Big Data คืออะไร? คู่มือฉบับสมบูรณ์สำหรับผู้เริ่มต้น

ทุกวินาที โลกสร้างข้อมูลในปริมาณที่นึกไม่ถึง ทุกการค้นหาใน Google, ทุกโพสต์โซเชียลมีเดีย, ทุกการซื้อออนไลน์, ทุกค่าเซ็นเซอร์ — ทุกอย่างสะสมขึ้น ที่จริงแล้ว เราสร้างข้อมูลประมาณ 2.5 ควินทิลเลียนไบต์ทุกวัน ข้อมูลมหาศาลนี้คือสิ่งที่เราเรียกว่า Big Data และการเรียนรู้วิธีใช้ประโยชน์จากมันกลายเป็นทักษะที่มีค่าที่สุดอย่างหนึ่งในโลกธุรกิจยุคใหม่
Big Data คืออะไร?
Big Data หมายถึงชุดข้อมูลขนาดใหญ่และซับซ้อนมากจนเครื่องมือประมวลผลข้อมูลแบบดั้งเดิมไม่สามารถจัดการได้อย่างมีประสิทธิภาพ แต่ไม่ใช่แค่เรื่องขนาด — Big Data ถูกนิยามโดยลักษณะเฉพาะที่ทำให้มันท้าทายและมีคุณค่า
โดยหลักแล้ว Big Data คื��อ:
- ใหญ่เกินไป สำหรับฐานข้อมูลทั่วไป
- เร็วเกินไป — ถูกสร้างขึ้นแบบเรียลไทม์
- หลากหลายเกินไป — มาในรูปแบบที่แตกต่างกันมากมาย
- ซับซ้อนเกินไป สำหรับเครื่องมือวิเคราะห์ธรรมดา
เป้าหมายของ Big Data ไม่ใช่แค่การเก็บข้อมูลมหาศาล — แต่คือการวิเคราะห์ข้อมูลนี้เพื่อค้นพบรูปแบบ แนวโน้ม และข้อมูลเชิงลึกที่ช่วยตัดสินใจได้ดีขึ้น
ตัวอย่างง่ายๆ
ข้อมูลแบบดั้งเดิม:
- ร้านเล็กๆ ติดตามยอดขายรายวันใน spreadsheet
- 100 รายการต่อวัน จัดการง่ายใน Excel
- การคำนวณง่ายๆ เช่น ยอดรวมรายเดือนและค่าเฉลี่ย
Big Data:
- แพลตฟอร์ม e-commerce ประมวลผลล้านรายการต่อวัน
