什么是大数据?初学者完整指南

每一秒,世界都在产生难以想象的数据量。每次 Google 搜索、每条社交媒体帖子、每笔在线购买、每个传感器读数——都在累积。事实上,我们每天创造大约 2.5 艾字节的数据。这种海量信息洪流就是我们所说的大数据(Big Data),学习如何利用它已成为现代商业世界中最有价值的技能之一。
什么是大数据?
大数据指的是规模极大、极其复杂的数据集,传统数据处理工具无法有效处理。但这不仅仅是关于大小——大数据由其独特的特征定义,这些特征使其既具挑战性又具价值。
从本质上讲,大数据是:
- 太大——传统数据库无法处理
- 太快——实时流式生成
- 太多样——有许多不同的格式
- 太复杂——简单分析工具无法处理
大数据的目标不仅仅是收集海量信息——而是分析这些数据以发现能够驱动更好决策的模式、趋势和洞察。
简单示例
传统数据:
- 小店在电子表格中跟踪每日销售
- 每天 100 笔交易,Excel 轻松管理
- 简单计算如月度总额和平均值
大数据:
- 电商平台每天处理数百万笔交易
- 跟踪��用户行为:点击、搜索、页面停留时间、购物车放弃
- 结合社交媒体情绪、天气数据、经济指标
- 使用 AI 预测趋势、个性化推荐、优化定价
大数据的 5V 特征
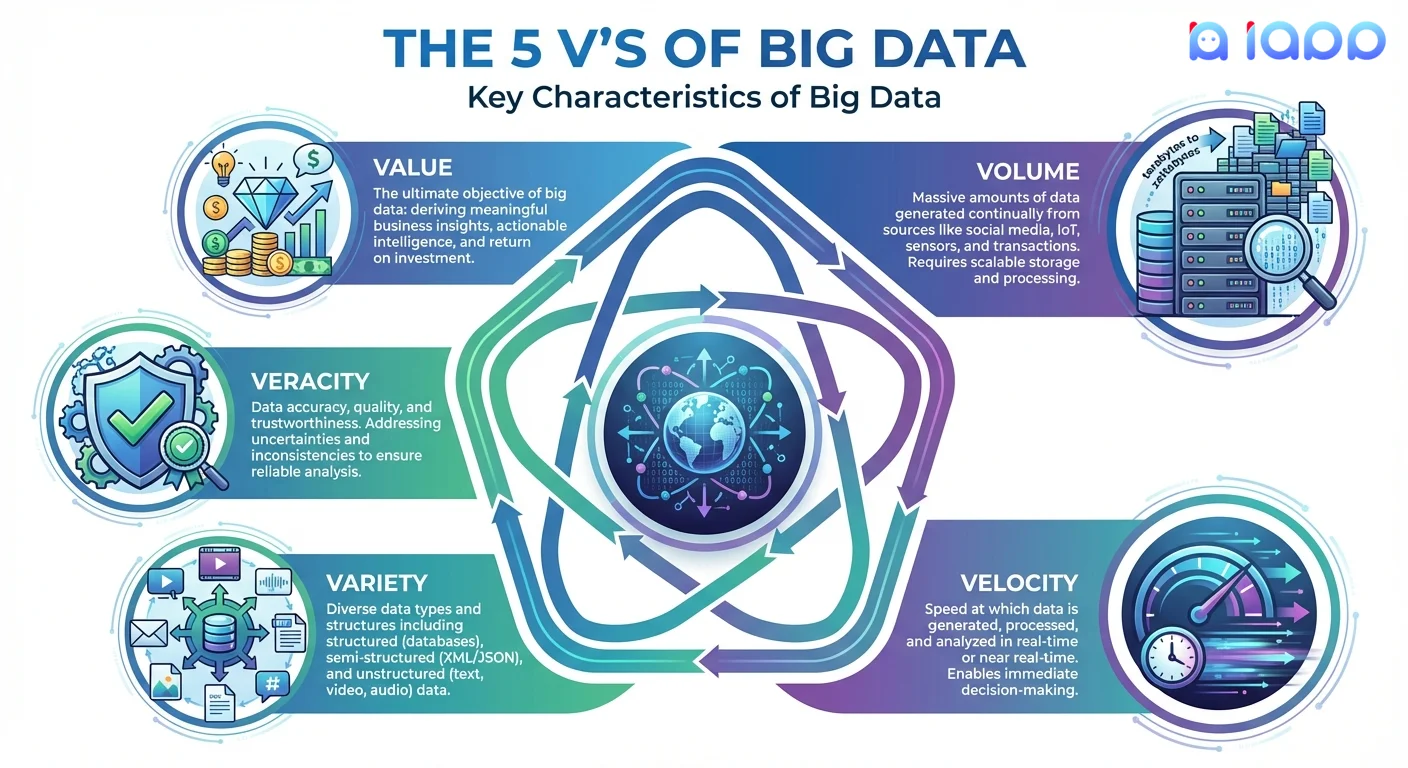
大数据通常由五个关键特征定义:
1. Volume(容量)
正在生成的数据数量。
- Facebook 用户每天上传 3.5 亿张照片
- YouTube 每分钟接收 500 小时的视频
- 物联网传感器持续生成数十亿数据点
挑战: 存储和管理 PB 或 EB 级数据
2. Velocity(速度)
