Multimodal AI คืออะไร? คู่มือฉบับสมบูรณ์สำหรับผู้เริ่มต้น

มนุษย์เข้าใจโลกผ่านประสาทสัมผัสหลายอย่างโดยธรรมชาติ - เราเห็นภาพ ได้ยินเสียง อ่านข้อความ และดูวิดีโอพร้อมกัน แต่จนกระทั่งเมื่อไม่นานมานี้ ระบบ AI ถูกจำกัดให้ประมวลผลข้อมูลได้ทีละประเภทเท่านั้น ขอต้อนรับสู่ Multimodal AI - ปัญญาประดิษฐ์ที่สามารถเข้าใจและทำงานกับข้อมูลหลายประเภทพร้อมกัน เหมือนกับที่มนุษย์ทำ
Multimodal AI คืออะไร?
Multimodal AI หมายถึงระบบปัญญาประดิษฐ์ที่สามารถประมวลผล เข้าใจ และสร้างข้อมูลหลายประเภท (เรียกว่า "modalities" หรือ "รูปแบบข้อมูล") เช่น:
- ข้อความ (Text) - ภาษาเขียน เอกสาร ข้อความแชท
- รูปภาพ (Image) - รูปถ่าย ไดอะแกรม กราฟ เอกสารสแกน
- เสียง (Audio) - เ��สียงพูด ดนตรี เอฟเฟกต์เสียง
- วิดีโอ (Video) - ภาพเคลื่อนไหวที่มีหรือไม่มีเสียง
สิ่งสำคัญคือ Multimodal AI ไม่เพียงแค่จัดการข้อมูลเหล่านี้แยกกัน - มันเข้าใจความสัมพันธ์ระหว่างข้อมูลเหล่านั้น ตัวอย่างเช่น มันสามารถดูรูปภาพและอธิบายสิ่งที่อยู่ในนั้น หรือฟังเสียงพูดและถอดความได้อย่างแม่นยำ
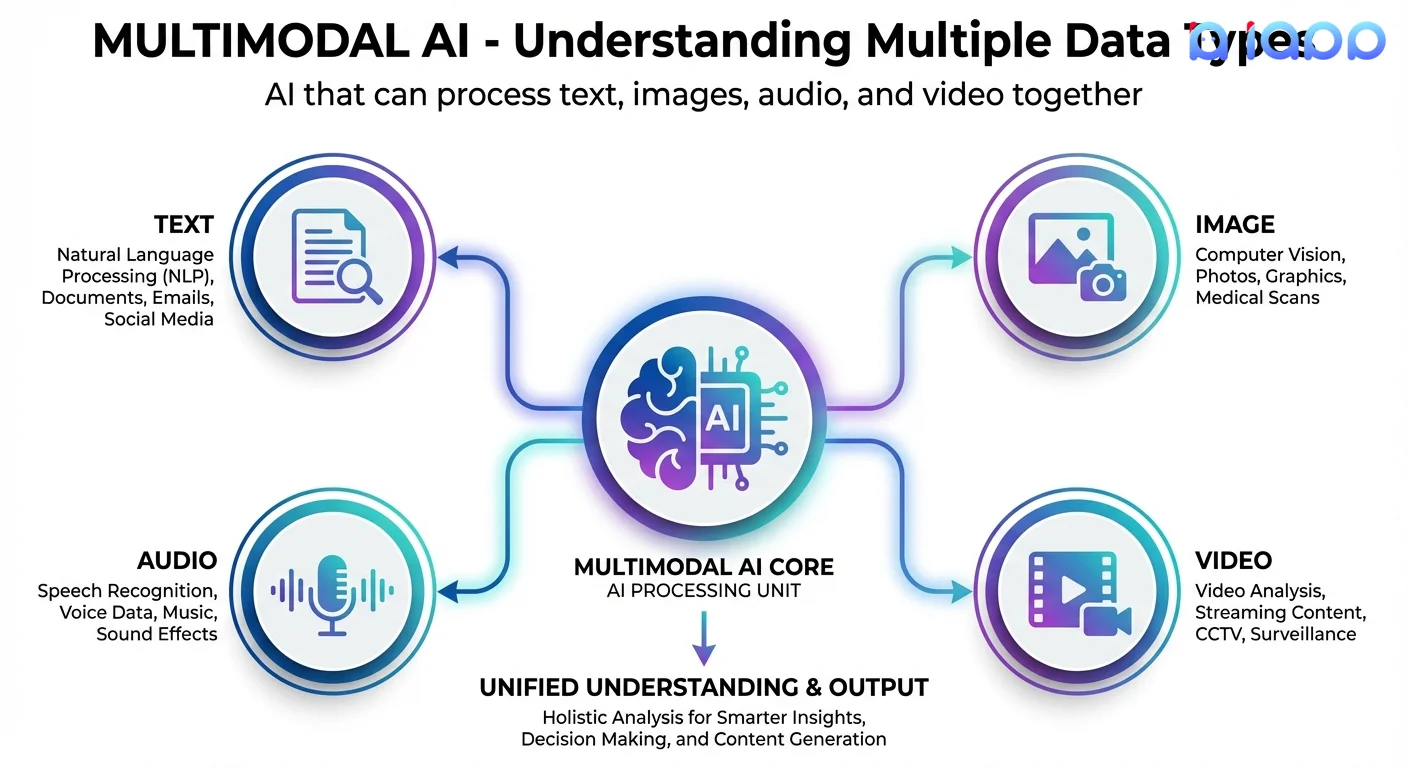
ตัวอย่างง่ายๆ
AI แบบดั้งเดิม (รูปแบบเดียว):
- AI ข้อความ: อ่านและเขียนข้อความได้ แต่ "เห็น" รูปภาพไม่ได้
- AI รูปภาพ: จดจำวัตถุในรูปได้ แต่อธิบายเป็นคำพูดไม่ได้
- AI เสียง: ถอดเสียงพูดได้ แต่เข้าใจรูป�ภาพไม่ได้
Multimodal AI:
- คุณให้ดูรูปบัตรประชาชนไทย มันอ่านข้อความทั้งหมด แยกรูปถ่าย ตรวจสอบประเภทเอกสาร และส่งออกข้อมูลที่จัดระเบียบแล้ว
- คุณถามว่า "มีอะไรในรูปนี้?" มันจะอธิบายฉากด้วยภาษาธรรมชาติ
- คุณให้เสียง + วิดีโอ มันเข้าใจบริบทจากทั้งสองพร้อมกัน
ประเภทของ Multimodal AI
1. โมเดลภาพ-ภาษา (Vision-Language Models - VLMs)
AI ที่รวมการเข้าใจภาพกับการประมวลผลข้อความ
- Input: รูปภาพ + คำสั่งข้อความ
- Output: คำอธิบาย คำตอบ การวิเคราะห์
- ตัวอย่าง: GPT-4V, Gemini, Claude Vision
- การใช้งาน: การบรรยายภาพ การถาม-ตอบเกี่ยวกับภาพ การเข้าใจเอกสาร
