什么是小型语言模型(SLM)?初学者完整指南

每个人都在谈论大型语言模型(LLM),如GPT-4和Claude。但越来越多人开始关注它们更小、更高效的兄弟:小型语言模型(SLM)。这些紧凑的AI模型正在彻底改变我们在实际应用中部署AI的方式。让我们探索它们是什么以及为什么重要。
什么是小型语言模型(SLM)?
小型语言模型(SLM)是参数数量明显少于大型模型的语言模型——通常在10亿到100亿参数之间。尽管体积较小,SLM被设计为在需要较少计算资源的同时高效地执行特定任务。
这样理解:LLM就像有100种工具的瑞士军刀——功能强大但笨重。SLM就像精密螺丝刀——专注、高效,非常适合特定工作。
SLM的关键特点
| 特点 | 小型语言模型(SLM) | 大型语言模型(LLM) |
|---|---|---|
| 参数 | 1B - 10B | 70B - 1T+ |
| 所需内存 | 2-16 GB | 100GB+ |
| 速度 | 快(毫秒级) | 较慢(秒级) |
| 成本 | 低 | 高 |
| 部署 | 设备端、边缘 | 云端 |
| 专业化 | 特定任务 | 通用 |
SLM vs LLM:理解差异
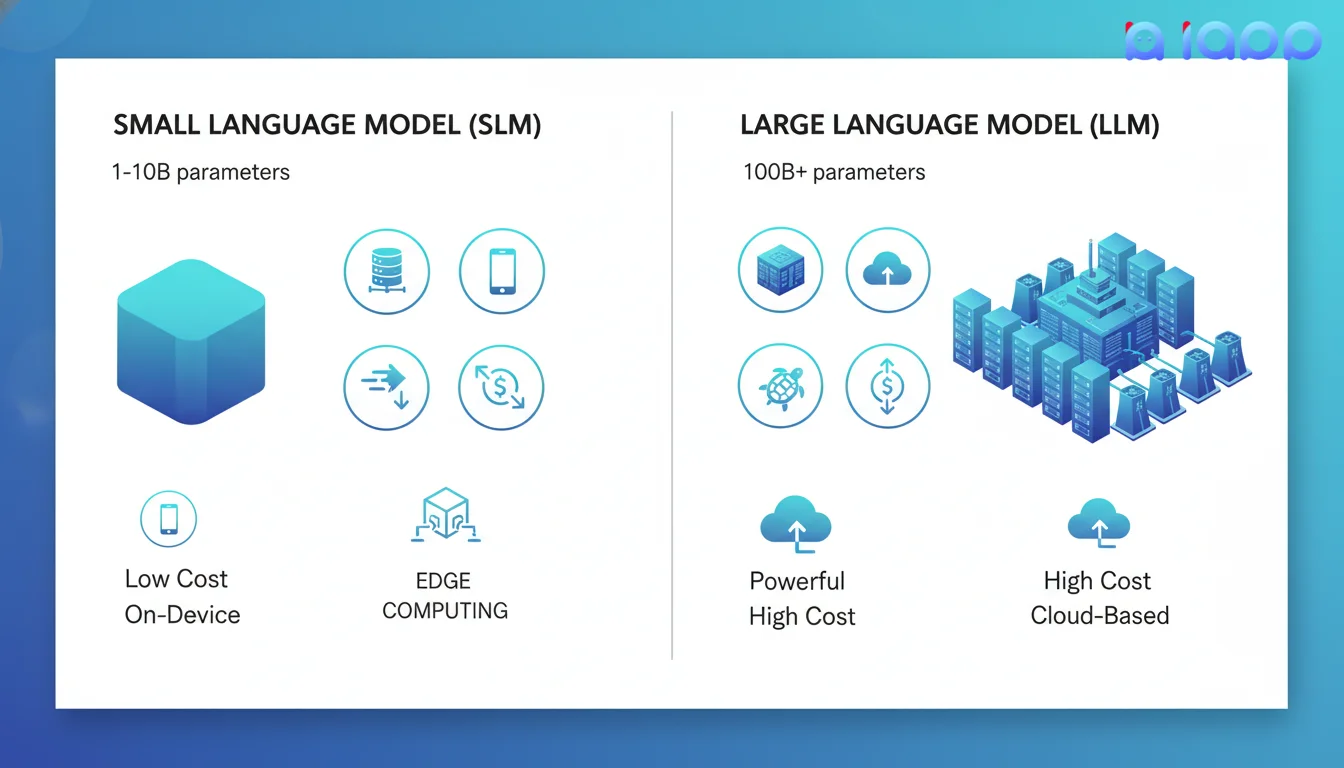
何时使用SLM vs LLM
选择SLM当:
- 速度至关重要(实时响应)
- 在资源有限的设备上运行
- 隐私至上(数据留在设备上)
- 需要成本优化
- 执行特定的、明确定义的任务
选择LLM当:
- 需要复杂推理
- 多步骤问题解决
- 创意写作和头脑风暴
- 通用助手
- 处理多样化、不可预测的查询
小型语言模型的类型
1. 通用SLM
可以合理处理各种任务的紧凑模型。
- 示例: Phi-3、Gemma 2B、Llama 3.2 1B
- 用例: 聊天机器人、文本摘要、简单问答
2. 领域特定SLM
为特定行业或任务微调的模型。
- 示例: Chinda泰语LLM(泰语)、CodeGemma(编程)
- 用例: 泰语客服、代码补全、医疗分诊
3. 蒸馏模型
训练来模仿大型模型行为的小型模型。
- 示例: DistilBERT、TinyLlama
- 用例: 快速推理、移动部署
4. 量化模型
压缩以高效运行的全尺寸模型。
- 示例: GGUF格式模型、4位量化版本
- 用例: 本地部署、边缘设备
5. 多模态SLM
处理文本和其他模态的小型模型。
- 示例: PaliGemma、LLaVA-Phi
- 用例: 图像描述、移动端视觉问答
小型语言模型的5个用例
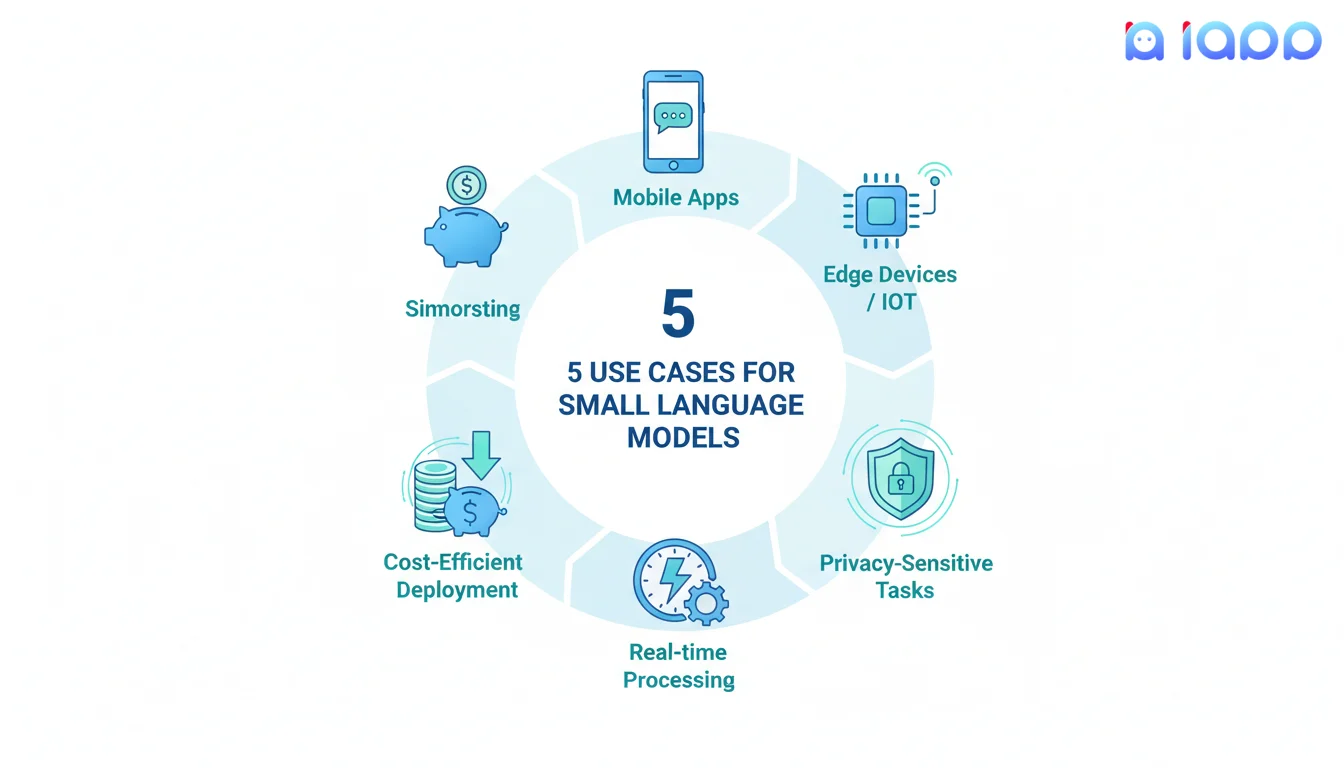
1. 移动应用