数据创建和需要处理的速度。
- 股市数据每毫秒变化
- 社交媒体帖子几分钟内就能走红
- 传感器数据持续实时流入
挑战: 足够快地处理数据以便及时采取行动
3. Variety(多样性)
数据的不同类型和格式。
- 结构化: 数据库、电子表格、交易记录
- 半结构化: JSON、XML、电子邮件、日志
- 非结构化: 图像、视频、音频、社交媒体帖子、文档
挑战: 整合和分析不同类型的数据
4. Veracity(真实性)
数据的准确性和可信度。
- 数据是否正确可靠?
- 我们如何处理缺失或不完整的数据?
- 我们能信任来源吗?
挑战: 在做决策前确保数据质量
5. Value(价值)
可以从数据中提取的商业价值。
- 原始数据没有分析是无用的
- 目标是可操作的洞察
- ROI 必须证明大数据基础设施的成本是合理的
挑战: 在噪音中找到有意义的模式
大数据的类型
1. 结构化数据
整齐地组织成带有行和列的表格的数据。
示例:
- 数据库记录
- 电子表格
- 交易日志
- 定义格式的传感器读数
特点: 易于搜索、分析和处理 存储: 传统关系数据库(SQL)
2. 半结构化数据
具有一些组织属性但没有严格结构的数据。
示例:
- JSON 和 XML 文件
- 电子邮件消息
- Web 服务器日志
- NoSQL 数据库文档
特点: 灵活的模式,自描述 存储: NoSQL 数据库、文档存储
3. 非结构化数据
没有预定义格式或组织的数据。
示例:
- 文本文档和 PDF
- 图像和照片
- 音频和视频文件
- 社交媒体帖子
特点: 最难分析,需要 AI/ML 存储: 数据湖、对象存储
有趣的事实: 超过 80% 的企业数据是非结构化的,这正是 AI 大放异彩的地方!
