Machine Learning คืออะไร? คู่มือฉบับสมบูรณ์สำหรับผู้เริ่มต้น

ทุกครั้งที่ Netflix แนะนำหนังที่คุณอยากดูจริงๆ หรืออีเมลของคุณกรองสแปมออกโดยอัตโนมัติ หรือโทรศัพท์ของคุณจดจำใบหน้าเพื่อปลดล็อก — นั่นคือ Machine Learning ที่ทำงานอยู่ มันคือเทคโนโลยีที่ทำให้คอมพิวเตอร์สามารถเรียนรู้จากประสบการณ์แทนที่จะถูกโปรแกรมอย่างชัดเจนสำหรับทุกงาน และมันกำลังปฏิวัติแทบทุกอุตสาหกรรม
Machine Learning คืออะไร?
Machine Learning (ML) คือสาขาย่อยของปัญญาประดิษฐ์ที่ให้ความสามารถแก่คอมพิวเตอร์ในการเรียนรู้และปรับปรุงจากประสบการณ์โดยไม่ต้องถูกโปรแกรมอย่างชัดเจน แทนที่จะเขียนกฎสำหรับทุกสถานการณ์ เราป้อนข้อมูลให้เครื่องและปล่อยให้มันค้นพบรูปแบบด้วยตัวเอง
ลองค�ิดแบบนี้:
- การโปรแกรมแบบดั้งเดิม: มนุษย์เขียนกฎ → คอมพิวเตอร์ทำตามกฎ → ผลลัพธ์
- Machine Learning: มนุษย์ให้ข้อมูล → คอมพิวเตอร์เรียนรู้รูปแบบ → คอมพิวเตอร์สร้างกฎ → ผลลัพธ์
โดยหลักแล้ว machine learning:
- เรียนรู้ รูปแบบจากข้อมูลประวัติ
- ปรับปรุง ประสิทธิภาพด้วยประสบการณ์มากขึ้น
- ทำนาย ผลลัพธ์สำหรับข้อมูลใหม่ที่ไม่เคยเห็น
- ปรับตัว ตามสภาพที่เปลี่ยนแปลงโดยอัตโนมัติ
ตัวอย่างง่ายๆ
การโปรแกรมแบบดั้งเดิม:
ถ้า อีเมลมีคำว่า "เงินฟรี" และ ผู้ส่งไม่รู้จัก
แล้ว ทำเครื่องหมายเป็นสแปม
(คุณต้องเขียนกฎสำหรับทุกรูปแบบสแปม — เป็นไปไม่ได้ที่จะครอบคลุมทุกกรณี!)
Machine Learning:
การฝึก: แสดงโมเดล 10,000 อีเมลสแปมและ 10,000 อีเมลปกติ
ผลลัพธ์: โมเดลเรียนรู้ว่าสแปม "มีลักษณะ" อย่างไร
การใช้งาน: โมเดลตรวจจับรูปแบบสแปมใหม่ที่คุณไม่เคยโปรแกรมโดยอัตโนมัติ