- ติดตามพฤติกรรมผู้ใช้: คลิก, ค้นหา, เวลาบนหน้า, การละทิ้งตะกร้า
- รวมกับ sentiment โซเชียลมีเดีย, ข้อมูลสภาพอากาศ, ตัวชี้วัดเศรษฐกิจ
- ใช้ AI ทำนายแนวโน้ม, ปรับแต่งคำแนะนำ, ปรับราคาให้เหมาะสม
5 V's ของ Big Data
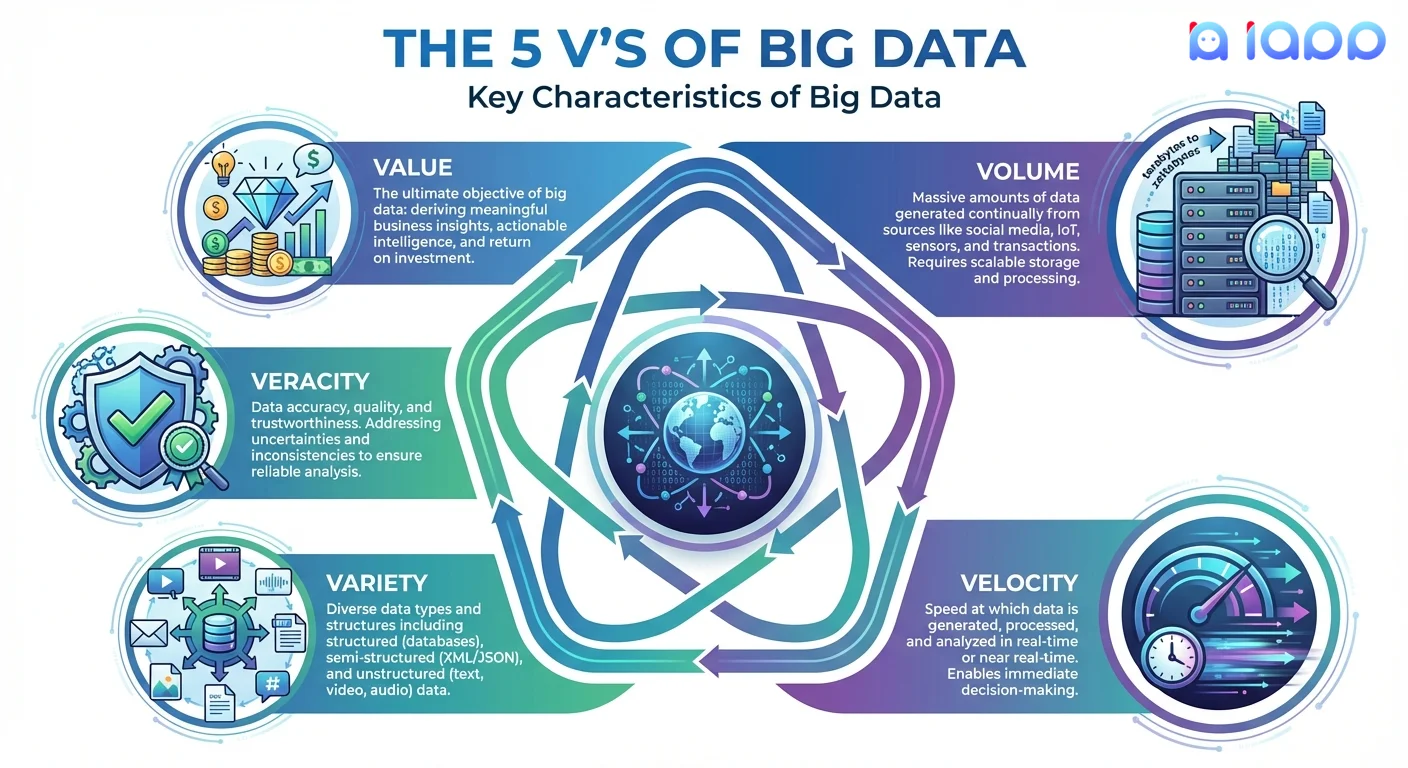
Big Data มักถูกนิยามด้วยลักษณะสำคัญ 5 ประการ:
1. Volume (ปริมาณ)
ปริมาณข้อมูลที่ถูกสร้างขึ้น
- ผู้ใช้ Facebook อัปโหลด 350 ล้านรูปต่อวัน
- YouTube รับวิดีโอ 500 ชั่วโมงทุกนาที
- เซ็นเซอร์ IoT สร้างข้อมูลหลายพันล้านจุดอย่างต่อเนื่อง
ความท้าทาย: จัดเก็บและจัดการข้อมูลระดับ petabytes หรือ exabytes
2. Velocity (ความเร็ว)
ความเร็วที่ข้อมูลถูกสร้างและต้องประมวลผล
- ข้อมูลตลาดหุ้นเปลี่ยนทุกมิลลิวินาที
- โพสต์โซเชียลมีเดียไวรัลในไม่กี่นาที
- ข้อมูลเซ็นเซอร์ไหลเข้าแบบเรียลไทม์อย่างต่อเนื่อง
ความท้าทาย: ประมวลผลข้อมูลเร็วพอที่จะลงมือได้ทันเวลา
3. Variety (ความหลากหลาย)
ประเภทและรูปแบบที่แตกต่างของข้อมูล
- มีโครงสร้าง: ฐานข้อมูล, spreadsheets, บันทึกรายการ
- กึ่งมีโครงสร้าง: JSON, XML, อีเมล, logs
- ไม่มีโครงสร้าง: รูปภาพ, วิดีโอ, เสียง, โพสต์โซเชียลมีเดีย, เอกสาร
ความท้าทาย: รวมและวิเคราะห์ข้อมูลประเภทต่างๆ ร่วมกัน
4. Veracity (ความถูกต้อง)
ความแม่นยำและความน่าเชื่อถือของข้อมูล
- ข้อมูลถูกต้องและเชื่อถือได้หรือไม่?
