Small Language Model (SLM) คืออะไร? คู่มือฉบับสมบูรณ์สำหรับผู้เริ่มต้น

ทุกคนพูดถึง Large Language Models (LLMs) เช่น GPT-4 และ Claude แต่มีกระแสที่เติบโตขึ้นสำหรับน้องเล็กที่มีประสิทธิภาพกว่า: Small Language Models (SLMs) โมเดล AI ขนาดกะทัดรัดเหล่านี้กำลังปฏิวัติวิธีที่เราใช้งาน AI ในแอปพลิเคชันจริง มาสำรวจกันว่ามันคืออะไรและทำไมจึงสำคัญ
Small Language Model (SLM) คืออะไร?
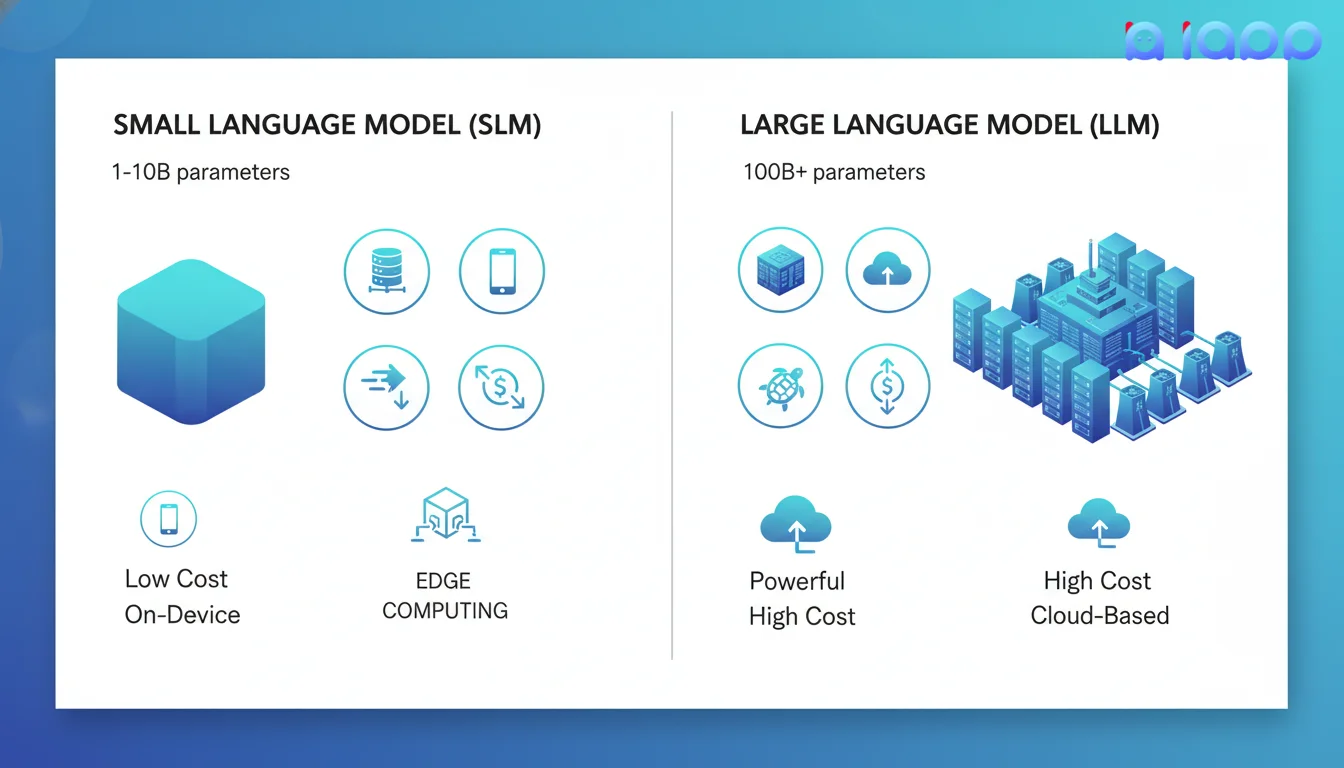
Small Language Model (SLM) คือโมเดลภาษาที่มีพารามิเตอร์น้อยกว่าโมเดลขนาดใหญ่อย่างมาก - โดยทั่วไปอยู่ในช่วง 1 พันล้านถึง 10 พันล้านพารามิเตอร์ แม้จะมีขนาดเล็กกว่า SLMs ถูกออกแบบมาเพื่อทำงานเฉพาะอย่างมีประสิทธิภาพในขณะที่ต้องการทรัพยากรการคำนวณน้อยกว่า
ลองคิดแบบนี้: LLM เหมือนมีดพับสวิสที่มี 100 เครื่องมือ - ทรงพลังแต่เทอะทะ SLM เหมือนไขควงแม่นยำ - มุ่งเน้น มีประสิทธิภาพ และเหมาะสำหรับงานเฉพาะทาง
คุณสมบัติหลักของ SLMs
| คุณสมบัติ | Small Language Model (SLM) | Large Language Model (LLM) |
|---|---|---|
| พารามิเตอร์ | 1B - 10B | 70B - 1T+ |
| หน่วยความจำที่ต้องการ | 2-16 GB | 100GB+ |
| ความเร็ว | เร็ว (มิลลิวินาที) | ช้ากว่า (วินาที) |
| ค่าใช้จ่าย | ต่ำ | สูง |
| การติดตั้ง | บนอุปกรณ์, Edge | บนคลาวด์ |
| ความเชี่ยวชาญ | เฉพาะงาน | อเนกประสงค์ |
SLM vs LLM: เข้าใจความแตกต่าง
เมื่อไหร่ควรใช้ SLM vs LLM
เลือก SLM เมื่อ:
- ความเร็วสำคัญมาก (ตอบสนองแบบเรียลไทม์)
- รันบนอุปกรณ์ที่มีทรัพยากรจำกัด
- ความเป็นส่วนตัวสำคัญที่สุด (ข้อมูลอยู่บนอุปกรณ์)
- ต้องการลดค่าใช้จ่าย
- ทำงานเฉพาะที่ชัดเจน
เลือก LLM เมื่อ:
- ต้องการการให้เหตุผลที่ซับซ้อน