2. แปลงเสียงเป็นข้อความ / ข้อความเป็นเสียง
AI ที่เชื่อมต่อรูปแบบเสียงและข้อความ
- Speech-to-Text (STT): แปลงคำพูดเป็นข้อความเขียน
- Text-to-Speech (TTS): แปลงข้อความเขียนเป็นเสียงพูดที่เป็นธรรมชาติ
- การใช้งาน: ผู้ช่วยเสียง การถอดความ การสร้างหนังสือเสียง
3. Document AI / ระบบ OCR
AI ที่แยกข้อมูลจากรูปภาพเอกสาร
- Input: เอกสารส��แกน รูปถ่ายข้อความ
- Output: ข้อมูลข้อความที่จัดโครงสร้าง ฟิลด์ฟอร์ม
- การใช้งาน: การยืนยันตัวตน การประมวลผลใบแจ้งหนี้ การวิเคราะห์สัญญา
4. โมเดลเสียง-ภาพ
AI ที่ประมวลผลทั้งเสียงและวิดีโอพร้อมกัน
- Input: วิดีโอพร้อมแทร็กเสียง
- Output: การถอดความ บทสรุป การวิเคราะห์เนื้อหา
- การใช้งาน: การค้นหาวิดีโอ การตรวจสอบเนื้อหา บทสรุปการประชุม
5. โมเดล Any-to-Any
Multimodal AI ขั้นสูงสุดที่สามารถรับ input และส่ง output ได้ทุกรูปแบบ
- Input: รูปแบบใดก็ได้ (ข้อความ รูปภาพ เสียง วิดีโอ)
- Output: รูปแบบใด��ก็ได้
- ตัวอย่าง: GPT-4o, Gemini Ultra
- การใช้งาน: เครื่องมือสร้างสรรค์ ผู้ช่วยอเนกประสงค์
คำศัพท์ AI สำคัญที่ควรรู้
1. Modality (รูปแบบข้อมูล)
คืออะไร: ประเภทหรือรูปแบบของข้อมูลที่ AI สามารถประมวลผลได้
เปรียบเทียบง่ายๆ: คิดว่า modalities เหมือน "ประสาทสัมผัส" ต่างๆ เหมือนที่มนุษย์มีการมองเห็น การได้ยิน การสัมผัส รสชาติ และกลิ่น AI ก็มีการประมวลผลข้อความ การจดจำภาพ การวิเคราะห์เสียง เป็นต้น
Modalities ที่พบบ่อย: ข้อความ รูปภาพ เสียง วิดีโอ ��ข้อมูลเซ็นเซอร์ โมเดล 3D
2. Embedding (การฝังข้อมูล)
คืออะไร: วิธีการแปลงข้อมูลประเภทใดก็ได้ (ข้อความ รูปภาพ เสียง) เป็นตัวเลขที่ AI สามารถเข้าใจและเปรียบเทียบได้
เปรียบเทียบง่ายๆ: เหมือนการแปลภาษาต่างๆ เป็นภาษาสากลภาษาเดียว เมื่อทุกอย่างอยู่ใน "ภาษาตัวเลข" เดียวกัน AI จะหาความสัมพันธ์ระหว่างรูปถ่ายและคำอธิบายได้
ทำไมถึงสำคัญ: Embeddings ช่วยให้ Multimodal AI เชื่อมต่อ "รูปถ่ายของแมว" กับข้อความ "แมวขนฟูนั่งบนโซฟา" ได้
