Deep Learning คืออะไร? คู่มือฉบับสมบูรณ์สำหรับผู้เริ่มต้น

เมื่อโทรศัพท์ของคุณจดจำใบหน้าได้ในเสี้ยววินาที เมื่อ Google Translate แปลภาษาไทยเป็นอังกฤษได้อย่างแม่นยำ หรือเมื่อ ChatGPT สร้างคำตอบที่เหมือนมนุษย์ — นั่นคือ Deep Learning กำลังทำงานอยู่ มันคือเทคโนโลยีเบื้องหลังความก้าวหน้าด้าน AI เกือบทุกอย่างในทศวรรษที่ผ่านมา และกำลังเปลี่ยนแปลงสิ่งที่คอมพิวเตอร์สามารถทำได้
Deep Learning คืออะไร?
Deep Learning (การเรียนรู้เชิงลึก) คือสาขาย่อยของ Machine Learning ที่ใช้โครงข่ายประสาทเทียม (Neural Networks) หลายชั้นเพื่อเรียนรู้จากข้อมูลจำนวนมหาศาล คำว่า "Deep" หมายถึงความลึกของชั้นต่างๆ ในโครงข่ายประสาทเทียม — ตั้งแต่เครือข่ายง่ายๆ 3 ชั้น ไปจนถึงโมเดลขนาดใหญ่ที่มีหลายร้อยชั้น
ลองคิดแบบนี้:
- Traditional Programming: มนุษย์เขียนกฎอย่างชัดเจน
- Machine Learning: คอมพิวเตอร์เรียนรู้รูปแบบจากข้อมูล
- Deep Learning: คอมพิวเตอร์เรียนรู้รูปแบบที่ซับซ้อนผ่านหลายชั้นของการสกัดความหมาย
โดยพื้นฐาน Deep Learning:
- เรียนรู้ การแทนค่าแบบลำดับชั้นจากข้อมูลดิบ
- ค้นพบ คุณลักษณะโดยอัตโนมัติ (ไม่ต้องกำหนด Feature ด้วยมือ)
- จัดการ ข้อมูลที่ไม่มีโครงสร้างเช่น รูปภาพ เสียง และข้อความ
- ขยายขนาด ได้ตามข้อมูลและพลังการประมวลผลที่เพิ่มขึ้น
การเปรียบเทียบง่ายๆ
ลองนึกภาพการสอนเด็กให้รู้จักแมว:
- Traditional Programming: ระบุทุกกฎ (มีขน สี่ขา หูแหลม มีหนวด...)
- Machine Learning: แสดงตัวอย่างและให้เด็กหารูปแบบเอง
- Deep Learning: เด็กเรียนรู้ขอบก่อน → จากนั้นรูปทรง → จากนั้นส่วนต่างๆ ของร่างกาย → สุดท้ายคือแมวทั้งตัว
