什么是泰国文档OCR?完整初学者指南

作者:Kobkrit Viriyayudhakorn博士,iApp Technology CEO兼创始人
您是否想过应用程序如何能够即时读取您的泰国身份证或护照?银行如何通过您文档的照片来验证您的身份?这背后的魔法叫做OCR - 光学字符识别。在本指南中,我们将用简单的术语解释您需要了解的关于泰国文档OCR的一切。
什么是OCR?
**OCR(光学字符识别)**是一种将文本图像转换为机器可读文本数据的技术。可以把它想象成教计算机像人类一样"阅读"。
简单类比
想象一下您有一张泰国身份证的照片。人类可以很容易地读出姓名、地址和身份证号码。OCR技术使计算机能够做同样的事情——查看图像并自动提取所有文本信息。
是什么让泰语OCR特别?
泰语OCR比英语OCR更具挑战性,因为:
- 复杂的文字系统:泰语有44个辅音、32个元音和5个��声调
- 没有词间空格:泰语文本在单词之间没有空格
- 堆叠字符:元音和声调标记堆叠在辅音的上方/下方
- 混合语言:泰语文档通常同时包含泰语和英语文本
这就是为什么像iApp这样的专业泰语OCR解决方案对于获得准确结果至关重要。
您需要知道的5个关键术语
在深入之前,让我们澄清一些经常让初学者困惑的OCR术语:
1. 准确率(Accuracy Rate)
准确率衡量OCR系统读取文本的正确程度,通常以百分比表示。
| 级别 | 描述 | 示例 |
|---|---|---|
| 字符级 | 每个字符的准确率 | 98.13%(iApp泰国身份证OCR) |
| 字段级 | 每个数据字段的准确率 | 96.82%(账号) |
| 文档级 | 整体文档准确率 | 95%+(清晰图像) |
**为什么重要:**更高的准确率意味着更少的错误和更少的手动更正。
2. 边界框(Bounding Box)
边界框是一个矩形,用于标识文本在图像中的位置。
图像坐标:[x1, y1, x2, y2]
示例:[119, 292, 376, 334] = 文本位置
**为什么重要:**边界框帮助您准确了解每条信息在文档中的位置。
3. 预处理(Preprocessing)
预处理是在OCR分析之前对图像的准备。常见步骤包括:
- 裁剪:移除图像中不必要的部分
- 旋转:修正倾斜的文档
- 去倾斜:矫正倾斜的文字
- 增强:改善对比度和清晰度
**为什么重要:**良好的预处理可以显著提高OCR准确率。
4. 置信度分数(Confidence Score)
置信度分数表示OCR系统对其读取结果的确定程度,通常从0到1(或0%到100%)。
{
"id_number": "1234567890123",
"detection_score": 0.98 // 98%置信度
}
**为什么重要:**低置信度分数表明结果应该手动验证。
5. 结构化数据输出(Structured Data Output)
结构化数据输出是提取信息的组织格式,通常是JSON。
{
"th_name": "นาย ทดสอบ ตัวอย่าง",
"en_name": "Mr. Test Example",
"id_number": "1-2345-67890-12-3",
"date_of_birth": "01 Jan 1990",
"address": "123 ถนนสุขุมวิท กรุงเทพฯ"
}
**为什么重要:**结构化数据可以直接在您的应用程序中使用,无需额外解析。
为什么泰国文档OCR很重要?
1. 数字化转型
泰国正在快速将政府和商业服务数字化。OCR实现了:
- 无纸化注册
- 数字身份验证
- 自动化文档处理
2. 节省时间和成本
手动数据输入既慢又昂贵:
| 方法 | 每份文档时间 | 错误率 |
|---|---|---|
| 手动输入 | 2-5分钟 | 1-3% |
| OCR API | 1-2秒 | 低于2% |
3. E-KYC合规
泰国法规要求企业验证客户身份。OCR实现了:
- 即时身份验证
- 符合PDPA的数据处理
- 反欺诈措施
4. 改善客户体验
客户期望快速的数字服务:
- 不再需要手动填写表格
- 即时开户
- 无缝注册
泰国文档OCR解决什么问题?