- การแก้ปัญหาหลายขั้นตอน
- งานเขียนสร้างสรรค์และระดมความคิด
- ผู้ช่วยอเนกประสงค์
- รับมือคำถามที่หลากหลายและคาดเดาไม่ได้
ประเภทของ Small Language Models
1. SLMs อเนกประสงค์
โมเดลกะทัดรัดที่สามารถจัดการงานต่างๆ ได้ดีพอสมควร
- ตัวอย่าง: Phi-3, Gemma 2B, Llama 3.2 1B
- กรณีใช้งาน: แชทบอท สรุปข้อความ Q&A ง่ายๆ
2. SLMs เฉพาะทาง
โมเดลที่ fine-tune สำหรับอุตสาหกรรมหรืองานเฉพาะ
- ตัวอย่าง: OpenThai Chinda (ภาษาไทย), CodeGemma (เขียนโค้ด)
- กรณีใช้งาน: บริการลูกค้าภาษาไทย เขียนโค้ดอัตโนมัติ คัดกรองทางการแพทย์
3. Distilled Models
โมเดลขนาดเล็กที่ฝึกให้เลียนแบบพฤติกรรมของโมเดลใหญ่
- ตัวอย่าง: DistilBERT, TinyLlama
- กรณีใช้งาน: inference เร็ว ติดตั้งบนมือถือ
4. Quantized Models
โมเดลขนาดเต็มที่ถูกบีบอัดให้รันได้อย่างมีประสิทธิภาพ
- ตัวอย่าง: โมเดลรูปแบบ GGUF รุ่น 4-bit quantized
- กรณีใช้งาน: ติดตั้งในเครื่อง อุปกรณ์ edge
5. Multimodal SLMs
โมเดลขนาดเล็กที่จัดการข้อความรวมถึงรูปแบบอื่น
- ตัวอย่าง: PaliGemma, LLaVA-Phi
- กรณีใช้งาน: บรรยายภาพ ถาม-ตอบภาพบนมือถือ
5 กรณีใช้งานของ Small Language Models
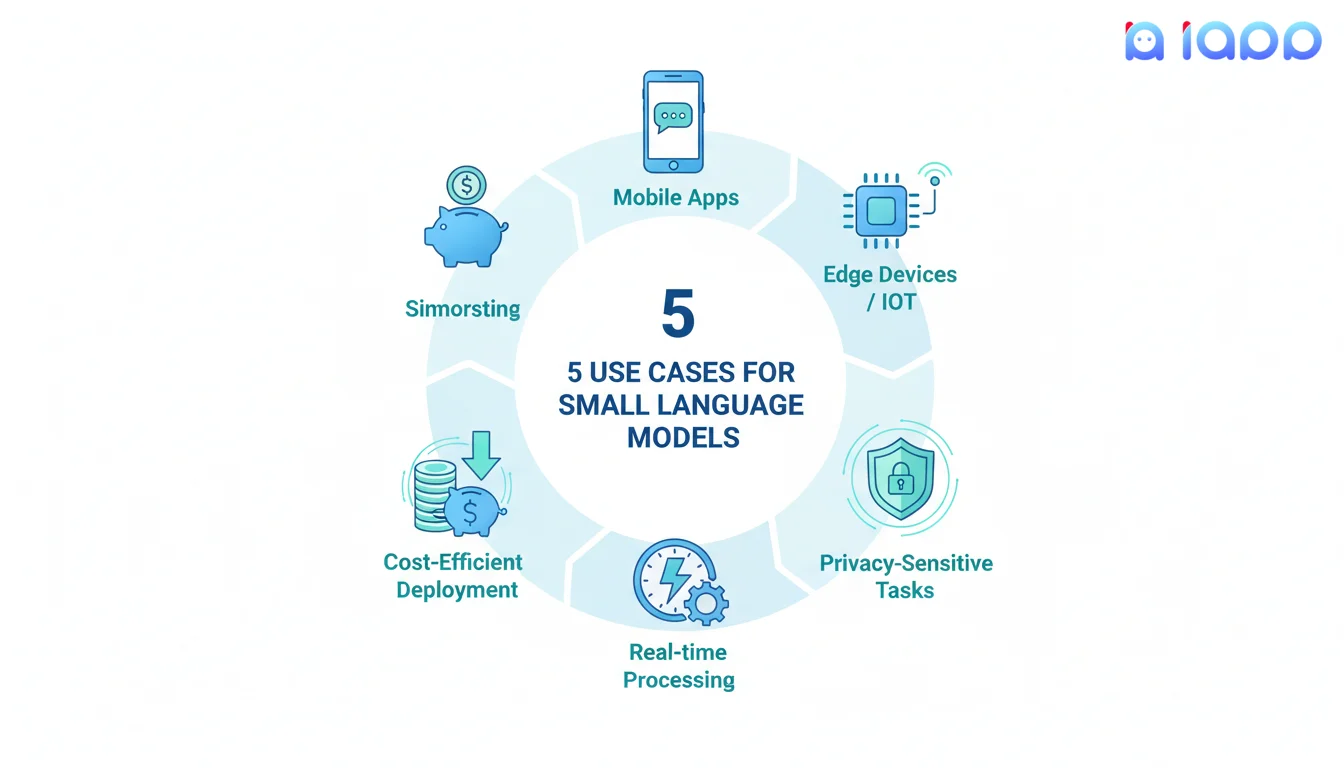
1. แอปพลิเคชันมือถือ
รัน AI โดยตรงบนสมาร์ทโฟนโดยไม่ต้องใช้อินเทอร์เน็ต
- ตัวอย่าง: การทำนายข้อความบนอุปกรณ์ smart compose
- ประโยชน์: ใช้งานออฟไลน์ได้ ตอบสนองทันที
2. อุปกรณ์ Edge & IoT
ติดตั้ง AI บนเซ็นเซอร์ กล้อง และระบบฝังตัว
- ตัวอย่าง: ผู้ช่วยเสียงบ้านอัจฉริยะ การตรวจสอบอุตสาหกรรม
- ประโยชน์: ไม่มีความล่าช้าจากคลาวด์ ประมวลผลในเครื่อง
3. งานที่ต้องการความเป็นส่วนตัว
เก็บข้อมูลไว้ในองค์กรเพื่อการปฏิบัติตามกฎหมายและความปลอดภัย