3. Fusion (การรวมข้อมูล)
คืออะไร: เทคนิคการรวมข้อมูลจากหลาย modalities เพื่อทำนายได้ดีขึ้น
เปรียบเทียบง่ายๆ: เหมือนวิธีที่คุณรวมสิ่งที่คุณเห็นและได้ยินเพื่อเข้าใจหนัง - แค่อย่างเดียวไม่ได้เล่าเรื่องทั้งหมด
ประเภท:
- Early fusion: รวมข้อมูลดิบก่อน แล้วค่อยประมวลผล
- Late fusion: ประมวลผลแต่ละ modality แยกกัน รวมผลลัพธ์ทีหลัง
- Cross-modal attention: ให้แต่ละ modality แจ้งข้อมูลซึ่งกันและกันระหว่างประมวลผล
4. Zero-shot / Few-shot Learning
คืออะไร: ความสามารถของ AI ในการจัดการงานใหม่โดยไม่ต้องฝึกฝนเฉพาะสำหรับงานนั้น
เปรียบเทียบง่ายๆ: เหมือนคนที่พูดภาษาอังกฤษเก่งสามารถเข้าใจคำสแลงใหม่จากบริบท โดยไม่ต้องสอนความหมาย
ในบริบท Multimodal: โมเดลภาพ-ภาษาสามารถตอบคำถามเกี่ยวกับรูปภาพที่ไม่เคยเห็นมาก่อน โดยใช้ความเข้าใจทั่วไป
5. OCR (การจดจำตัวอักษรด้วยแสง)
คืออะไร: เทคโนโลยีที่แปลงรูปภาพของข้อความเป็นข้อความที่เครื่องอ่านได้
เปรียบเทียบง่ายๆ: เหมือนมนุษย์อ่านข้อความจากรูปถ่ายแล้วพิมพ์ออกมา แต่ทำโดยอัตโนมัติด้วย AI
OCR สมัยใหม่: ไปไกลกว่าการจดจำตัวอักษรธรรมดา - สามารถเข้าใจโครงสร้างเอกสาร ตาราง ลายมือ และหลายภาษารวมถึงภาษาไทย
ทำไม Multimodal AI ถึงสำคัญ
1. การโต้ตอบที่เป็นธรรมชาติมากขึ้น
มนุษย์ไม่ได้สื่อสารแค่ทางเดียว เราแชร์รูปภาพ ข้อความเสียง วิดีโอ และข้อความ Multimodal AI ทำให้เครื่องเข้าใจเราในแบบที่เราสื่อสารโดยธรรมชาติ
2. ความแม่นยำที่ดีขึ้น
การใช้แหล่งข้อมูลหลายแหล่ง Multimodal AI สามารถตัดสินใจได้แม่นยำมากขึ้น ระบบที่เห็นและอ่านเอกสารน่าเชื่อถือกว่าระบบที่ทำได้แค่อย่างเดียว
3. การทำงานอัตโนมัติของงานซับซ้อน
งานในโลกจริงหลายอย่างต้องการเข้าใจข้อมูลหลายประเภท:
- บริการลูกค้า: แชทข้อความ + สายโทรศัพท์ + อัปโหลดรูปภาพ
- การประมวลผลเอกสาร: รูปภาพสแกน + ข้อความพิมพ์ + บันทึกลายมือ
- การควบคุมคุณภาพ: การตรวจสอบด้วยสายตา + ค่าเซ็นเซอร์ + ข้อกำหนด
4. การเข้าถึง