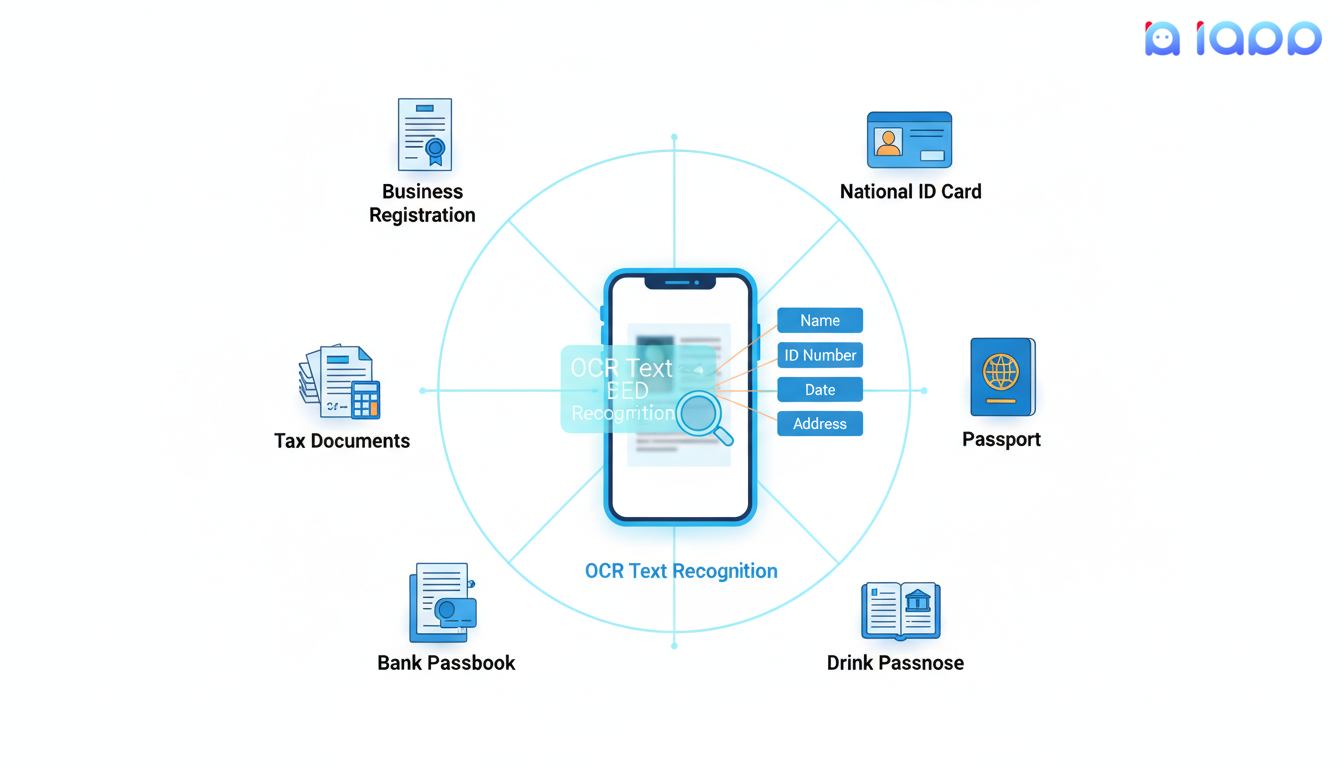
银行和金融
- 开户:从身份证提取客户信息
- 贷款申请:自动处理收入文档
- KYC验证:即时验证身份证件
保险
- 理赔处理:读取事故报告和医疗文档
- 保单注册:从身份证捕获客户数据
- 欺诈检测:验证文档真实性
医疗保健
- 患者注册:从国民身份证提取数据
- 保险理赔:处理健康保险文档
- 医疗记录:将纸质记录数字化
政府服务
- 公民服务:简化文档提交
- 税务处理:读取税务文档和收据
- 许可证验证:验证驾照和许可证
电子商务和物流
- 卖家验证:验证商家身份
- 地址提取:读取运输标签
- 退货处理:处理退货文档
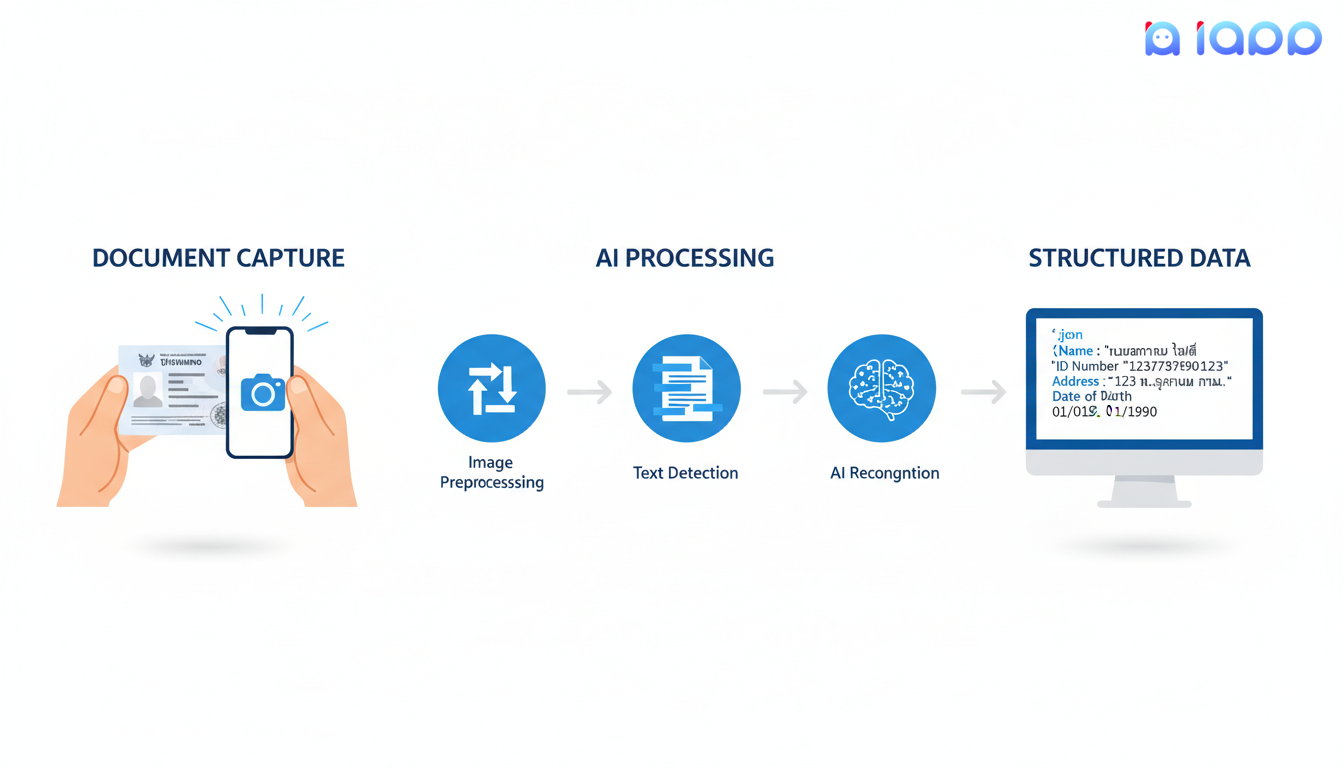
泰国文档OCR如何工作?
让我们逐步分解OCR过程:
步骤1:文档捕获
过程从通过以下方式捕获文档图像开始:
- 智能手机相机
- 扫描仪
- 上传的图像文件
步骤2:图像预处理
系统为分析准备图像:
- 自动旋转:修正倾斜的图像
- 裁剪:移除背景
- 增强:改善文字可见性
- 降噪:移除伪影
步骤3:文字检测
AI识别图像中文字的位置:
- 定位文字区域
- 创建边界框
- 识别字段类型(姓名、身份证号等)
步骤4:字符识别
核心OCR引擎读取文字:
- 分析每个字符
- 使用在泰语文本上训练的深度学习模型
- 同时处理泰语和英语字符
步骤5:后处理
系统完善结果:
- 拼写检查
- 格式验证(例如13位身份证号)
- 数据结构化
步骤6:输出生成
最终结构化数据以JSON格式返回。
如何使用泰国文档OCR
方法1:网页演示
直接在我们的网站上试用iApp的OCR——无需编码!