- ตัวอย่าง: แชทบอทด้านสุขภาพ วิเคราะห์เอกสารทางการเงิน
- ประโยชน์: ข้อมูลไม่ออกจากอุปกรณ์
4. การประมวลผลแบบเรียลไทม์
รับการตอบสนองทันทีสำหรับแอปพลิเคชันที่เวลาสำคัญ
- ตัวอย่าง: แปลภาษาสด ถอดเสียงเรียลไทม์
- ประโยชน์: เวลาตอบสนองระดับมิลลิวินาที
5. การติดตั้งที่คุ้มค่า
ขยาย AI โดยไม่ต้องจ่ายค่าคลาวด์มหาศาล
- ตัวอย่าง: อัตโนมัติบริการลูกค้าสำหรับ SMEs
- ประโยชน์: ลดค่าใช้จ่าย 10-100 เท่าเทียบกับ cloud LLMs
คำศัพท์ AI สำคัญที่ควรรู้ (อธิบายศัพท์เทคนิค)
1. Parameters (พารามิเตอร์)
คืออะไร: "ความรู้" ที่เก็บในโมเดล - ตัวเลขที่กำหนดว่าโมเดลจะตอบสนองอย่างไร
เปรียบเทียบง่ายๆ: คิดว่าพารามิเตอร์เหมือนเซลล์สมอง เซลล์มากขึ้นเก็บข้อมูลได้มากขึ้น แต่ก็ต้องใช้พลังงานมากขึ้น
ทำไมจึงสำคัญ: SLMs มี 1-10B พารามิเตอร์ vs LLMs มี 70B-1T+ พารามิเตอร์
2. Quantization (การควอนไทซ์)
คืออะไร: การบีบอัดโมเดลโดยลดความแม่นยำของพารามิเตอร์ (เช่น จาก 32-bit เป็น 4-bit)
เปรียบเทียบง่ายๆ: เหมือนบีบอัดรูปจาก RAW เป็น JPEG - ไฟล์เล็กลง รายละเอียดน้อยลงเล็กน้อย แต่ยังใช้งานได้
ทำไมจึงสำคัญ: โมเดล 7B ปกติต้องใช้ RAM 14GB เมื่อ quantize เป็น 4-bit ต้องการแค่ 4GB
3. Distillation (การกลั่น)
คืออะไร: การฝึกโมเดลขนาดเล็กให้เลียนแบบพฤติกรรมของโมเดลขนาดใหญ่
เปรียบเทียบง่ายๆ: นักเรียน (SLM) เรียนรู้จากอาจารย์ผู้เชี่ยวชาญ (LLM) - จับแก่นสารโดยไม่ต้องใช้ทรัพยากรเท่ากัน
ทำไมจึงสำคัญ: สร้างโมเดลที่มีประสิทธิภาพแต่ยังคงความสามารถของต้นฉบับ
4. Edge Computing (การประมวลผลที่ขอบ)
คืออะไร: การประมวลผลข้อมูลในเครื่องบนอุปกรณ์แทนการส่งไปคลาวด์
เปรียบเทียบง่ายๆ: ทำอาหารที่บ้าน vs สั่งเดลิเวอรี่ - เร็วกว่า เป็นส่วนตัวกว่า แต่เมนูมีจำกัด