Multimodal AI ช่วยให้:
- แปลงข้อความเป็นเสียงสำหรับผู้พิการทางสายตา
- แปลงเสียงเป็นข้อความสำหรับผู้พิการทางการได้ยิน
- คำอธิบายภาพสำหรับโปรแกรมอ่านหน้าจอ
Multimodal AI แก้ปัญหาอะไร?
| ปัญหา | วิธีแบบดั้งเดิม | โซลูชัน Multimodal AI |
|---|---|---|
| การยืนยันตัวตน | ตรวจสอบเอกสารด้วยมือ | OCR + จับคู่ใบหน้า + ตรวจจับความมีชีวิต |
| สนับสนุนลูกค้า | จัดการข้อความ/เสียง/รูปภาพแยกกัน | เข้าใจ input ทั้งหมดรวมกัน |
| ประมวลผลเอกสาร | กรอกข้อมูลด้วยมือ | แยกข้อมูลอัตโนมัติจากเอกสารทุกประเภท |
| ตรวจสอบเนื้อหา | ตรวจรูปภาพ/ข้อความ/วิดีโอแยกกัน | เข้าใจเนื้อหาทั้งหมด |
| การวินิจฉัยทางการแพทย์ | วิเคราะห์แบบรูปแบบเดียว | รวมภาพ + ประวัติ + บันทึก |
| การเข้าถึง | ตัวเลือกจำกัด | แปลงรูปแบบได้ทุกอย่าง |
Multimodal AI ทำงานอย่างไร
สถาปัตยกรรม
-
Encoders (หนึ่งต่อ modality)
- Text encoder: แปลงข้อความเป็นตัวเลข
- Image encoder: แปลงรูปภาพเป็นเวกเตอร์คุณลักษณะ
- Audio encoder: แปลงเสียงเป็นคุณลักษณะสเปกตรัม
-
Fusion Layer
- รวมการแทนค่าที่เข้ารหัสแล้ว
- เรียนรู้ความสัมพันธ์ระหว่าง modalities
- สร้างความเข้าใจรวม
-
Decoder / Output Head
- สร้าง output ที่เหมาะสม
- สามารถเป็นข้อความ การจำแนก ข้อมูลที่จัดโครงสร้าง ฯลฯ
ตัวอย่างขั้นตอน: การประมวลผลบัตรประชาชนไทย
Input: รูปถ่ายบัตรประชาชนไทย
ขั้นตอนที่ 1: Image Encoder
→ ตรวจจับขอบเขตเอกสาร
→ ระบุประเภทบัตร (บัตรประชาชนไทย)
→ ระบุตำแหน่งข้อความและรูปถ่าย
ขั้นตอนที่ 2: OCR Processing
→ แยกข้อความภาษาไทยจากแต่ละส่วน
→ จัดการความละเอียดอ่อนของอักษรไทย
→ อ่านทั้งข้อความพิมพ์และข้อความเครื่อง
ขั้นตอนที่ 3: Face Processing
→ แยกใบหน้าจากรูปในบัตร
→ สร้าง face embedding
→ พร้อมสำหรับการยืนยัน
ขั้นตอนที่ 4: Fusion & Validation
→ รวมข้อมูลที่แยกออกมาทั้งหมด
→ ตรวจสอบรูปแบบฟิลด์
→ ตรวจสอบความสอดคล้อง
Output: JSON ที่จัดโครงสร้างพร้อมฟิลด์ทั้งหมด