- เราจัดการกับข้อมูลที่ขาดหายหรือไม่สมบูรณ์อย่างไร?
- เราเชื่อถือแหล่งที่มาได้หรือไม่?
ความท้าทาย: รับรองคุณภาพข้อมูลก่อนตัดสินใจ
5. Value (คุณค่า)
มูลค่าทางธุรกิจที่สกัดได้จากข้อมูล
- ข้อมูลดิบไม่มีประโยชน์หากไม่วิเคราะห์
- เป้าหมายคือข้อมูลเชิงลึกที่นำไปใช้ได้
- ROI ต้องคุ้มค่ากับต้นทุนโครงสร้างพื้นฐาน Big Data
ความท้าทาย: หารูปแบบที่มีความหมายท่ามกลาง noise
ประเภทของ Big Data
1. ข้อมูลมีโครงสร้าง (Structured Data)
ข้อมูลที่จัดระเบียบเข้ากับตารางที่มีแถวและคอลัมน์
ตัวอย่าง:
- บันทึกฐานข้อมูล
- Spreadsheets
- บันทึกรายการธุรกรรม
- ค่าเซ็นเซอร์ที่มีรูปแบบกำหนด
ลักษณะ: ค้นหา วิเคราะห์ และประมวลผลง่าย การจัดเก็บ: ฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม (SQL)
2. ข้อมูลกึ่งมีโครงสร้าง (Semi-Structured Data)
ข้อมูลที่มีคุณสมบัติการจัดระเบียบบางอย่างแต่ไม่มีโครงสร้างที่เข้มงวด
ตัวอย่าง:
- ไฟล์ JSON และ XML
- ข้อความอีเมล
- Web server logs
- เอกสาร NoSQL database
ลักษณะ: schema ยืดหยุ่น, อธิบายตัวเอง การจัดเก็บ: NoSQL databases, document stores
3. ข้อมูลไม่มีโครงสร้าง (Unstructured Data)
ข้อมูลที่ไม่มีรูปแบบหรือการจัดระเบียบที่กำหนดไว้ล่วงหน้า
ตัวอย่าง:
- เอกสารข้อความและ PDFs
- รูปภาพและรูปถ่าย
- ไฟล์เสียงและวิดีโอ
- โพสต์โซเชียลมีเดีย
ลักษณะ: วิเครา�ะห์ยากที่สุด, ต้องใช้ AI/ML การจัดเก็บ: Data lakes, object storage
ข้อมูลน่าสนใจ: มากกว่า 80% ของข้อมูลองค์กรเป็นแบบไม่มีโครงสร้าง และนี่คือจุดที่ AI โดดเด่น!
คำศัพท์ Big Data สำคัญที่ควรรู้
1. Data Lake
คืออะไร: ที่เก็บข้อมูลส่วนกลางที่จัดเก็บข้อมูลทุกประเภทในรูปแบบดิบดั้งเดิม
เปรียบเทียบง่ายๆ: เหมือนทะเลสาบจริงที่มีลำธารต่างๆ (แหล่งข้อมูล) ไหลเข้ามา คุณสามารถตกปลา (ข้อมูล) ที่ไหนก็ได้สำหรับปลาประเภทใดก็ได้
คุณสมบัติหลัก:
- จัดเก็บข้อมูลมีโครงสร้าง, กึ่งมีโครงสร้าง และไม่มีโครงสร�้าง
- Schema-on-read (โครงสร้างถูกใช้เมื่อเข้าถึงข้อมูล)
- ประหยัดต้นทุนสำหรับการจัดเก็บขนาดใหญ่
- เหมาะสำหรับ AI/ML และการสำรวจ
2. Data Warehouse
คืออะไร: ที่เก็บข้อมูลที่มีโครงสร้างและจัดระเบียบเพื่อการวิเคราะห์และรายงาน
เปรียบเทียบง่ายๆ: เหมือนคลังสินค้าที่จัดระเบียบดีที่ทุกอย่างมีที่และป้ายเฉพาะ หาสิ่งที่ต้องการได้ง่าย
