotary Positional Embedding (RoPE) เพื่อการทำความเข้าใจลำดับที่ดีขึ้น
องค์กรสามารถ:
- เริ่มต้นด้วยการใช้งานที่มีอยู่โดยใช้รูปแบบมาตรฐาน
- ค่อยๆ นำคุณสมบัติของ Harmony มาใช้เพื่อเพิ่มฟังก์ชันการทำงาน
- ใช้ประโยชน์จากช่องทางการวิเคราะห์เพื่อการดี��บักและการปรับให้เหมาะสม
ผลกระทบในอนาคต
การผสมผสานโมเดลโอเพนซอร์สที่ทรงพลังกับรูปแบบการสนทนาแบบมีโครงสร้างแสดงถึงก้าวสำคัญสู่ระบบ AI ที่โปร่งใสและสามารถควบคุมได้มากขึ้น วิธีการตามบทบาทและการสื่อสารแบบหลายช่องทางของรูปแบบ Harmony ช่วยให้:
- การดีบักที่ดีขึ้น: การแยกการให้เหตุผลและผลลัพธ์อย่างชัดเจน
- การตรวจสอบที่ดีขึ้น: บันทึกที่มีโครงสร้างสำหรับการวิเคราะห์ระบบ
- การควบคุมที่ดีขึ้น: การจัดการพฤติกรรม AI อย่างละเอียด
- ความโปร่งใส: กระบวนการให้เหตุผลที่มองเห็นได้สำหรับแอปพลิเคชันที่สำคัญ
เริ่มต้นใช้งาน
องค์กรที่สนใจในการใช้งานโมเดล GPT-OSS พร้อมการรองรับรูปแบบ Harmony ควรพิจารณา:
- การประเมิน: ประเมินความต้องการด้านการคำนวณและกรณีการใช้งาน
- การทดสอบนำร่อง: เริ่มต้นด้วย GPT-OSS-20B สำหรับการสำรวจเบื้องต้น
- การวางแผนการผสานรวม: ออกแบบระบบเพื่อใช้ประโยชน์จากการสื่อสารแบบหลายช่องทาง
- การฝึกอบรม: เตรียมทีมสำหรับการใช้งานรูปแบบ Harmony
การเปิดตัว GPT-OSS-120B และ GPT-OSS-20B ภายใต้ใบอนุญาต Apache 2.0 พร้อมการรองรับรูปแบบ OpenAI Harmony เป็นเครื่องหมายสำคัญที่แสดงให้เห็นถึงการกลับมาสู่การพัฒนา AI แบบโอเพนซอร์สของ OpenAI โมเดลเหล่านี้มอบเครื่องมือที่ทรงพลังให้กับองค์กรสำหรับการสร้างโซลูชันการให้เหตุผลที่โปร่งใส สามารถควบคุมได้ และมีประสิทธิภาพ ซึ่งสามารถทำงานได้ทุกอย่าง ตั้งแต่เซิร์ฟเวอร์ขององค์กรไปจนถึงแล็ปท็อปของผู้บริโภค
ติดต่อเรา เพื่อเรียนรู้วิธีที่ บริษัท ไอแอพพ์เทคโนโลยี จำกัด สามารถช่วยในการใช้งานโมเดลขั้นสูงเหล่านี้ในโครงสร้างพื้นฐาน AI ขององค์กรของคุณ