{
"name_th": "สมชาย ใจดี",
"name_en": "Somchai Jaidee",
"id_number": "1-1234-56789-01-2",
"birth_date": "1990-01-15",
"face_embedding": [...],
"confidence": 0.98
}
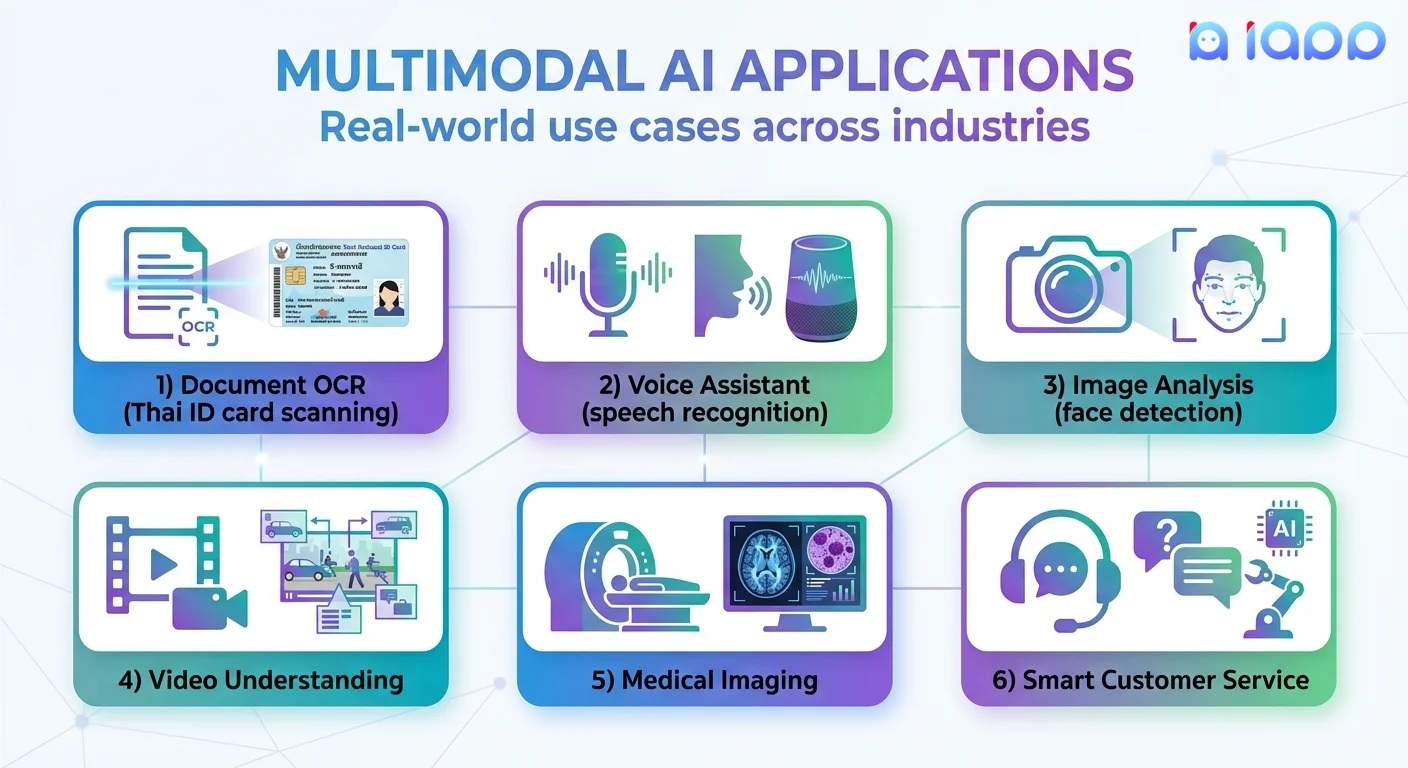
Multimodal AI ในประเทศไทย: การใช้งานจริง
1. Thai Document OCR
ใช้ Thai National ID OCR:
- สแกนบัตรประชาชนไทย พาสปอร์ต ใบขับขี่
- แยกข้อความไทยและอังกฤษได้แม่นยำ
- รองรับสภาพเอกสารและมุมต่างๆ
- ส่งคืนข้อมูลที่จัดโครงสร้างเพื่อการผสานรวมง่าย
2. การยืนยันใบหน้า & eKYC
รวม Face Recognition กับ document AI:
- จับคู่ใบหน้าจากบัตรกับรูปเซลฟี่
- Liveness Detection ป้องกันการปลอมแปลงด้วยรูปถ่าย
- กระบวนการ eKYC เสร็จในไม่กี่วินาที
- มาตรฐานความปลอดภัยระดับธนาคาร
3. Thai Speech Recognition
ใช้ Thai Speech-to-Text:
- แปลงเสียงพูดไทยเป็นข้อความด้วยความแม่นยำสูง
- รองรับสำเนียงและภาษาถิ่นไทยต่างๆ
- ถอดความแบบเรียลไทม์สำหรับ call center
- ถอดความการประชุมและคำสั่งเสียง
4. Thai Text-to-Speech
ใช้ Thai Text-to-Speech:
- สังเคราะห์เสียงไทยที่เป็นธรรมชาติ
- ตัวเลือกเสียงหลากหลาย (ชาย/หญิง)
- ระบบ IVR และผู้ช่วยเสียง
- หนังสือเสียงและการบรรยายเนื้อหา
5. การแปลหลายภาษา
ใช้ Translation API:
- แปลระหว่างไทย อังกฤษ จีน ญี่ปุ่น
- รวมกับเสียงสำหรับการแปลแบบเรียลไทม์
- แปลเอกสารพร้อมรักษารูปแบบ
สร้างด้วย Multimodal AI ของ iApp
iApp Technology ให้บริการ Multimodal AI API ครบวงจรสำหรับธุรกิจไทย:
ส่วนประกอบที่มี
| Modality | ผลิตภัณฑ์ iApp | ความสามารถ |
|---|---|---|
| รูปภาพ → ข้อความ | Thai OCR APIs | บัตรประชาชน เอกสาร ใบเสร็จ |
| รูปภาพ → ข้อมูล | Face Recognition | ตรวจจับใบหน้า จับคู่ ความมีชีวิต |
| เสียง → ข้อความ | Speech-to-Text | ถอดเสียงพูดไทย |
| ข้อความ → เสียง | Text-to-Speech | สังเคราะห์เสียงไทยธรรมชาติ |
| ข้อความ → ข้อความ | Translation | แปลหลายภาษา |