ประเภทของ Machine Learning
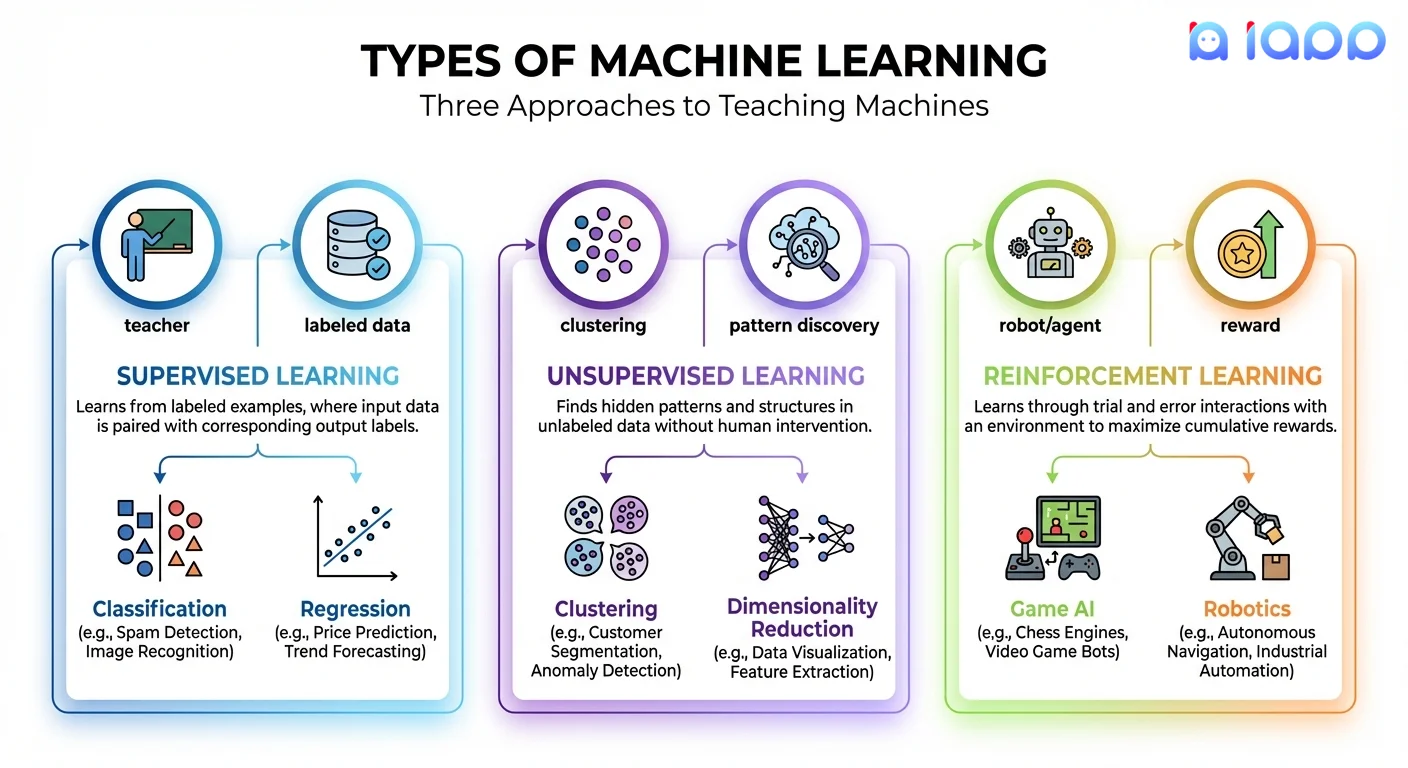
1. Supervised Learning (การเรียนรู้แบบมีผู้สอน)
โมเดลเรียนรู้จากข้อมูลที่มีป้ายกำกับ — ตัวอย่างที่เรารู้คำตอบที่ถูกต้อง
วิธีทำงาน:
- ข้อมูลฝึกรวม inputs และ outputs ที่ถูกต้อง
- โมเดลเรียนรู้ความสัมพันธ์ระหว่างมัน
- โมเดลสามารถทำนาย outputs สำหรับ inputs ใหม่
ประเภท:
- Classification: ทำนายหมวดหมู่ (สแปม/ไม่ใช่สแปม, แมว/หมา, ฉ้อโกง/ถูกต้อง)
- Regression: ทำนายตัวเลข (ราคา, อุณหภูมิ, ยอดขาย)
ตัวอย่าง:
- การตรวจจับอีเมลสแปม
- การทำนายคะแนนเครดิต
- การวินิจฉัยทางการแพทย์
- การจดจำภาพ
เหมาะสำหรับ: ปัญหาที่คุณมีข้อมูลประวัติพร้อมผลลัพธ์ที่รู้แล้ว
2. Unsupervised Learning (การเรียนรู้แบบไม่มีผู้สอน)
โมเดลหารูปแบบที่ซ่อนอยู่ในข้อมูลโดยไม่ได้รับการบอกว่าต้องหาอะไร
วิธีทำงาน:
- ข้อมูลฝึกไม่มีป้ายกำกับ
- โมเดลค้นพบโครงสร้างด้วยตัวเอง
- หากลุ่ม รูปแบบ หรือความผิดปกติ
ประเภท:
- Clustering: จัดกลุ่มรายการที่คล้ายกัน (กลุ่มลูกค้า, หัวข้อเอกสาร)
- Dimensionality Reduction: ลดความซับซ้อนของข้อมูลพร้อมรักษาคุณลักษณะสำคัญ
- Anomaly Detection: หารูปแบบผิดปกติ (การฉ้อโกง, ข้อบกพร่อง)
ตัวอย่าง:
- การแบ่งกลุ่มลูกค้า
- ระบบแนะนำ
- การตรวจจับความผิดปกติ
- การวิเคราะห์ตะกร้าสินค้า
เหมาะสำหรับ: การสำรวจ หาโครงสร้างในข้อมูล เมื่อไม่รู้ว่าต้องหาอะไร
3. Reinforcement Learning (การเรียนรู้แบบเสริมแรง)
โมเดลเรียนรู้ผ่านการลองผิดลองถูก รับรางวัลสำหรับการกระทำที่ดี
วิธีทำงาน:
- Agent ทำการกระทำในสภาพแวดล้อม
- ได้รับรางวัลหรือบทลงโทษ