大数据关键术语解释(术语解读)
1. 数据湖(Data Lake)
定义: 以原始、原生格式存储所有类型数据的集中式存储库。
简单类比: 就像一个真正的湖泊,不同的溪流(数据源)流入其中。你可以在任何地方钓任何类型的鱼(数据)。
关键特性:
- 存储结构化、半结构化和非结构化数据
- 读取时模式(访问数据时应用结构)
- 大规模存储成本效益高
- 适合 AI/ML 和探索
2. 数据仓库(Data Warehouse)
定义: 为分析和报告优化的结构化、有组织的存储库。
简单类比: 就像一个组织良好的仓库,每样东西都有特定的位置和标签。容易找到你需要的东西。
关键特性:
- 存储结构化、已处理的数据
- 写入时模式(存储前定义结构)
- 为快速查询优化
- 适合商业智能和仪表板
3. ETL(提取、转换、加载)
定义: 将数据从源移动到��目标的过程,在过程中进行转换。
简单类比: 就像把购物袋里的杂货分类、清洁、整理到厨房橱柜里。
步骤:
- Extract(提取): 从各种来源拉取数据
- Transform(转换): 清洁、验证、转换格式
- Load(加载): 存储到目标系统
4. 数据管道(Data Pipeline)
定义: 将数据从源移动和转换到目标的自动化流程序列。
简单类比: 就像工厂装配线,原材料从一端进入,成品从另一端出来。
组件:
- 数据摄取(收集)
- 数据处理(转换)
- 数据存储(仓储)
- 数据分析(洞察)
5. 实时分析(Real-Time Analytics)
定义: 在数据生成时立即处理和分析数据。
简单类比: 就像实时体育比分板,每次比赛动作都即时更新。
用例:
- 欺诈检测
- 股票交易
- 物联网监控
- 实时仪表板
为什么大数据很重要
1. 更好的决策
数据驱动的决策优于直觉。使用大数据分析的公司:
- 做出更快决策的可能性高 5 倍
- 按预期执行决策的可能性高 3 倍
2. 理解客户
大数据揭示:
- 客户真正想要什么(不是他们说的)
- 行为模式和偏好
- 流失预测和预防
- 个性化机会
3. 运营效率
通过以下方式优化运营:
- 预测性维护(在故障前修复)
- 供应链优化
- 资源分配
- 流程自动化
4. 新收入来源
通过以下方式创造价值:
- 数据产品和服务
- 个性化产品
- 动态定价
- 新市场洞察
5. 竞争优势
有效利用大数据的公司可以:
- 更快响应市场变化
- 在竞争对手之前识别趋势
- 基于洞察创新
- 降低成本同时提高质量
大数据解决什么问题?
| 问题 | 传统方法 | 大数据解决方案 |
|---|---|---|
| 客户洞察 | 调查和焦点小组 | 大规模行为分析 |
| 欺诈检测 | 人工审核、规则 | 实时 AI 模式检测 |
| 库存管理 | 历史平均值 | 预测性需求预测 |
| 营销效果 | 活动指标 | 归因建模、个性化 |
| 质量控制 | 样本测试 | 100% 自动检测 |
| 风险评估 | 人工分析 | ML 风险评分模型 |
大数据如何工作
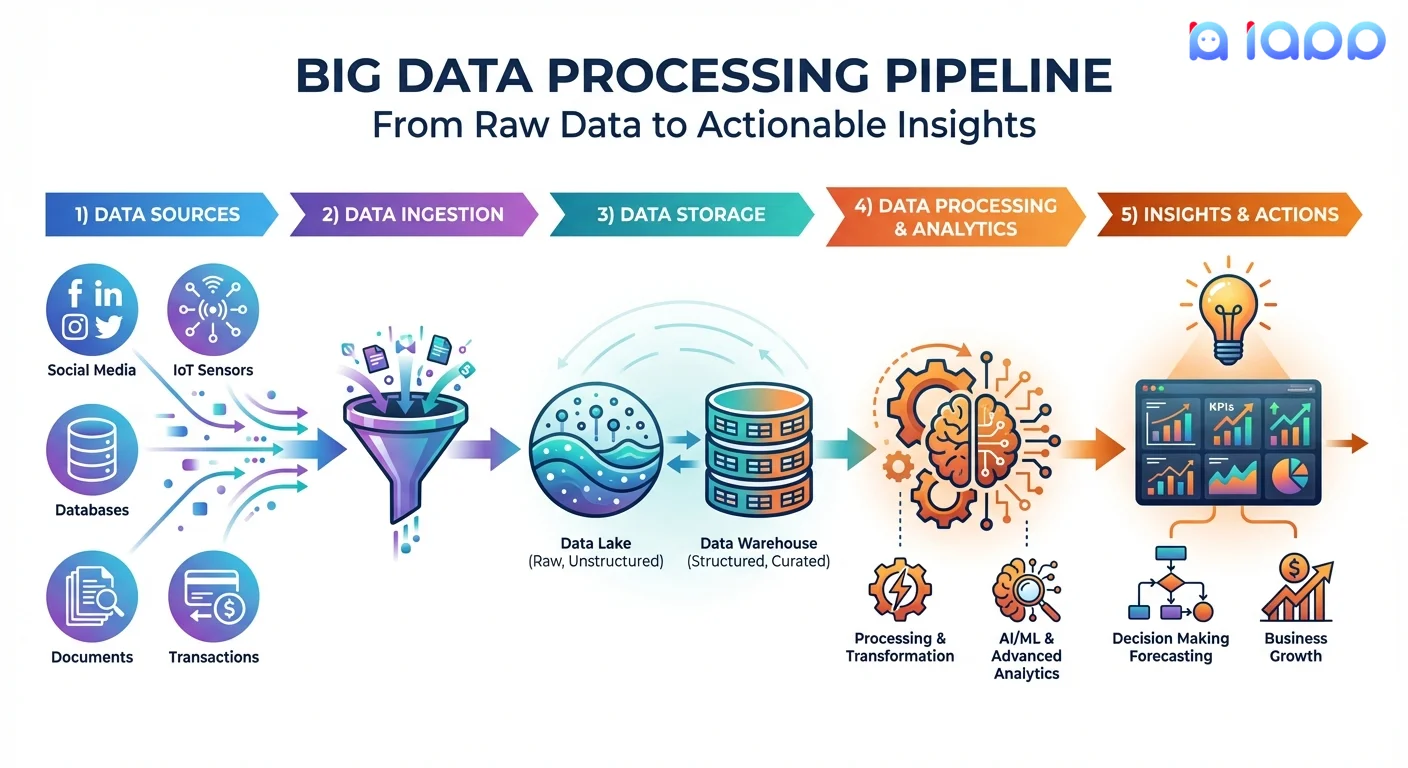
大数据管道
-
数据源
- 内部:CRM、ERP、交易、日志
- 外部:社交媒体、公共数据、第三方
- 物联网:传感器、设备、设备
- ��用户生成:文档、图像、反馈
-
数据摄取
- 批量摄取(定期批量加载)
- 流摄取(实时连续)
- API 集成
- 文件上传和传输
-
数据存储
- 数据湖存储原始数据
- 数据仓库存储已处理数据
- 分布式存储系统
- 云存储(可扩展、成本效益高)
-
数据处理
- 清洁和验证