ทำไมจึงสำคัญ: SLMs ทำให้ AI ที่ edge เป็นไปได้ - บนโทรศัพท์ กล้อง และอุปกรณ์ IoT
5. Inference (การอนุมาน)
คืออะไร: กระบวนการรันโมเดลที่ฝึกแล้วเพื่อรับการทำนายหรือการตอบสนอง
เปรียบเทียบง่ายๆ: ใช้เชฟที่ผ่านการฝึก (โมเดล) ทำอาหาร (สร้างเอาต์พุต) ตามออเดอร์ (prompts)
ทำไมจึงสำคัญ: SLMs ให้ inference ที่เร็วกว่าและถูกกว่า LLMs
ทำไม Small Language Models จึงสำคัญ
1. ทำให้ AI เข้าถึงได้ทุกคน
ไม่ใช่ทุกคนที่สามารถจ่ายค่าเซิร์ฟเวอร์ GPU ราคาแพงหรือ cloud APIs SLMs ทำให้:
- ธุรกิจขนาดเล็กใช้ AI ได้ในราคาจับต้องได้
- นักพัฒนารันโมเดลบนแล็ปท็อปได้
- นักศึกษาทดลองโดยไม่มีค่าใช้จ่ายคลาวด์
2. ความเป็นส่วนตัวและอธิปไตยข้อมูล
ด้วย SLMs ข้อมูลของคุณอยู่ในเครื่อง:
- ไม่ส่งข้อมูลละเอียดอ่อนไปเซิร์ฟเวอร์ภายนอก
- ปฏิบัติตาม PDPA, GDPR และกฎระเบียบท้องถิ่น
- ควบคุมเต็มที่ต่อการโต้ตอบกับ AI
3. ลดผลกระทบต่อสิ่งแวดล้อม
SLMs ใช้พลังงานน้อยกว่า:
- คาร์บอนฟุตพริ้นท์ต่ำกว่าต่อ inference
- การใช้ AI อย่างยั่งยืนในระดับใหญ่
- การริเริ่มการประมวลผลสีเขียว
4. การใช้งานในโลกจริง
แอปพลิเคชันจริงหลายอย่างต้องการ SLMs:
- แอปมือถือไม่สามารถพึ่งพาการเชื่อมต่อตลอดเวลา
- อุปกรณ์ edge มีพลังการคำนวณจำกัด
- ระบบ production ต้องการ latency ที่คาดเดาได้
Small Language Models ทำงานอย่างไร
กระบวนการฝึกสอน
- เริ่มด้วยสถาปัตยกรรม: ออกแบบโครงข่ายประสาทเทียมกะทัดรัด
- Pre-training: เรียนรู้จากชุดข้อมูลข้อความขนาดใหญ่ (ความรู้ทั่วไป)
- Fine-tuning: เชี่ยวชาญสำหรับงานหรือภาษาเฉพาะ
- Optimization: ใช้ quantization, pruning หรือ distillation