- เรียนรู้เพื่อเพิ่มรางวัลรวมตลอดเวลา
ส่วนประกอบ:
- Agent: ผู้เรียน/ผู้ตัดสินใจ
- Environment: สิ่งที่ agent โต้ตอบด้วย
- Actions: สิ่งที่ agent สามารถทำได้
- Rewards: สัญญาณ feedback
ตัวอย่าง:
- Game AI (AlphaGo, chess engines)
- การควบคุมหุ่นยนต์
- รถยนต์ไร้คนขับ
- การปรับทรัพยากรให้เหมาะสม
เหมาะสำหรับ: การตัดสินใจตามลำดับ ปัญหาการควบคุม เกม
คำศัพท์ Machine Learning สำคัญที่ควรรู้
1. Model (โมเดล)
คืออะไร: การแทนค่าทางคณิตศาสตร์ที่อัลกอริทึม machine learning สร้างหลังการฝึก
เปรียบเทียบง่ายๆ: เหมือนสมองของนักเรียนหลังเรียน — มัน "เรียนรู้" รูปแบบและตอนนี้สามารถตอบคำถามเกี่ยวกับตัวอย่างใหม่ได้
ในทางปฏิบัติ: โมเดลที่ฝึกแล้วคือไฟล์ที่มีรูปแบบที่เรียนรู้และสามารถทำนายข้อมูลใหม่ได้
2. Training (การฝึก)
คืออะไร: กระบวนการป้อนข้อมูลให้อัลกอริทึมเพื่อเรียนรู้รูปแบบ
เปรียบเทียบง่ายๆ: เหมือนสอนเด็กให้จำสัตว์โดยแสดงรูปภาพหลายรูปพร้อมป้ายกำกับ
กระบวนการ:
- ป้อนข้อมูลฝึกให้อัลกอริทึม
- อัลกอริทึมปรับพารามิเตอร์ภายใน
- ทำซ้ำจนกว่าความแม่นยำจะน่าพอใจ
- ผลลัพธ์: โมเดลที่ฝึกแล้ว
3. Features (คุณลักษณะ)
คืออะไร: ตัวแปร input หรือคุณลักษณะที่ใช้ในการทำนาย
เปรียบ��เทียบง่ายๆ: เมื่อคุณอธิบายบ้านเพื่อทำนายราคา features อาจเป็น: ตารางเมตร, จำนวนห้องนอน, ทำเล, อายุ
ตัวอย่าง:
- สำหรับการตรวจจับสแปม: ผู้ส่ง, คำสำคัญในหัวเรื่อง, จำนวนลิงก์, เวลาส่ง
- สำหรับการจดจำใบหน้า: ค่าพิกเซล, รูปแบบขอบ, จุดสังเกตใบหน้า
4. Overfitting vs Underfitting
Overfitting: โมเดลจำข้อมูลฝึกแต่ล้มเหลวกับข้อมูลใหม่ (ซับซ้อนเกินไป)