คุณสมบัติหลัก:
- จัดเก็บข้อมูลที่มีโครงสร้างและประมวลผลแล้ว
- Schema-on-write (โครงสร้างถูกกำหนดก่อนจัดเก็บ)
- ปรับแต่งสำหรับ queries ที่รวดเร็ว
- เหมาะสำหรับ business intelligence และ dashboards
3. ETL (Extract, Transform, Load)
คืออะไร: กระบวน�การย้ายข้อมูลจากแหล่งไปยังปลายทาง โดยแปลงระหว่างทาง
เปรียบเทียบง่ายๆ: เหมือนการแยก ทำความสะอาด และจัดระเบียบของชำจากถุงช้อปปิ้งเข้าตู้ครัว
ขั้นตอน:
- Extract: ดึงข้อมูลจากแหล่งต่างๆ
- Transform: ทำความสะอาด ตรวจสอบ แปลงรูปแบบ
- Load: จัดเก็บในระบบปลายทาง
4. Data Pipeline
คืออะไร: ชุดกระบวนการอัตโนมัติที่ย้ายและแปลงข้อมูลจากแหล่งไปยังปลายทาง
เปรียบเทียบง่ายๆ: เหมือนสายการผลิตโรงงานที่วัตถุดิบเข้าด้านหนึ่งและผลิตภัณฑ์สำเร็จรูปออกอีกด้าน
ส่วนประกอบ:
- การนำเข้าข้อมูล (collection)
- การประมวลผลข้อมูล (transformation)
- การจัดเก็บข้อมูล (warehousing)
- การวิเคราะห์ข้อมูล (insights)
5. Real-Time Analytics
คืออะไร: การประมวลผลและวิเคราะห์ข้อมูลทันทีที่ถูกสร้างขึ้น
เปรียบเทียบง่ายๆ: เหมือนกระดานคะแนนกีฬาสดที่อัปเดตทันทีทุกการเล่น
กรณีใช้งาน:
- ตรวจจับการฉ้อโกง
- ซื้อขายหุ้น
- ติดตาม IoT
- Dashboards แบบสด
ทำไม Big Data ถึงสำคัญ
1. การตัดสินใจที่ดีขึ้น
การตัดสินใจจากข้อมูลเหนือกว่าสัญชาตญาณ บริษัทที่ใช้ Big Data analytics:
- มีโอกาสตัดสินใจเร็วขึ้น 5 เท่า
- มีโอกาสดำเนินการตามที่ตั้��งใจ 3 เท่า
2. เข้าใจลูกค้า
Big Data เผยให้เห็น:
- สิ่งที่ลูกค้าต้องการจริงๆ (ไม่ใช่สิ่งที่พวกเขาพูด)
- รูปแบบพฤติกรรมและความชอบ
- การทำนายและป้องกันการเลิกใช้บริการ
- โอกาสในการปรับแต่งส่วนบุคคล
3. ประสิทธิภาพการดำเนินงาน
เพิ่มประสิทธิภาพการดำเนินงานโดย:
- การบำรุงรักษาเชิงพยากรณ์ (ซ่อมก่อนพัง)
- การปรับปรุง supply chain
- การจัดสรรทรัพยากร
- การทำงานอัตโนมัติ
4. แหล่งรายได้ใหม่
สร้างมูลค่าผ่าน:
- ผลิตภัณฑ์และบริการข้อมูล
- ข้อเสนอส่วนบุคคล
- การกำหนดราคาแบบไดนามิก
- ข้อมูลเชิงลึกตลาดใหม่
5. ความได้เปรียบในการแข่งขัน
บริษัทที่ใช้ Big Data อย่างมีประสิทธิภาพสามารถ:
- ตอบสนองต่อการเปลี่ยนแปลงตลาดได้เร็วขึ้น
- ระบุแนวโน้มก่อนคู่แข่ง
- สร้างสรรค์นวัตกรรมจากข้อมูลเชิงลึก
- ลดต้นทุนพร้อมปรับปรุงคุณภาพ
Big Data แก้ปัญหาอะไร?