- 转换和丰富
- 聚合和汇总
- 机器学习和 AI 分析
-
洞察和行动
- 仪表板和可视化
- 报告和警报
- 预测模型
- 自动决策和行动
技术栈示例
大数据在泰国的实际应用
1. 大规模泰语文档处理
使用 Thai OCR APIs:
- 处理数百万张泰国身份证、��护照、文档
- 自动提取结构化数据
- 实现大规模身份验证
- 构建可搜索的文档档案
2. 语音数据分析
使用 Speech-to-Text:
- 转录数千条呼叫中心录音
- 大规模分析客户情绪
- 从语音数据中提取洞察
- 构建可搜索的音频档案
3. 泰语文本分析
使用 OpenThai Chinda:
- 分析数百万条泰语社交媒体帖子
- 提取情绪和主题
- 大规模理解客户反馈
- 从非结构化文本生成洞察
4. 多语言数据处理
使用 Translation API:
- 处理多种语言的数据
- 标准化多语言内容
- 实现跨语言分析
- 进入国际市场
5. 法律文档分析
使用 Thanoy Legal AI:
- 分析大量法律文档
- 提取关键条款和条件
- 识别合同中的模式
- 自动化法律研究
使用 iApp 构建大数据解决方案
iApp Technology 提供将非结构化数据转换为结构化洞察的 AI API:
可用组件
| 数据类型 | iApp 产品 | 大数据用例 |
|---|---|---|
| 泰语文档 | Thai OCR APIs | 大规模文档数字化 |
| 泰语音频 | Speech-to-Text | 语音数据分析 |
| 泰语文本 | OpenThai Chinda | 文本分析和 NLP |
| 图像/人脸 | Face Recognition | 视觉数据处理 |
| 多语言 | Translation API | 跨语言数据 |
| 法律文档 | Thanoy Legal AI | 法律文档分析 |
示例:文档处理管道
import requests
from concurrent.futures import ThreadPoolExecutor
def process_thai_document(document_path):
"""
处理泰语文档并提取结构化数据
"""
with open(document_path, 'rb') as f:
response = requests.post(
'https://api.iapp.co.th/thai-national-id-ocr/v3',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': f}
)
return response.json()
def batch_process_documents(document_list):
"""
并行处理多个文档以实现大数据规模
"""
results = []
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [
executor.submit(process_thai_document, doc)
for doc in document_list
]
for future in futures:
results.append(future.result())
return results
# 示例:处理 1000 个文档
documents = ['doc1.jpg', 'doc2.jpg', ...] # 您的文档列表
structured_data = batch_process_documents(documents)