- เหมือนนักเรียนที่ท่องจำคำตอบข้อสอบแต่แก้ปัญหาใหม่ไม่ได้
Underfitting: โมเดลง่ายเกินไปที่จะจับรูปแบบได้ (พื้นฐานเกินไป)
- เหมือนนักเรียนที่อ่านหนังสือไม่พอและตอบคำถามอะไรไม่ได้
เป้าหมาย: หาจุดที่เหมาะสมที่โมเดล generalize ได้ดีกับข้อมูลใหม่
5. Neural Network / Deep Learning
คืออะไร: โมเดล ML ประเภทหนึ่งที่ได้แรงบันดาลใจจากสมองมนุษย์ มีเลเยอร์ของ "neurons" ที่เชื่อมต่อกัน
เปรียบเทียบง่ายๆ: เหมือนทีมผู้เชี่ยวชาญ — แต่ละเลเยอร์แยกความเข้าใจระดับต่างๆ จากคุณลักษณะง่ายๆ ไปจนถึงแนวคิดที่ซับซ้อน
Deep Learning: Neural networks ที่มีหลายเลเยอร์ — "deep" หมายถึงความลึกของเลเยอร์
ขับเคลื่อน: การจดจำภาพ, การจดจำเสียง, การแปลภาษา, Generative AI
ทำไม Machine Learning ถึงสำคัญ
1. การทำงานอัตโนมัติของงานซับซ้อน
ML สามารถทำงานที่ซับซ้อนเกินกว่าจะโปรแกรมด้วยกฎแบบดั้งเดิม:
- เข้าใจภาษามนุษย์
- จดจำภาพและใบหน้า
- ทำนายผลลัพธ์ที่ซับซ้อน
2. การปรับปรุงอย่างต่อเนื่อง
ไม่เหมือนโปรแกรมคงที่ โมเดล ML สามารถ:
- ปรับปรุงด้วยข้อมูลมากขึ้น
- ปรับตัวตามรูปแบบที่เปลี่ยนแปลง
- ฉลาดขึ้นตามเวลา
3. การจัดการขนาดใหญ่
ML ประมวลผลข้อมูลจำนวนมากที่มนุษย์วิเคราะห์ไม่ได้:
- ล้านธุรกรรม
- พันล้านการโต้ตอบของผู้ใช้
- ข้อมูลสตรีมแบบเรียลไทม์
4. การปรับแต่งส่วนบุคคล
ML เปิดใช้ประสบการณ์ส่วนบุคคลในระดับใหญ่:
- คำแนะนำผลิตภัณฑ์
- การคัดสรรเนื้อหา
- โฆษณาเป้าหมาย
5. การค้นพบ
ML หารูปแบบที่มนุษย์อาจพลาด:
- การค้นพบทางการแพทย์
- การค้นพบทางวิทยาศาสตร์
- ข้อมูลเชิงลึกทางธุรกิจ
Machine Learning แก้ปัญหาอะไร?