| ปั��ญหา | วิธีแบบดั้งเดิม | โซลูชัน Big Data |
|---|---|---|
| ข้อมูลเชิงลึกลูกค้า | แบบสำรวจ & focus groups | การวิเคราะห์พฤติกรรมระดับใหญ่ |
| ตรวจจับการฉ้อโกง | ตรวจสอบด้วยมือ, กฎ | การตรวจจับรูปแบบ AI แบบเรียลไทม์ |
| จัดการสินค้าคงคลัง | ค่าเฉลี่ยประวัติ | การพยากรณ์ความต้องการ |
| ประสิทธิภาพการตลาด | metrics แคมเปญ | attribution modeling, personalization |
| ควบคุมคุณภาพ | ทดสอบตัวอย่าง | ตรวจสอบอัตโนมัติ 100% |
| ประเมินความเสี่ยง | วิเคราะห์ด้วยมือ | ML risk scoring models |
Big Data ทำงานอย่างไร
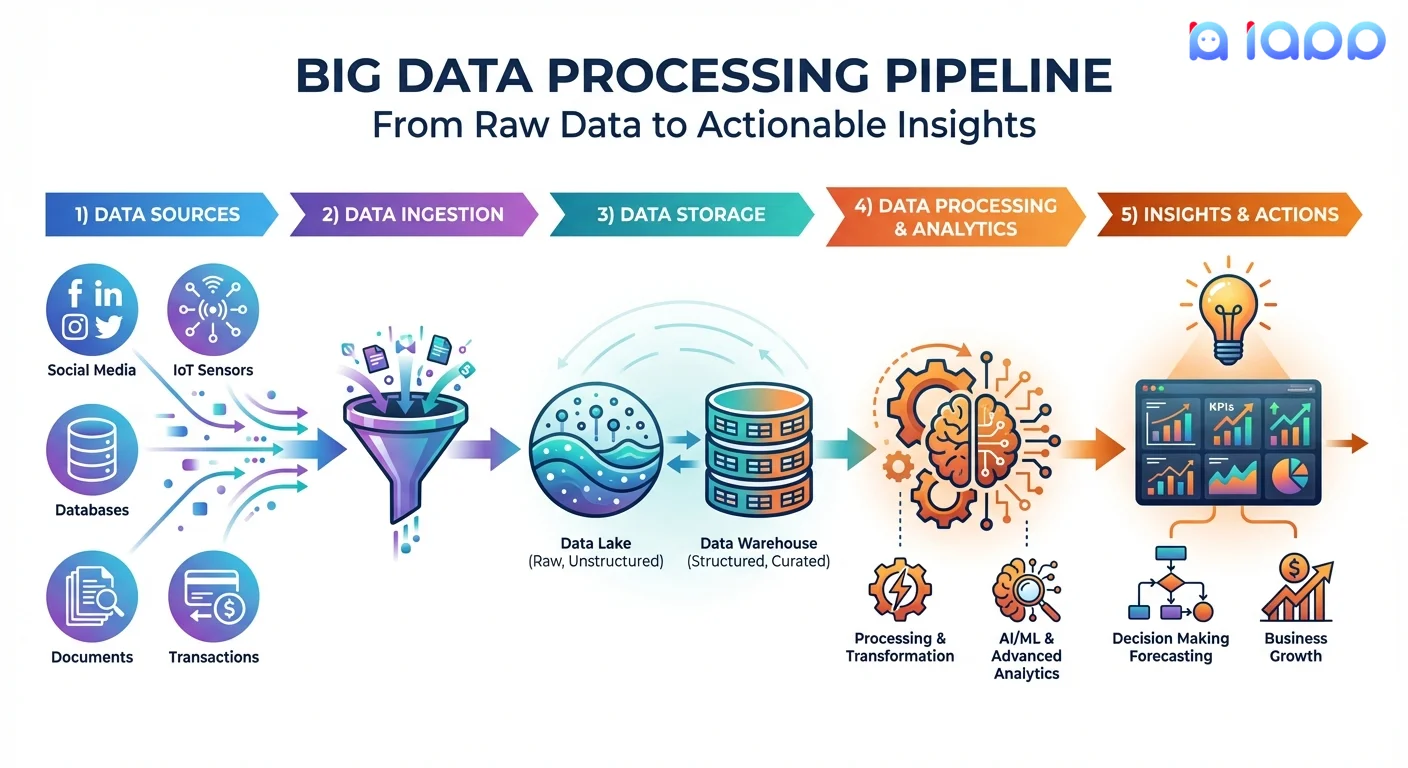
Big Data Pipeline
-
แหล่งข้อมูล
- ภายใน: CRM, ERP, ธุรกรรม, logs
- ภายนอก: โซเชียลมีเดีย, ข้อมูลสาธารณะ, third-party
- IoT: เซ็นเซอร์, อุปกรณ์, เครื่องจักร
- ผู้ใช้สร้าง: เอกสาร, รูปภาพ, feedback
-
การนำเข้าข้อมูล
- Batch ingestion (โหลดเป็นกลุ่มเป็นระยะ)
- Stream ingestion (เรียลไทม์ต่อเนื่อง)
- API integrations
- การอัปโหลดและโอนไฟล์
-
การจัดเก็บข้อมูล
- Data lakes สำหรับข้อมูลดิบ
- Data warehouses สำหรับข้อมูลที่ประมวลผลแล้ว
- ระบบจัดเก็บแบบกระจาย
- Cloud storage (ขยายขนาดได้, ประหยัดต้นทุน)
-
การประมวลผลข้อมูล
- ทำความสะอาดและตรวจสอบ
- แปลงและเพิ่มคุณค่า
- รวมและสรุป
- การวิเคราะห์ Machine learning และ AI
-
ข้อมูลเชิงลึกและการดำเนินการ
- Dashboards และ visualizations
- รายงานและ alerts
- Predictive models
- การตัดสินใจและดำเนินการอัตโนมัติ
ตัวอย่าง Technology Stack
Big Data ในประเทศไทย: การใช้งานจริง
1. การประมวลผลเอกสารไทยขนาดใหญ่
ใช้ Thai OCR APIs:
- ประมวลผลบัตรประชาชน พาสปอร์ต เอกสารไทยหลายล้านฉบับ
- แยกข้อมูลที่มีโครงสร้างอัตโนมัติ
- เปิดใช้การยืนยันตัวตนขนาดใหญ่
- สร้างคลังเอกสารที่ค้นหาได้
2. Voice Data Analytics
ใช้ Speech-to-Text:
- ถอดเสียงการบันทึก call center หลายพันรายการ