# 现在您有了准备分析的结构化数据!
# 存储到数据库、数据仓库或数据湖
示例:语音分析管道
import requests
def transcribe_and_analyze(audio_file):
"""
转录音频并用 LLM 分析
"""
# 步骤 1:转录泰语音频
with open(audio_file, 'rb') as f:
stt_response = requests.post(
'https://api.iapp.co.th/thai-speech-to-text/v2',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': f}
)
transcript = stt_response.json()['transcript']
# 步骤 2:用 LLM 分析
analysis_response = requests.post(
'https://api.iapp.co.th/v3/llm/deepseek-v4/chat/completions',
headers={
'apikey': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
json={
'model': 'deepseek-v4-flash',
'messages': [{
'role': 'user',
'content': f"""分析这段对话:
{transcript}
总结:
1. 主要话题
2. 客户情绪(正面/负面/中性)
3. 问题或投诉
4. 建议的行动"""
}],
'max_tokens': 512
}
)
return {
'transcript': transcript,
'analysis': analysis_response.json()['choices'][0]['message']['content']
}
开始使用大数据
步骤 1:识别您的数据源
您有什么数据?
- 客户交易
- 网站/应用行为
- 文档和文件
- 通话录音
- 社交媒体提及
步骤 2:定义您的目标
您需要什么洞察?
- 客户理解
- 运营效率
- 风险管理
- 收入优化
步骤 3:从小处开始,逐步扩大
不要试图一步到位:
- 选择一个用例
- 用试点证明价值
- 在成功基础上构建
- 逐步扩展
步骤 4:使用 AI 解锁非结构化数据
将原始数据转化为洞察:
- 使用 Thai OCR 处理文档
- 使用 Speech-to-Text 处理音频
- 使用 OpenThai Chinda 进行文本分析
资源
大数据的未来
值得关注的趋势
- AI 驱动的分析: 机器学习自动理解复杂数据
- 实时一切: 即时洞察而非批处理
- 边缘计算: 在数据生成处附近处理数据
- 数据网格: 去中心化的数据所有权和治理
- 隐私保护分析: 在保护隐私的同时获取洞察
为什么泰国企业应该现在行动
- 数据在增长: 泰国数字经济产生的数据比以往任何时候都多
- 竞争压力: 竞争对手正在投资数据能力
- AI 可访问性: 像 iApp API 这样的工具使 AI 分析变得可访问
- 客户期望: 客户期望个性化、数据驱动的体验
- 合规准备: PDPA 合规要求了解您的数据
结论
大数据不仅仅是拥有大量信息——而是将这些信息转化为可操作的洞察,以推动更好的决策。从理解客户到优化运营,大数据能力已成为竞争性企业的必需品。
许多泰国企业面临的挑战是,他们大部分有价值的数据被锁在非结构化格式中:泰语文档、语音录音、图像和文本。这正是 iApp Technology 的 AI API 大放异彩的地方——大规模地将非结构化泰语数据转换为结构化洞察。
借助 Thai OCR 处理文档、Speech-to-Text 进行语音分析、OpenThai Chinda 进行文本分析,以及 Translation 处理多语言数据——泰国企业拥有解锁其大数据价值的工具。
准备好将您的数据转化为洞察了吗? 免费注册 并立即开始大规模处理泰语数据!
有问题吗? 加入我们的 Discord 社区 或发送邮件至 support@iapp.co.th�。
iApp Technology Co., Ltd. 泰国领先的 AI 技术公司