| ข้อความ → ข้อความ | OpenThai Chinda | เข้าใจภาษาไทย |
ตัวอย่าง: กระบวนการ eKYC เต็มรูปแบบ
import requests
def complete_ekyc_verification(id_card_image, selfie_image):
"""
eKYC เต็มรูปแบบด้วย Multimodal AI:
1. OCR เพื่อแยกข้อมูลบัตร (รูปภาพ → ข้อความ)
2. แยกใบหน้าจากบัตร (รูปภาพ → Embedding)
3. แยกใบหน้าเซลฟี่ (รูปภาพ → Embedding)
4. เปรียบเทียบใบหน้า (Embedding → คะแนนจับคู่)
5. ตรวจสอบความมีชีวิต (วิดีโอ → Boolean)
"""
# ขั้นตอนที่ 1: แยกข้อมูลจากบัตรประชาชน
ocr_response = requests.post(
'https://api.iapp.co.th/thai-national-id-ocr/v3',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': id_card_image}
)
id_data = ocr_response.json()
# ขั้นตอนที่ 2: เปรียบเทียบใบหน้า
face_response = requests.post(
'https://api.iapp.co.th/face-recognition/v1/compare',
headers={'apikey': 'YOUR_API_KEY'},
files={
'image1': id_card_image,
'image2': selfie_image
}
)
face_match = face_response.json()
# ขั้นตอนที่ 3: ตรวจสอบความมีชีวิต (ป้องกันการปลอม)
liveness_response = requests.post(
'https://api.iapp.co.th/liveness-detection/v1',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': selfie_image}
)
is_live = liveness_response.json()
return {
'id_data': id_data,
'face_match_score': face_match['similarity'],
'is_live_person': is_live['is_live'],
'verified': face_match['similarity'] > 0.8 and is_live['is_live']
}
เริ่มต้นใช้งาน Multimodal AI
ขั้นตอนที่ 1: ระบุ Use Case ของคุณ
จุดเริ่มต้นที่พบบ่อย:
- ประมวลผลเอกสาร: เริ่มด้วย Thai OCR
- แอปพลิเคชันเสียง: เริ่มด้วย Speech APIs
- ยืนยันตัวตน: เริ่มด้วย eKYC suite
ขั้นตอนที่ 2: ทดลอง APIs
ทดสอบกับข้อมูลจริง:
- รับ API key ของคุณ
- ลองใช้ interactive demos ในหน้าผลิตภัณฑ์แต่ละหน้า
- ศึกษารูปแบบ response
ขั้นตอนที่ 3: ผสานรวม
- ใช้ REST APIs จากภาษาโปรแกรมใดก็ได้