- วิเคราะห์ sentiment ลูกค้าในระดับใหญ่
- แยกข้อมูลเชิงลึกจากข้อมูลเสียง
- สร้างคลังเสียงที่ค้นหาได้
3. Thai Text Analytics
ใช้ DeepSeek V4:
- วิเคราะห์โพสต์โซเชียลมีเดียไทยหลายล้านโพสต์
- แยก sentiment และหัวข้อ
- เข้าใจ feedback ลูกค้าในระดับใหญ่
- สร้างข้อมูลเชิงลึกจากข้อความที่ไม่มีโครงสร้าง
4. การประมวลผลข้อมูลหลายภาษา
ใช้ Translation API:
- ประมวลผลข้อมูลในหลายภาษา
- ทำให้เนื้อหาหลายภาษาเป็นมาตรฐาน
- เปิดใช้การวิเคราะห์ข้ามภาษา
- เข้าถึงตลาดต่างประเทศ
5. การวิเคราะห์เอกสารกฎหมาย
ใช้ Thanoy Legal AI:
- วิเคราะห์เอกสารกฎหมายปริมาณมาก
- แยกข้อกำหนดและเงื่อนไขสำคัญ
- ระบุรูปแบบข้ามสัญญา
- ทำการวิจัยกฎหมายอัตโนมัติ
สร้างโซลูชัน Big Data ด้วย iApp
iApp Technology ให้บริการ AI APIs ที่แปลงข้อมูลไม่มีโครงสร้างเป็นข้อมูลเชิงลึกที่มีโครงสร้าง:
ส่วนประกอบที่มี
| ประเภทข้อมูล | ผลิตภัณฑ์ iApp | กรณีใช้งาน Big Data |
|---|---|---|
| เอกสารไทย | Thai OCR APIs | การแปลงเอกสารเป็นดิจิทัลขนาดใหญ่ |
| เสียงไทย | Speech-to-Text | Voice data analytics |
| ข้อความไทย | OpenThai Chinda | Text analytics และ NLP |
| รูปภาพ/ใบหน้า | Face Recognition | Visual data processing |
| หลายภาษา | Translation API | ข้อมูลข้ามภาษา |
| เอกสารกฎหมาย | Thanoy Legal AI | การวิเคราะห์เอกสารกฎหมาย |
ตัวอย่าง: Document Processing Pipeline
import requests
from concurrent.futures import ThreadPoolExecutor
def process_thai_document(document_path):
"""
ประมวลผลเอกสารไทยและแยกข้อมูลที่มีโครงสร้าง
"""
with open(document_path, 'rb') as f:
response = requests.post(
'https://api.iapp.co.th/thai-national-id-ocr/v3',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': f}
)
return response.json()
def batch_process_documents(document_list):
"""
ประมวลผลเอกสารหลายฉบับพร้อมกันสำหรับระดับ Big Data