| ปัญหา | วิธีแบบดั้งเดิม | โซลูชัน Machine Learning |
|---|---|---|
| ตรวจจับสแปม | กฎแบบ manual | เรียนรู้รูปแบบอัตโนมัติ |
| ตรวจจับการฉ้อโกง | thresholds คงที่ | ปรับตัวตามรูปแบบการฉ้อโกงใหม่ |
| การเลิกใช้บริการของลูกค้า | สัญชาตญาณ | ทำนายว่าใครจะออก |
| การจำแนกภาพ | เป็นไปไม่ได้ | จดจำวัตถุ ใบหน้า ข้อความ |
| การแปลภาษา | ค้นหาพจนานุกรม | เข้าใจบริบทและความละเอียดอ่อน |
| คำแนะนำ | การกรองพื้นฐาน | คำแนะนำส่วนบุคคล |
| การพยากรณ์ความต้องการ | ค่าเฉลี่ยประวัติ | การทำนายที่แม่นยำ |
Machine Learning ทำงานอย่างไร
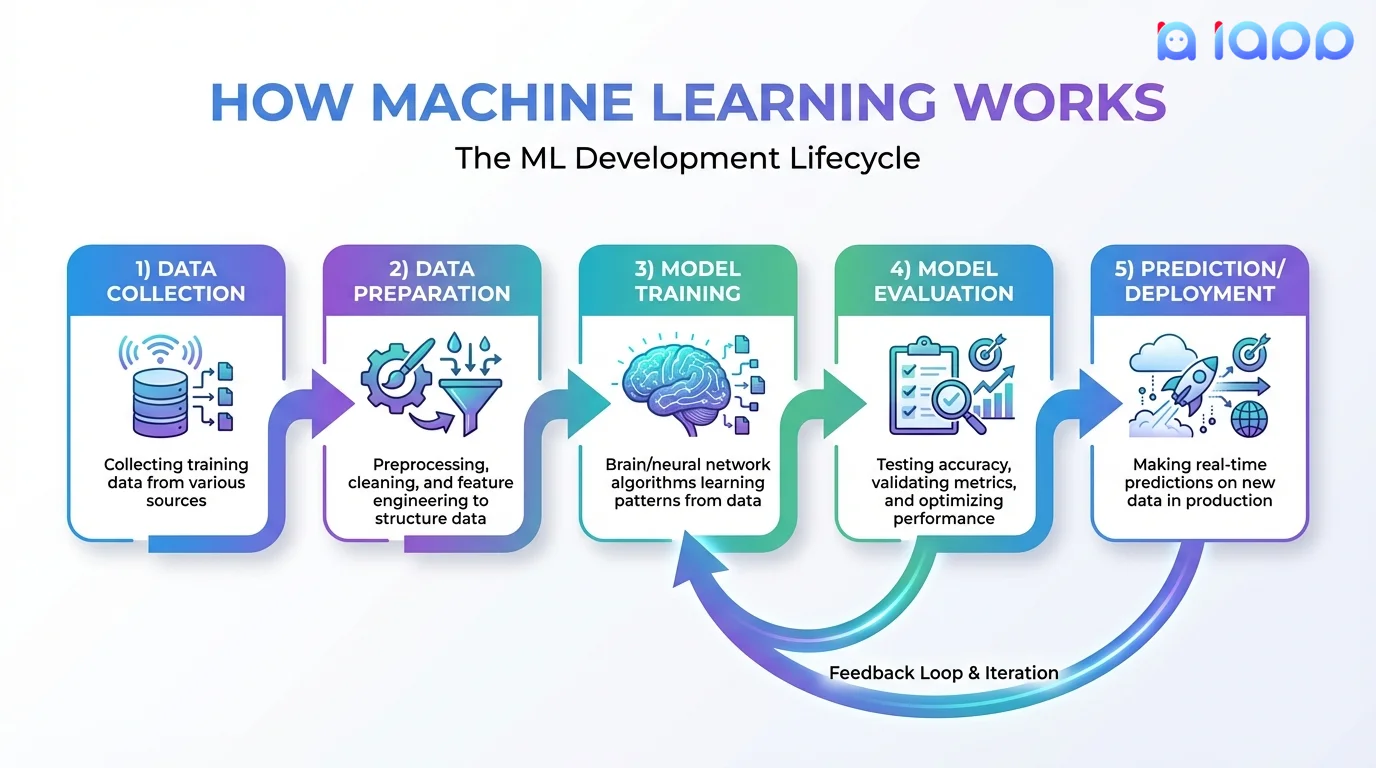
วงจรการพัฒนา ML
-
การเก็บข้อมูล
- รวบรวมข้อมูลฝึกที่เกี่ยวข้อง
- ข้อมูลมากขึ้นโดยทั่วไป = โมเดลดีขึ้น
- คุณภาพสำคัญเท่าๆ กับปริมาณ
-
การเตรียมข้อมูล
- ทำความสะอาดและประมวลผลข้อมูลล่วงหน้า
- จัดการค่าที่หายไป
- Feature engineering (สร้าง inputs ที่มีประโยชน์)
- แบ่งเป็นชุดฝึกและทดสอบ
-
การฝึกโมเดล
- เลือกอัลกอริทึมที่เหมาะสม
- ป้อนข้อมูลฝึกให้โมเดล
- โมเดลเรียนรู้รูปแบบแบบวนซ้ำ
- ปรับพารามิเตอร์เพื่อประสิทธิภาพที่ดีที่สุด
-
การประเมินโมเดล
- ทดสอบกับข้อมูลที่แยกไว้
- วัดความแม่นยำ precision recall
- ตรวจสอบ overfitting/underfitting
- เปรียบเทียบโมเดลต่างๆ
-
การ Deploy และทำนาย
- Deploy โมเดลสู่ production
- ทำนายกับข้อมูลใหม่
- ติดตามประสิทธิภาพ
- ฝึกใหม่เมื่อจำเป็น
ตัวอย่าง: Thai ID Card OCR
ปัญหา: แยกข้อความจากรูปบัตรประชาชนไทย
ขั้นตอนการฝึก:
1. เก็บ: รูปบัตรประชาชนไทย 100,000 รูปพร้อมข้อความที่ป้ายกำกับ
2. เตรียม: ครอป ปรับขนาด เพิ่มรูปภาพ
3. ฝึก: CNN เรียนรู้ที่จะจดจำตัวอักษรไทย
4. ประเมิน: ความแม่นยำ 99.5% บนชุดทดสอบ
5. Deploy: API พร้อมใช้งานจริง
การ Inference (การใช้งาน):
Input: รูปบัตรประชาชนไทยใหม่
↓
โมเดลประมวลผลภาพ
↓