直接在智能手机上运行AI,无需互联网。
- 示例: 设备端文本预测、智能撰写
- 优势: 离线工作、即时响应
2. 边缘设备和物联网
在传感器、摄像头和嵌入式系统上部署AI。
- 示例: 智能家居语音助手、工业监控
- 优势: 无云延迟、本地处理
3. 隐私敏感任务
将数据保留在本地以符合合规性和安全性要求。
- 示例: 医疗聊天机器人、金融文档分析
- 优势: 数据永不离开设备
4. 实时处理
为�时间关键型应用获得即时响应。
- 示例: 实时翻译、实时转录
- 优势: 毫秒级响应时间
5. 经济高效的部署
扩展AI而无需巨额云账单。
- 示例: 中小企业客户服务自动化
- 优势: 与云LLM相比成本降低10-100倍
AI关键术语解释(术语大全)
1. 参数(Parameters)
是什么: 存储在模型中的"知识"——决定模型如何响应的数字。
简单类比: 把参数想象成脑细胞。更多的细胞可以存储更多信息,但也需要更多能量。
为什么重要: SLM有1-10B参数 vs LLM有70B-1T+参数。
2. 量化(Quantization)
是什么: 通过降低参数精度来压缩模型(例如,从32位降到4位数字)。
简单类比: 就像将照片从RAW压缩到JPEG——文件更小,细节略少,但仍然有用。
为什么重要: 7B模型通常需要14GB RAM。量化到4位后只需要4GB。
3. 蒸馏(Distillation)
是什么: 训练小型模型来模仿大型模型的行为。
简单类比: 学生(SLM)向大师老师(LLM)学习——捕捉精髓而不需要相同的资源。
为什么重要: 创建高效模型,同时保留原始模型的大部分能力。
4. 边缘计算(Edge Computing)
是什么: 在设备本地处理数据而不是发送到云端。
简单类比: 在家做饭vs点外卖——更快、更私密,但菜单选择有限。
为什么重要: SLM使边缘AI成为可能——在手机、摄像头和物联网设备上。
5. 推理(Inference)
是什么: 运行训练好的模型以获得预测或响应的过程。
简单类比: 使用训练有素的厨师(模型)根据订单(提示)做饭(生成输出)。
为什么重要: SLM提供比LLM更快、更便宜的推理。
为什么小型语言模型很重要
1. 使AI人人可及
并非每个人都能负担昂贵的GPU服务器或云API。SLM使:
- 小企业能够以实惠的价格部署AI
- 开发者可以在笔记本电脑上运行模型
- 学生可以在没有云成本的情况下进行实验
2. 隐私和数据主权
使用SLM,你的数据保持本地:
- 不会将敏感数据发送到外部服务器
- 符合PDPA、GDPR和当地法规
- 完全控制你的AI交互
3. 减少环境影响
SLM需要更少的能源:
- 每次推理的碳足迹更低
- 大规模可持续AI部署
- 绿色计算倡议
4. 真实世界部署
许多实际应用需要SLM:
- 移动应用�不能依赖持续连接
- 边缘设备计算能力有限
- 生产系统需要可预测的延迟
小型语言模型如何工作
训练过程
- 从架构开始: 设计紧凑的神经网络
- 预训练: 从大型文本数据集学习(通用知识)
- 微调: 为特定任务或语言专业化
- 优化: 应用量化、剪枝或蒸馏
- 部署: 为目标平台打包(移动端、边缘、服务器)
运行SLM
当你向SLM发送提示时:
- 分词: 文本转换为数字
- 嵌入: 数字变为向量
- 处理: 向量通过神经网络层
- 生成: 模型预测下一个词元
- 输出: 词元转换回文本
关键区别在于SLM有更少的层和更小的维度,使每个步骤更快。
泰国的小型语言模型
Chinda泰语LLM:泰国的开源SLM
Chinda是由iApp Technology专门为泰语开发的40亿参数模型:
关键特点:
- 泰语优化: 在泰语文本上微调以获得自然响应
- 紧凑: 只有4B参数——可在消费级硬件上运行
- 开源: 在Hugging Face上可用
- 免费API: 直到2025年12月31日免费
为什么Chinda非常适合泰语应用:
- 理解泰语语法和语气词(ครับ/ค่ะ)
- 处理泰英混用
- 文化背景意识
- 可本地部署
示例:本地运行Chinda
你可以使用以下工具在自己的电脑上运行Chinda:
示例:使用iApp的DeepSeek V4 API
import requests
response = requests.post(
'https://api.iapp.co.th/v3/llm/deepseek-v4/chat/completions',
headers={
'apikey': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
json={
'model': 'deepseek-v4-flash',
'messages': [
{'role': 'user', 'content': 'อธิบายความแตกต่างระหว่าง SLM และ LLM'}
],
'max_tokens': 1024
}
)
print(response.json())
泰国的实际应用
1. 泰语客服聊天机器人
在你的服务器上部署Chinda来处理泰语客户查询:
- 无按请求API成本
- 完全数据隐私
- 离线或隔离环境中工作
2. 泰语文档处理
将SLM与泰语OCR结合:
- 从泰语文档提取文本
- 本地摘要或分类内容
- 处理敏感文档而不暴露于云端