- Deployment: แพ็คเกจสำหรับแพลตฟอร์มเป้าหมาย (มือถือ, edge, เซิร์ฟเวอร์)
การรัน SLM
เมื่อคุณส่ง prompt ไปยัง SLM:
- Tokenization: ข้อความถูกแปลงเป็นตัวเลข
- Embedding: ตัวเลขกลายเป็นเวกเตอร์
- Processing: เวกเตอร์ผ่านชั้นของโครงข่ายประสาทเทียม
- Generation: โมเดลทำนาย token ถัดไป
- Output: Token ถูกแปลงกลับเป็นข้�อความ
ความแตกต่างหลักคือ SLMs มีชั้นน้อยกว่าและมิติเล็กกว่า ทำให้แต่ละขั้นตอนเร็วขึ้น
Small Language Models ในประเทศไทย
OpenThai Chinda: SLM โอเพ่นซอร์สของประเทศไทย
Chinda คือโมเดล 4 พันล้านพารามิเตอร์ที่พัฒนาโดย iApp Technology โดยเฉพาะสำหรับภาษาไทย:
คุณสมบัติหลัก:
- ปรับแต่งสำหรับไทย: Fine-tune บนข้อความภาษาไทยเพื่อการตอบสนองที่เป็นธรรมชาติ
- กะทัดรัด: แค่ 4B พารามิเตอร์ - รันบนฮาร์ดแวร์ทั่วไปได้
- โอเพ่นซอร์ส: มีบน Hugging Face
- API ฟรี: ไม่มีค่าใช้จ่ายจนถึง 31 ธันวาคม 2568
ทำไม Chinda เหมาะสำหรับแอปพลิเคชันไทย:
- เข้าใจไวยากรณ์และคำลงท้ายไทย (ครับ/ค่ะ)
- จัดการการสลับภาษาไทย-อังกฤษได้
- มีบริบททางวัฒนธรรม
- สามารถติดตั้งในเครื่องได้
ตัวอย่าง: รัน Chinda ในเครื่อง
คุณสามารถรัน Chinda บนคอมพิวเตอร์ของคุณเองโดยใช้เครื่องมือเช่น:
ตัวอย่าง: ใช้ DeepSeek V4 API ของ iApp
import requests
response = requests.post(
'https://api.iapp.co.th/v3/llm/deepseek-v4/chat/completions',
headers={
'apikey': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
json={
'model': 'deepseek-v4-flash',
'messages': [
{'role': 'user', 'content': 'อธิบายความแตกต่างระหว่าง SLM และ LLM'}
],
'max_tokens': 1024
}
)
print(response.json())
การใช้งานจริงในประเทศไทย
1. แชทบอทบริการลูกค้าภาษาไทย