Output: {"name": "สมชาย ใจดี", "id": "1-2345-67890-12-3", ...}
Machine Learning ในประเทศไทย: การใช้งานจริง
1. Thai OCR และการประมวลผลเอกสาร
ใช้ Thai OCR APIs:
- โมเดล ML ที่ฝึกกับเอกสารไทยหลายล้านฉบับ
- จดจำอักษรไทยด้วยความแม่นยำสูง
- แยกข้อมูลที่มีโครงสร้างจากบัตรประชาชน พาสปอร์ต เอกสาร
- รองรับฟอนต์ต่างๆ ลายมือ และสภาพต่างๆ
2. Thai Speech Recognition
ใช้ Speech-to-Text:
- โมเดล deep learning ที่ฝึกกับเสียงพูดไทย
- เข้าใจสำเนียงและภาษาถิ่นต่างๆ
- รองรับเสียงรบกวนพื้นหลังและผู้พูดหลายคน
- ความสามารถถอดความแบบเรียลไทม์
3. Thai Natural Language Processing
ใช้ DeepSeek V4:
- Large language model ที่ฝึกกับข้อความไทย
- เข้าใจไวยากรณ์และบริบทไทย
- สร้างคำตอบไทยที่เป็นธรรมชาติ
- ขับเคลื่อน chatbots และการวิเคราะห์ข้อความ
4. Face Recognition และ Verification
ใช้ Face Recognition:
- Deep learning สำหรับการตรวจจับและจับคู่ใบหน้า
- ทำงานได้กับมุมและแสงต่างๆ
- Liveness detection เพื่อป้องกันการปลอมแปลง
- ความแม่นยำและความปลอดภัยระดับธนาคาร
5. การแปลภาษา
ใช้ Translation API:
- Neural machine translation
- รักษาบริบทและความหมาย
- รองรับไทย อังกฤษ จีน ญี่ปุ่น
- รองรับสำนวนและการแสดงออกทางวัฒนธรรม
สร้างด้วย ML-Powered APIs ของ iApp
iApp Technology ให้บริการโมเดล ML ที่ฝึกไว้แล้วเป็น APIs ที่ใช้งานง่าย:
บริการ ML ที่มี
| งาน ML | ผลิตภัณฑ์ iApp | ประเภทโมเดล |
|---|---|---|
| Thai OCR | Thai OCR APIs | CNN + Transformer |
| Speech Recognition | Speech-to-Text | Deep Neural Network |
| Face Recognition | Face Recognition | Deep CNN |
| Thai Language | OpenThai Chinda | Large Language Model |
| Translation | Translation API | Neural MT |
| Text-to-Speech | Text-to-Speech | Neural TTS |
ตัวอย่าง: ใช้ ML สำหรับการประมวลผลเอกสารไทย
import requests