- SDKs มีให้สำหรับ Python, JavaScript และอื่นๆ
- เอกสารครบถ้วนพร้อมตัวอย่าง
แหล่งข้อมูล
- รับ API Access: จัดการ API Key
- ลอง Thai OCR: Document OCR Demo
- ลอง Speech AI: Speech-to-Text Demo
- สำรวจ APIs ทั้งหมด: แคตตาล็อก API ครบ
- เข้าร่วมชุมชน: Discord
อนาคตของ Multimodal AI
แนวโน้มที่ควรติดตาม
- การประมวลผลแบบเรียลไทม์: โมเดลที่เร็วขึ้นทำให้วิเคราะห์วิดีโอสดและแปลพร้อมกันได้
- Multimodal บนอุปกรณ์: ใช้ Multimodal AI ซับซ้อนบนสมาร์ทโฟนและอุปกรณ์ edge
- โมเดลเฉพาะไทย: เข้าใจภาษาและเอกสารไทยได้ดีขึ้น
- Generative Multimodal: AI ที่สร้างรูปภาพ เสียง และวิดีโอจาก text prompts
- โมเดลสากล: โมเดลเดียวที่รองรับทุก modalities ได้อย่างราบรื่น
ทำไมธุรกิจไทยควรลงมือตอนนี้
- ได้เปรียบในการแข่งขัน: ทำงานเอกสารและเสียงอัตโนมัติก่อนคู่แข่ง
- ประสบการณ์ลูกค้า: เสนอการสนับสนุนหลายช่องทางที่ราบรื่น
- ลดต้นทุน: แทนที่การกรอกข้อมูลและตรวจสอบด้วยมือ
- ปรับปรุงความแม่นยำ: ลดข้อผิดพลาดของมนุษย์ในการประมวลผลเอกสาร
- ขยายขนาดการดำเนินงาน: รับมือปริมาณมากขึ้นโดยไม่ต้องเพิ่มพนักงานตามส่วน
สรุป
Multimodal AI เป็นการเปลี่ยนแปลงพื้นฐานสู่ระบบ AI ที่เข้าใจโลกเหมือนมนุษย์มากขึ้น - ผ่านประสาทสัมผัสหลายอย่างที่ทำงานร่วมกัน ตั้งแต่การอ่านบัตรประชาชนไทยไปจนถึงการถอดเสียงสายโทรศัพท์และการยืนยันตัวตน Multimodal AI กำลังเปลี่ยนแปลงวิธีการดำเนินธุรกิจ
สำหรับธุรกิจไทย iApp Technology ให้เครื่องมือครบชุด: Thai OCR สำหรับเอกสาร, Face Recognition สำหรับตัวตน, Speech-to-Text สำหรับเสียง และ Thai LLM สำหรับการเข้าใจภาษา - ทั้งหมดปรับแต่งสำหรับภาษาและการใช้งานไทย
พร้อมเพิ่ม Multimodal AI ในแอปพลิเคชันของคุณแล้วหรือยัง? ลงทะเบียนฟรี และเริ่มต้นด้วย Thai OCR หรือ Speech APIs วันนี้!
มีคำถาม? เข้าร่วม Discord Community ของเราหรือส่งอีเมลมาที่ support@iapp.co.th
บริษัท ไอแอพพ์ เทคโนโลยี จำกัด บริษัท AI ชั้นนำของประเทศไทย