"""
results = []
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [
executor.submit(process_thai_document, doc)
for doc in document_list
]
for future in futures:
results.append(future.result())
return results
# ตัวอย่าง: ประมวลผล 1000 เอกสาร
documents = ['doc1.jpg', 'doc2.jpg', ...] # รายการเอกสารของคุณ
structured_data = batch_process_documents(documents)
# ตอนนี้คุณมีข้อมูลที่มีโครงสร้างพร้อมสำหรับการวิเคราะห์!
# เก็บในฐานข้อมูล, data warehouse หรือ data lake
ตัวอย่าง: Voice Analytics Pipeline
import requests
def transcribe_and_analyze(audio_file):
"""
ถอดเสียงและวิเคราะห์ด้วย LLM
"""
# ขั้นตอนที่ 1: ถอดเสียงไทย
with open(audio_file, 'rb') as f:
stt_response = requests.post(
'https://api.iapp.co.th/thai-speech-to-text/v2',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': f}
)
transcript = stt_response.json()['transcript']
# ขั้นตอนที่ 2: วิเคราะห์ด้วย LLM
analysis_response = requests.post(
'https://api.iapp.co.th/v3/llm/deepseek-v4/chat/completions',
headers={
'apikey': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
json={
'model': 'deepseek-v4-flash',
'messages': [{
'role': 'user',
'content': f"""วิเคราะห์การสนทนานี้:
{transcript}
สรุป:
1. หัวข้อหลัก
2. ความรู้สึกของลูกค้า (บวก/ลบ/เป็นกลาง)
3. ประเด็นหรือข้อร้องเรียน
4. การดำเนินการที่แนะนำ"""
}],
'max_tokens': 512
}
)
return {
'transcript': transcript,
'analysis': analysis_response.json()['choices'][0]['message']['content']
}
เริ่มต้นใช้งาน Big Data
ขั้นตอนที่ 1: ระบุแหล่งข้อมูลของคุณ
คุณมีข้อมูลอะไรบ้าง?
- ธุรกรรมลูกค้า
- พฤติกรรมเว็บไซต์/แอป
- เอกสารและไฟล์
- การบันทึกสาย
- การกล่าวถึงในโซเชียลมีเดีย
ขั้นตอนที่ 2: กำหนดเป้าหมาย
คุณต้องการข้อมูลเชิงลึกอะไร?