แต่ละชั้นสร้างต่อจากชั้นก่อนหน้า เรียนรู้แนวคิดที่เป็นนามธรรมมากขึ้นเรื่อยๆ
Deep Learning ทำงานอย่างไร
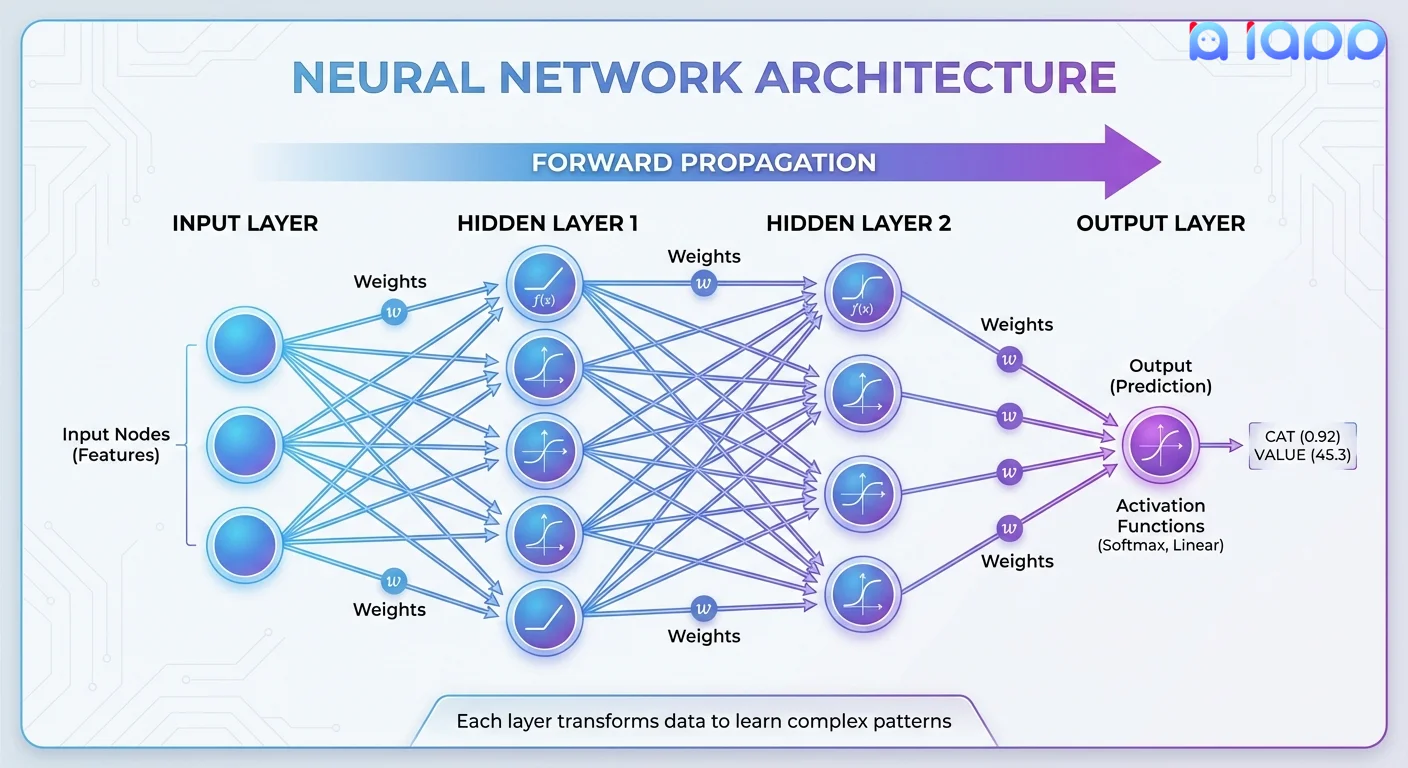
โครงสร้างของโครงข่ายประสาทเทียม
1. Input Layer (ชั้นนำเข้า)
- รับข้อมูลดิบ (พิกเซล คำ ตัวเลข)
- แต่ละโหนดแทนหนึ่งคุณลักษณะหรือค่าอินพุต
2. Hidden Layers (ชั้นซ่อน — ส่วน "Deep")
- หลายชั้นที่แปลงข้อมูล
- แต่ละชั้นเรียนรู้ระดับการสกัดความหมายที่แตกต่างกัน
- ยิ่งมีหลายชั้น = เครือข่ายยิ่งลึก = เรียนรู้รูปแบบที่ซับซ้อนมากขึ้น
3. Output Layer (ชั้นผลลัพธ์)
- สร้างการทำนายสุดท้าย
- อาจเป็นป้ายกำกับประเภท ความน่าจะเป็น หรือเนื้อหาที่สร้างขึ้น
กระบวนการเรียนรู้
ขั้นตอนที่ 1: Forward Propagation (การส่งผ่านไปข้างหน้า)
ข้อมูลไหลจาก input → ผ่าน hidden layers → ไปยัง output
แต่ละ neuron ใช้: output = activation(weights × inputs + bias)
ขั้นตอนที่ 2: Calculate Loss (คำนวณความผิดพลาด)
เปรียบเทียบการทำนายกับคำตอบจริง
Loss = ความผิดพลาดของการทำนาย
ขั้นตอนที่ 3: Backpropagation (การส่งผ่านย้อนกลับ)
คำนวณว่าแต่ละ weight มีส่วนในความผิดพลาดอย่างไร
ส่งความผิดพลาดย้อนกลับผ่านเครือข่าย
ขั้นตอนที่ 4: Update Weights (ปรับค่า Weights)
ปรับค่า weights เพื่อลดความผิดพลาด
ใช้อัลกอริทึมการปรับค่าเช่น SGD หรือ Adam
ขั้นตอนที่ 5: Repeat (ทำซ้ำ)
เทรนด้วยตัวอย่างนับพัน/ล้าน
จนกว่าโมเดลจะมีความแม่นยำที่ดี
ประเภทของสถาปัตยกรรม Deep Learning
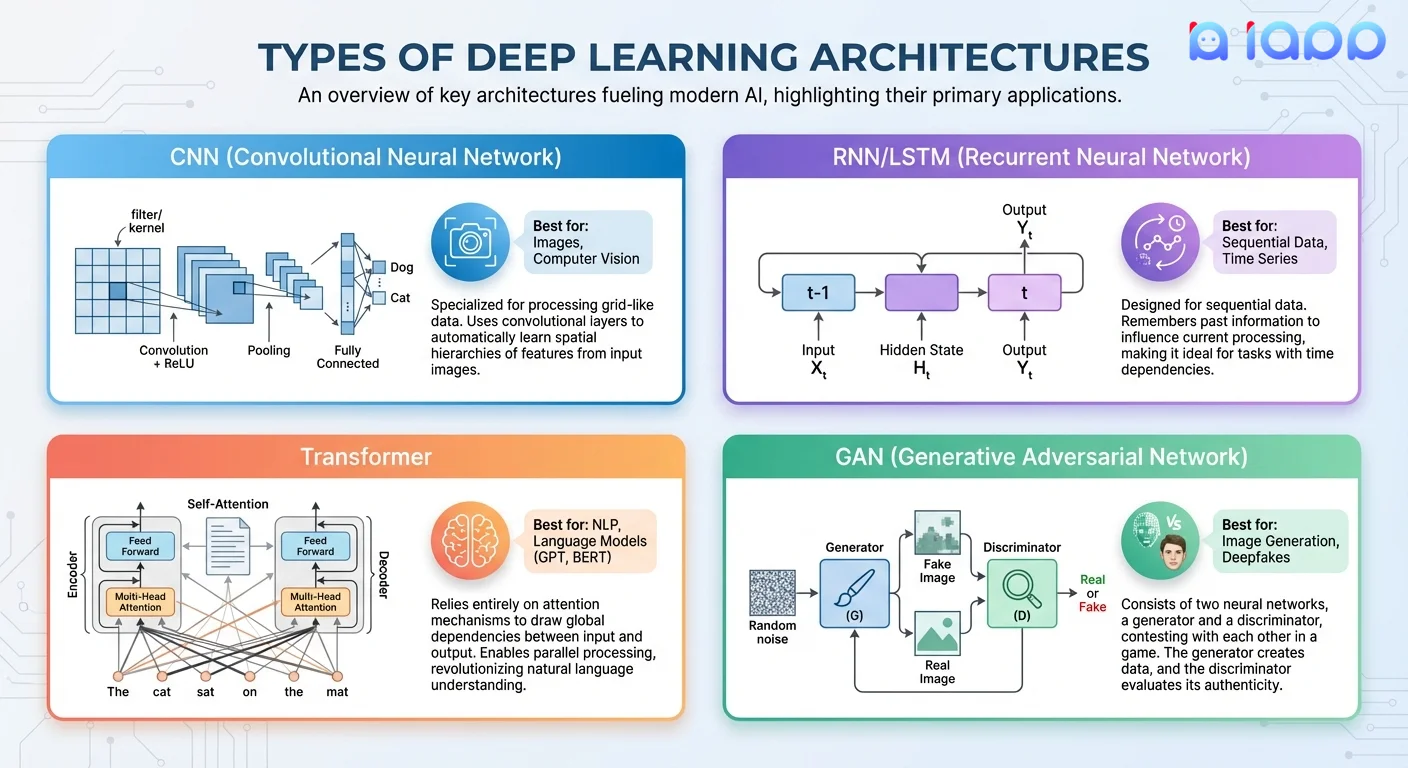
1. Convolutional Neural Networks (CNN)
เหมาะสำหรับ: รูปภาพ วิดีโอ งาน Computer Vision
ทำงานอย่างไร:
- ใช้ convolutional filters ตรวจจับรูปแบบ