- 访问 泰国身份证OCR演示
- 上传图像
- 即时查看结果
方法2:API集成
对于开发者,通过REST API集成OCR:
import requests
# 泰国身份证OCR
url = "https://api.iapp.co.th/v3/store/ekyc/thai-national-id-card/front"
files = {"file": open("id_card.jpg", "rb")}
headers = {"apikey": "YOUR_API_KEY"}
response = requests.post(url, headers=headers, files=files)
result = response.json()
print(f"姓名: {result['th_name']}")
print(f"身份证号: {result['id_number']}")
print(f"地址: {result['address']}")
方法3:移动SDK
对于移动应用,使用我们的iOS和Android SDK,内置相机捕获和实时处理功能。
泰国文档OCR示例
示例1:泰国国民身份证OCR
输入:泰国国民身份证照片(正面)
输出:
{
"id_number": "1-2345-67890-12-3",
"th_name": "นาง ทดสอบ ตัวอย่าง",
"en_name": "Mrs. Test Example",
"th_dob": "15 ม.ค. 2533",
"en_dob": "15 Jan 1990",
"address": "123/45 ถ.สุขุมวิท แขวงคลองตัน เขตวัฒนา กรุงเทพฯ",
"province": "กรุงเทพมหานคร",
"detection_score": 0.98,
"process_time": 1.2
}
用例:E-KYC、开户、身份验证
示例2:护照OCR
输入:护照个人信息页照片
输出:
{
"type": "P",
"country": "THA",
"surname": "EXAMPLE",
"names": "TEST",
"number": "AA1234567",
"nationality": "THA",
"date_of_birth": "900115",
"sex": "F",
"expiration_date": "300114",
"personal_number": "1234567890123",
"valid_score": 100
}
用例:旅行预订、出入境、国际KYC
示例3:泰国驾照OCR
输入:泰国驾照照片
输出:
{
"license_number": "12345678",
"th_name": "นาย ทดสอบ ตัวอย่าง",
"en_name": "Mr. Test Example",
"date_of_birth": "15/01/1990",
"expiry_date": "15/01/2030",
"license_type": "รถยนต์ส่วนบุคคล",
"province": "กรุงเทพมหานคร"
}
用例:汽车租赁、网约车验证、年龄验证
示例4:银行存折OCR
输入:泰国银行存折照片
输出:
{
"bank_name": "ธนาคารไทยพาณิชย์",
"account_number": "123-4-56789-0",
"account_name": "นาย ทดสอบ ตัวอย่าง",
"bank_branch": "สาขาสยามพารากอน",
"signature_detected": true
}
用例:支付验证、贷款处理、账户关联
iApp Technology的泰国文档OCR服务
在iApp Technology,我们为泰国文档提供全面的OCR解决方案:
泰国国民身份证OCR
- 准确率:98.13%(字符级)
- 速度:1-2秒
- 价格:1.25 IC每次请求(正面)
- 试用演示
护照OCR
- 准确率:95.51%
- 支持:全球所有MRZ护照
- 价格:0.75 IC每页
- 试用演示
泰国驾照OCR
- 字段:驾照号码、姓名、到期日、类型
- 价格:1.25 IC每次请求
- 试用演示
泰国银行存折OCR
- 支持:所有主要泰国银行
- 准确率:93%(整体)
- 价格:1.25 IC每页
- 试用演示
其他OCR服务
- 扣税凭证
- 民事登记证明
- 车牌识别
- 电表/水表读数
- 简历/履历解析
开始使用iApp OCR APIs
步骤1:创建免费账户
访问 iapp.co.th/register 创建您的账户。
步骤2:获取API密钥
前往 API密钥管理 生成您的密钥。
步骤3:选择OCR服务
从我们的文档中选择您需要处理的文档类型。
步骤4:进行第一次API调用
curl -X POST "https://api.iapp.co.th/v3/store/ekyc/thai-national-id-card/front" \
-H "apikey: YOUR_API_KEY" \
-F "file=@id_card.jpg"
步骤5:集成并上线
使用我们的Python、JavaScript、PHP、Swift、Kotlin、Java和Dart代码示例。
泰国文档OCR最佳实践
图像质量技巧
- 良好照明:避免阴影和眩光
- 平整表面:保持文档平整
- 完整画面:捕获整个文档
- 高分辨率:建议最低300 DPI
- 清晰对焦:避免模糊图像
集成技巧
- 处理错误:检查响应中的错误代码
- 验证置信度:手动审查低置信度结果
- 重试逻辑:为网络故障实现重试
- 安全存储:不要存储敏感文档图像
合规技巧
- 用户同意:在捕获文档前获得许可
- 数据最小化:只提取需要的字段
- PDPA合规:遵守泰国数据保护法
- 审计日志:保留OCR操作记录
总结
泰国文档OCR正在改变泰国企业处理文档的方式。以下是我们涵盖的内容:
- OCR将文档图像转换为结构化的、机器可读的数据
- 关键术语:准确率、边界框、预处理、置信度分数、结构化数据
- 应用:银行、保险、医疗保健、政府、电子商务
- 泰语OCR挑战:复杂文字、无词间空格、混合语言
- iApp解决方案:身份证、护照、驾照、银行存折OCR
泰国企业的数字化转型依赖于准确、快速的文档处理——而OCR使这成为可能。
准备好尝试泰国文档OCR了吗?
今天就开始数字化您的文档工作流程:
- 创建免费账户 - 几分钟内即可开始
- 试用泰国身份证OCR - 我们最受欢迎的API
- 探索所有OCR APIs - 完整文档
- 联系我们 - 企业解决方案
有问题吗?加入我们的Discord社区或发送电子邮件至support@iapp.co.th。
iApp Technology Co., Ltd. 泰国领先的AI公司