- ความเข้าใจลูกค้า
- ประสิทธิภาพการดำเนินงาน
- การจัดการความเสี่ยง
- การปรับปรุงรายได้
ขั้นตอนที่ 3: เริ่มเล็ก ขยายใหญ่
อย่าพยายามทำทุกอย่างพร้อมกัน:
- เลือกหนึ่ง use case
- พิสูจน์คุณค่าด้วย pilot
- สร้างต่อจากความสำเร็จ
- ค่อยๆ ขยาย
ขั้นตอนที่ 4: ใช้ AI เพื่อปลดล็อกข้อมูลไม่มีโครงสร้าง
แปลงข้อมูลดิบเป็นข้อมูลเชิงลึก:
- ใช้ Thai OCR สำหรับเอกสาร
- ใช้ Speech-to-Text สำหรับเสียง
- ใช้ OpenThai Chinda สำหรับการวิเคราะห์ข้อความ
แหล่งข้อมูล
- รับ API Access: จัดการ API Key
- ลอง Thai OCR: Document OCR Demo
- ลอง Speech APIs: Speech-to-Text Demo
- สำรวจ APIs ทั้งหมด: แคตตาล็อก API ครบ
- เข้าร่วมชุมชน: Discord
อนาคตของ Big Data
แนวโน้มที่ควรติดตาม
- AI-Powered Analytics: Machine learning ทำความเข้าใจข้อมูลซับซ้อนอัตโนมัติ
- Real-Time Everything: ข้อมูลเชิงลึกทันทีแทนการประมวลผลแบบ batch
- Edge Computing: ประมวลผลข้อมูลใกล้กับแหล่งที่สร้าง
- Data Mesh: ความเป็นเจ้าของและการกำกับดูแลข้อมูลแบบกระจาย
- Privacy-Preserving Analytics: สกัดข้อมูลเชิงลึกพร้อมปกป้องความเป็นส่วนตัว
ทำไมธุรกิจไทยควรลงมือตอนนี้
- ข้อมูลกำลังเติบโต: เศรษฐกิจดิจิทัลไทยสร้างข้อมูลมากกว่าที่เคย
- แรงกดดันการแข่งขัน: คู่แข่งกำลังลงทุนในความสามารถด้านข้อมูล
- AI เข้าถึงได้: เครื่องมือเช่น iApp APIs ทำให้ AI analytics เข้าถึงได้
- ความคาดหวังลูกค้า: ลูกค้าคาดหวังประสบการณ์ที่ขับเคลื่อนด้วยข้อมูลและปรับแต่งส่วนบุคคล
- พร้อมรับกฎระเบียบ: การปฏิบัติตาม PDPA ต้องการความเข้าใจข้อมูลของคุณ
สรุป
Big Data ไม่ใช่แค่การมีข้อมูลมากมาย — แต่คือการแปลงข้อมูลนั้นเป็นข้อมูลเชิงลึกที่นำไปใช้ได้เพ�ื่อขับเคลื่อนการตัดสินใจที่ดีขึ้น ตั้งแต่การเข้าใจลูกค้าไปจนถึงการปรับปรุงการดำเนินงาน ความสามารถด้าน Big Data กลายเป็นสิ่งจำเป็นสำหรับธุรกิจที่แข่งขันได้
ความท้าทายสำหรับธุรกิจไทยหลายแห่งคือข้อมูลที่มีค่าส่วนใหญ่ถูกล็อกในรูปแบบที่ไม่มีโครงสร้าง: เอกสารไทย การบันทึกเสียง รูปภาพ และข้อความ นี่คือจุดที่ AI APIs ของ iApp Technology โดดเด่น — แปลงข้อมูลไทยที่ไม่มีโครงสร้างเป็นข้อมูลเชิงลึกที่มีโครงสร้างในระดับใหญ่
ด้วย Thai OCR สำหรับการประมวลผลเอกสาร, Speech-to-Text สำหรับ voice analytics, OpenThai Chinda สำหรับการวิเคราะห์ข้อความ และ Translation สำหรับข้อมูลหลายภาษา — ธุรกิจไทยมีเครื่องมือเพื่อปลดล็อกคุณค่าใน Big Data ของตน
พร้อมแปลงข้อมูลของคุณเป็นข้อมูลเชิงลึกแล้วหรือยัง? �ลงทะเบียนฟรี และเริ่มประมวลผลข้อมูลไทยในระดับใหญ่วันนี้!
มีคำถาม? เข้าร่วม Discord Community ของเราหรือส่งอีเมลมาที่ support@iapp.co.th
บริษัท ไอแอพพ์ เทคโนโลยี จำกัด บริษัท AI ชั้นนำของประเทศไทย