ติดตั้ง Chinda บนเซิร์ฟเวอร์ของคุณเพื่อตอบคำถามลูกค้าไทย:
- ไม่มีค่าใช้จ่ายต่อ request
- ข้อมูลเป็นส่วนตัวอย่างสมบูรณ์
- ทำงานออฟไลน์หรือในสภาพแวดล้อมที่แยกจากอินเทอร์เน็ต
2. ประมวลผลเอกสารไท��ย
รวม SLMs กับ Thai OCR:
- ดึงข้อความจากเอกสารไทย
- สรุปหรือจัดหมวดหมู่เนื้อหาในเครื่อง
- ประมวลผลเอกสารละเอียดอ่อนโดยไม่ต้องผ่านคลาวด์
3. ผู้ช่วยเสียงภาษาไทยบนมือถือ
จับคู่กับ Speech-to-Text และ Text-to-Speech:
- โต้ตอบด้วยเสียงบนอุปกรณ์
- รู้จำเสียงพูดไทยแบบเรียลไทม์
- สังเคราะห์เสียงพูดไทยที่เป็นธรรมชาติ
4. Edge AI สำหรับค้าปลีกไทย
ติดตั้งบนเซิร์ฟเวอร์ในร้าน:
- แนะนำสินค้าโดยไม่ต้องใช้อินเทอร์เน็ต
- AI จัดการสินค้าคงคลัง
- วิเคราะห์ลูกค้าโดยรักษาความเป็นส่วนตัว
เริ่มต้นกับ Small Language Models
ตัวเลือก 1: ใช้ DeepSeek V4 API ของ iApp (ง่ายที่สุด)
- สร้างบัญชี: เข้าไปที่ iApp.co.th
- รับ API key: ไปที่ การจัดการ API Key
- เริ่มสร้าง: ใช้ REST API ที่ง่าย
- ค่าใช้จ่าย: คิดตามจำนวนโทเค็น เริ่มต้น 0.01 IC ต่อ 1K โทเค็น
ตัวเลือก 2: รันในเครื่อง (เป็นส่วนตัวที่สุด)
- ดาวน์โหลดโมเดล: รับ Chinda จาก Hugging Face
- ติดตั้ง runtime: ใช้ LM Studio หรือ Ollama
- รันในเครื่อง: ไม่ต้องใช้อินเทอร์เน็ต
- ค่าใช้จ่าย: แค่ฮาร์ดแวร์ของคุณ
ตัวเลือก 3: ติดตั้ง On-Premise (องค์กร)
- ติดต่อ iApp: ติดต่อเรา
- การตั้งค่าที่กำหนดเอง: ปรับแต่งตามโครงสร้างพื้นฐานของคุณ
- การสนับสนุน: SLA ระดับองค์กรและการฝึกอบรม
- ค่าใช้จ่าย: ค่าลิขสิทธิ์ครั้งเดียว + การสนับสนุน
เปรียบเทียบโมเดล AI ของ iApp
| โมเดล | ประเภท | พารามิเตอร์ | เหมาะสำหรับ | ราคา |
|---|---|---|---|---|