- เรียนรู้ขอบ → พื้นผิว → รูปทรง → วัตถุ
- รักษาความสัมพันธ์เชิงพื้นที่ในข้อมูล
การประยุกต์ใช้:
- การจำแนกรูปภาพ (แมว vs สุนัข)
- การตรวจจับวัตถุ (หาใบหน้าในรูป)
- OCR (อ่านข้อความจากรูป)
- การวิเคราะห์ภาพทางการแพทย์
ใช้ใน: Thai OCR, Face Recognition ของ iApp
2. Recurrent Neural Networks (RNN/LSTM)
เหมาะสำหรับ: ข้อมูลลำดับ อนุกรมเวลา เสียงพูด
ทำงานอย่างไร:
- มี "ความจำ" ของอินพุตก่อนหน้า
- ประมวลผลลำดับทีละองค์ประกอบ
- LSTM แก้ปัญหา vanishing gradient
การประยุกต์ใช้:
- การรู้จำเสียงพูด
- การสร้างโมเดลภาษา
- การทำนายอนุกรมเวลา
- การสร้างเพลง
ใช้ใน: Speech-to-Text ของ iApp
3. Transformers
เหมาะสำหรับ: การประมวลผลภาษาธรรมชาติ LLMs สมัยใหม่
ทำงานอย่างไร:
- ใช้กลไก "attention" ให้น้ำหนักความสำคัญของอินพุตทั้งหมด
- ประมวลผลลำดับทั้งหมดพร้อมกัน (เร็วกว่า RNN)
- Self-attention จับความสัมพันธ์ระยะไกล
การประยุกต์ใช้:
- โมเดลภาษา (GPT, BERT, LLaMA)
- การแปลภาษาด้วยเครื่อง
- การสร้างข้อความ
- การตอบคำถาม
ใช้ใน: OpenThai Chinda, Translation API ของ iApp
4. Generative Adversarial Networks (GAN)
เหมาะสำหรับ: การสร้างเนื้อหาใหม่ การสังเคราะห์รูปภาพ
ทำงานอย่างไร:
- สองเครือข่ายแข่งขันกัน: Generator vs Discriminator
- Generator สร้างข้อมูลปลอม; Discriminator พยายามตรวจจับของปลอม
- การแข่งขันทำให้ทั้งสองดีขึ้นจนกว่า Generator จะสร้างผลลัพธ์ที่สมจริง
การประยุกต์ใช้:
- การสร้างรูปภาพ
- การถ่ายโอนสไตล์
- การเพิ่มข้อมูล
- Deepfakes
5. Autoencoders
เหมาะสำหรับ: การบีบอัด การตรวจจับความผิดปกติ การลดสัญญาณรบกวน