def process_document_with_ml(image_path):
"""
ใช้ OCR ที่ขับเคลื่อนด้วย ML ของ iApp เพื่อแยกข้อมูลจากเอกสารไทย
"""
with open(image_path, 'rb') as f:
response = requests.post(
'https://api.iapp.co.th/thai-national-id-ocr/v3',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': f}
)
result = response.json()
# โมเดล ML แยกข้อมูลที่มีโครงสร้างแล้ว
return {
'name_th': result.get('name_th'),
'name_en': result.get('name_en'),
'id_number': result.get('id_number'),
'date_of_birth': result.get('date_of_birth'),
'address': result.get('address'),
'confidence': result.get('confidence')
}
# ตัวอย่างการใช้งาน
data = process_document_with_ml('thai_id_card.jpg')
print(f"ชื่อที่แยกได้: {data['name_th']}")
print(f"ความมั่นใจ: {data['confidence']}")
ตัวอย่าง: การวิเคราะ��ห์ข้อความไทยด้วย ML
import requests
def analyze_thai_text(text):
"""
ใช้ OpenThai Chinda เพื่อวิเคราะห์ข้อความไทย
"""
response = requests.post(
'https://api.iapp.co.th/v3/llm/deepseek-v4/chat/completions',
headers={
'apikey': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
json={
'model': 'deepseek-v4-flash',
'messages': [{
'role': 'user',
'content': f"""วิเคราะห์ข้อความต่อไปนี้:
"{text}"
กรุณาสรุป:
1. ความรู้สึก (บวก/ลบ/เป็นกลาง)
2. หัวข้อหลัก
3. ประเด็นสำคัญ"""
}],
'max_tokens': 512
}
)
return response.json()['choices'][0]['message']['content']
# ตัวอย่างการใช้งาน
result = analyze_thai_text("สินค้าคุณภาพดีมาก ส่งเร็ว แพคอย่างดี จะกลับมาซื้ออีก")
print(result)
เริ่มต้นใช้งาน Machine Learning
สำหรับผู้ใช้ธุรกิจ
คุณไม่จำเป็นต้องสร้างโมเดล ML จากศูนย์! ใช้โมเดลที่ฝึกไว้แล้วผ่าน APIs:
- ระบุ use case ของคุณ: การประมวลผลเอกสาร? เสียง? การจดจำใบหน้า?