3. 移动端泰语语音助手
- 设备端语音交互
- 实时泰语语音识别
- 自然泰语语音合成
4. 泰国零售边缘AI
在店内服务器上部署:
- 无需互联网的产品推荐
- AI库存管理
- 保护隐私的客户分析
开始使用小型语言模型
选项1:使用iApp的DeepSeek V4 API(最简单)
- 创建账户: 访问iApp.co.th
- 获取API密钥: 前往API密钥管理
- 开始构建: 使用简单的REST API
- 成本: 按 Token 计费,0.01 IC/1K Token 起
选项2:本地运行(最私密)
- 下载模型: 从Hugging Face获取Chinda
- 安装运行时: 使用LM Studio或Ollama
- 本地运行: 无需互联网
- 成本: 仅你的硬件
选项3:本地部署(企业)
- 联系iApp: 联系我们
- 自定义设置: 根据你的基础设施定制
- 支持: 企业级SLA和培训
- 成本: 一次性许可证 + 支持
iApp AI模型比较
| 模型 | 类型 | 参数 | 最适合 | 定价 |
|---|---|---|---|---|
| Chinda泰语LLM 4B | SLM | 4B | 泰语聊天机器人、本地部署 | 免费 |
| DeepSeek-V3.2 | LLM | 685B | 复杂推理、编程 | 0.01 IC/1K词元 |
| Thanoy法律AI | 领域SLM | - | 泰语法律文档 | 按词元计费 |
小型语言模型的未来
值得关注的趋势
- 设备端AI: 每部智能手机都将拥有强大的SLM
- 专业模型: 行业特定SLM(医疗、法律、金融)
- 混合系统: SLM处理简单查询,LLM处理复杂查询
- 更高效率: 更少参数实现相同能力
- 泰语重点: 更多为泰语优化的模型
为什么这对泰国企业很重要
- 成本节省: 减少90%+的AI基础设施成本
- 数据主权: 将泰国数据保留在泰国
- 竞争优势: 比竞争对手更快部署AI
- 创新: 构建仅靠云AI无法实现的产品
结论
小型语言模型代表了AI部署的根本转变——从集中式云计算到分布式、高效、保护隐私的AI。它们不是LLM的替代品,而是补充,使AI能够在大型模型无法触及的场景中工作。
对于泰国企业和开发者来说,像Chinda这样的SLM提供了前所未有的机会,可以构建快速、实惠且尊重用户隐私的AI驱动应用。
准备好开始了吗? 免费注册,试用Chinda泰语LLM——泰国自己的小型语言模型!
有问题? 加入我们的Discord社区或发送电子邮件至support@iapp.co.th。
iApp Technology Co., Ltd. 泰国领先的AI技术公司