ทำงานอย่างไร:
- Encoder บีบอัดข้อมูลให้มีขนาดเล็กลง
- Decoder สร้างข้อมูลต้นฉบับจากรูปแบบที่บีบอัด
- บังคับให้เครือข่ายเรียนรู้คุณลักษณะที่สำคัญ
การประยุกต์ใช้:
- การลดมิติ
- การตรวจจับความผิดปกติ
- การลดสัญญาณรบกวนในรูปภาพ
- การเรียนรู้คุณลักษณะ
คำศัพท์ Deep Learning ที่สำคัญ (อธิบายศัพท์เทคนิค)
1. Neuron (โหนด)
คืออะไร: หน่วยคำนวณพื้นฐานในโครงข่ายประสาทเทียมที่รับอินพุต ใช้น้ำหนักและฟังก์ชัน จากนั้นส่งออกค่า
เปรียบเทียบง่ายๆ: เหมือนเซลล์สมองที่ทำงานเมื่อได้รับสัญญาณเพียงพอจากเซลล์ที่เชื่อมต่อ
สูตร: output = activation(sum(weights × inputs) + bias)
2. Activation Function (ฟังก์ชันกระตุ้น)
คืออะไร: ฟังก์ชันทางคณิตศาสตร์ที่กำหนดว่า neuron ควร "ทำงาน" หรือไม่และแรงแค่ไหน
ประเภทที่พบบ่อย:
- ReLU (Rectified Linear Unit):
max(0, x)— ง่าย เร็ว นิยมที่สุด - Sigmoid: บีบผลลัพธ์ให้อยู่ 0-1 — ดีสำหรับความน่าจะเป็น
- Softmax: ให้ผลลัพธ์เป็นการกระจายความน่าจะเป็น — ใช้สำหรับการจำแนก
- Tanh: บีบให้อยู่ -1 ถึง 1 — ดีกว่า sigmoid สำหรับ hidden layers
ทำไมสำคัญ: หากไม่มี activation functions ไม่ว่าจะมีกี่ชั้น เครือข่ายจะคำนวณได้แค่ฟังก์ชันเชิงเส้น Activations เพิ่มความไม่เชิงเส้น ทำให้เรียนรู้รูปแบบที่ซับซ้อนได้
3. Backpropagation (การส่งผ่านย้อนกลับ)
คืออะไร: อัลกอริทึมที่คำนวณว่าแต่ละ weight มีส่วนในความผิดพลาดของการทำนายอย่างไร จากนั้นปรับค่า weights เพื่อลดความผิดพลาดในอนาคต
เปรียบเทียบง่ายๆ: เหมือนการย้อนกลับไปดูสูตรอาหารว่าส่วนผสมไหนทำให้อาหารไม่อร่อย แล้วปรับปริมาณ
กระบวนการ:
- คำนวณความผิดพลาดที่ output