| OpenThai Chinda 4B | SLM | 4B | แชทบอทไทย, ติดตั้งในเครื่อง | ฟรี |
| DeepSeek-V3.2 | LLM | 685B | การให้เหตุผลซับซ้อน, เขียนโค้ด | 0.01 IC/1K tokens |
| Thanoy Legal AI | Domain SLM | - | เอกสารกฎหมายไทย | ตามโทเค็น |
อนาคตของ Small Language Models
เทรนด์ที่ควรจับตา
- On-Device AI: สมาร์ทโฟนทุกเครื่องจะมี SLMs ที่มีความสามารถ
- โมเดลเฉพาะทาง: SLMs เฉพาะอุตสาหกรรม (การแพทย์ กฎหมาย การเงิน)
- ระบบไฮบริด: SLMs สำหรับคำถามง่าย, LLMs สำหรับคำถามซับซ้อน
- ประสิทธิภาพที่ดีขึ้น: ความสามารถเท่าเดิมด้วยพารามิเตอร์น้อยลง
- โฟกัสภาษาไทย: โมเดลที่ปรับแต่งสำหรับภาษาไทยมากขึ้น
ทำไมสิ่งนี้สำคัญสำหรับธุรกิจไทย
- ประหยัดค่าใช้จ่าย: ลดค่าโครงสร้างพื้นฐาน AI 90%+
- อธิปไตยข้อมูล: เก็บข้อมูลไทยในประเทศไทย
- ความได้เปรียบในการแข่งขัน: ใช้ AI ได้เร็วกว่าคู่แข่ง
- นวัตกรรม: สร้างผลิตภัณฑ์ที่เป็นไปไม่ได้ด้วย cloud-only AI
สรุป
Small Language Models เป็นตัวแทนของการเปลี่ยนแปลงพื้นฐานในการใช้งาน AI - จากการประมวลผลบนคลาวด์แบบรวมศูนย์ไปสู่ AI แบบกระจาย มีประสิทธิภาพ และรักษาความเป็นส่วนตัว พวกมันไม่ใช่การทดแทน LLMs แต่เป็นส่วนเสริม ทำให้ AI ทำงานได้ในสถานการณ์ที่โมเดลขนาดใหญ่ไปไม่ถึง
สำหรับธุรกิจและนักพัฒนาไทย SLMs เช่น Chinda มอบโอกาสที่ไม่เคยมีมาก่อนในการสร้างแอปพลิเคชันที่ขั�บเคลื่อนด้วย AI ที่เร็ว ราคาจับต้องได้ และเคารพความเป็นส่วนตัวของผู้ใช้
พร้อมเริ่มต้นหรือยัง? สมัครฟรี และลองใช้ OpenThai Chinda - Small Language Model ของประเทศไทย!
มีคำถาม? เข้าร่วม Discord Community ของเราหรืออีเมลมาที่ support@iapp.co.th
iApp Technology Co., Ltd. บริษัทเทคโนโลยี AI ชั้นนำของประเทศไทย