- เลือก API ที่เหมาะสม: ดูแคตตาล็อก API ของ iApp
- รับ API key ของคุณ: ลงทะเบียนฟรี
- ผสานรวม: การเรียก REST API ง่ายๆ จากภาษาใดก็ได้
- ขยายขนาด: จ่ายเฉพาะสิ่งที่ใช้
สำหรับนักพัฒนาและ Data Scientists
อยากเข้าใจ ML ลึกซึ้งกว่านี้?
- เรียนรู้พื้นฐาน: Linear regression, decision trees, neural networks
- ฝึกฝนกับข้อมูล: Kaggle competitions, public datasets
- ใช้ frameworks: TensorFlow, PyTorch, scikit-learn
- เร��ิ่มจากง่าย: เริ่มด้วย supervised learning classification
- สร้างโปรเจกต์: ประยุกต์ใช้ ML กับปัญหาจริง
แหล่งข้อมูล
- รับ API Access: จัดการ API Key
- ลอง Thai OCR: Document OCR Demo
- ลอง Speech AI: Speech-to-Text Demo
- ลอง Thai LLM: Chinda Demo
- เข้าร่วมชุมชน: Discord
อนาคตของ Machine Learning
แนวโน้มที่ควรติดตาม
- Foundation Models: โมเดลที่ฝึกไว้ขนาดใหญ่ที่ปรับใช้กับงานหลายอย่างได้
- AutoML: Machine learning อัตโนมัติลดความต้องการผู้เชี่ยวชาญ
- Edge ML: ใช้โมเดลบนอุปกรณ์แทน cloud
- Multimodal ML: โมเดลที่เข้าใจข้อความ ภาพ เสียง พร้อมกัน
- Responsible AI: เน้นความเป็นธรรม ความโปร่งใส และความเป็นส่วนตัว
ทำไมธุรกิจไทยควรใช้ ML ตอนนี้
- ได้เปรียบในการแข่งขัน: ระบบอัตโนมัติและข้อมูลเชิงลึกที่ขับเคลื่อนด้วย ML
- ลดต้นทุน: ทำงาน manual ซ้ำๆ อัตโนมัติ
- การตัดสินใจที่ดีขึ้น: ขับเคลื่อนด้วยข้อมูลแทนสัญชาตญาณ
- ประสบการณ์ลูกค้า: การปรับแต่งส่วนบุคคลและบริการที��่เร็วขึ้น
- นวัตกรรม: ผลิตภัณฑ์และบริการใหม่ที่ ML เปิดใช้งาน
สรุป
Machine Learning คือเทคโนโลยีที่ทำให้คอมพิวเตอร์เรียนรู้จากข้อมูลและปรับปรุงตลอดเวลา ตั้งแต่การจดจำข้อความไทยไปจนถึงการเข้าใจเสียงพูดและการตรวจจับการฉ้อโกง ML ขับเคลื่อนแอปพลิเคชันอัจฉริยะที่กำลังเปลี่ยนแปลงทุกอุตสาหกรรม
ข่าวดีก็คือ คุณไม่จำเป็นต้องมีปริญญาเอกใน machine learning เพื่อได้รับประโยชน์จากมัน iApp Technology ให้บริการโมเดล ML ที่ฝึกไว้แล้วเป็น APIs ง่ายๆ — Thai OCR สำหรับการประมวลผลเอกสาร, Speech-to-Text สำหรับเสียง, Face Recognition สำหรับการยืนยันตัวตน และ OpenThai Chinda สำหรับการเข้าใจภาษาไทย
พร้อมเพิ่ม machine learning ในแอปพลิเคชันของคุณแล้วห��รือยัง? ลงทะเบียนฟรี และเริ่มใช้ ML-powered APIs ของเราวันนี้!
มีคำถาม? เข้าร่วม Discord Community ของเราหรือส่งอีเมลมาที่ support@iapp.co.th
บริษัท ไอแอพพ์ เทคโนโลยี จำกัด บริษัท AI ชั้นนำของประเทศไทย