- ส่งความผิดพลาดย้อนกลับผ่านชั้นต่างๆ
- คำนวณ gradient (ทิศทางที่ต้องปรับ) สำหรับแต่ละ weight
- อัปเดต weights โดยใช้ gradient descent
4. Epoch, Batch, Iteration
Epoch: การผ่านข้อมูลเทรนนิ่งทั้งหมดหนึ่งรอบ
- การเทรนมักต้องใช้หลาย epochs (10-100+)
Batch: ส่วนย่อยของข้อมูลเทรนนิ่งที่ประมวลผลพร้อมกัน
- Batch size มักเป็น 32, 64, 128 หรือ 256 ตัวอย่าง
Iteration: การอัปเดต weights ของโมเดลหนึ่งครั้ง
- Iterations ต่อ epoch = ขนาดข้อมูล ÷ batch size
ตัวอย่าง: ตัวอย่างเทรนนิ่ง 10,000 ตัว, batch size 100
- 1 epoch = 100 iterations
- 50 epochs = 5,000 iterations
5. Overfitting vs Underfitting (ในบริบท Deep Learning)
Overfitting: เครือข่ายจำข้อมูลเทรนนิ่งแต่ล้มเหลวกับข้อมูลใหม่
- อาการ: Training accuracy สูง, validation accuracy ต่ำ
- วิธีแก้: Dropout, regularization, ข้อมูลเพิ่ม, data augmentation, early stopping
Underfitting: เครือข่ายง่ายเกินไปที่จะจับรูปแบบได้
- อาการ: ทั้ง training และ validation accuracy ต่ำ
- วิธีแก้: ชั้นเพิ่ม, neurons เพิ่ม, เทรนนานขึ้น, สถาปัตยกรรมที่ดีกว่า
Dropout: ��การ "ปิด" neurons แบบสุ่มระหว่างการเทรนเพื่อป้องกัน overfitting — เหมือนการฝึกทีมที่สมาชิกต่างกันขาดในแต่ละการฝึก บังคับให้ทุกคนต้องมีความสามารถ
ทำไม Deep Learning ถึงสำคัญ
1. การเรียนรู้คุณลักษณะอัตโนมัติ
ต่างจาก ML แบบดั้งเดิม Deep Learning ค้นพบคุณลักษณะที่เกี่ยวข้องด้วยตัวเอง:
- ไม่ต้องกำหนด feature ด้วยมือ
- หารูปแบบที่มนุษย์อาจพลาด
- ทำงานกับข้อมูลดิบที่ไม่มีโครงสร้าง
2. ควา��มแม่นยำที่ไม่เคยมีมาก่อน
Deep Learning ทำได้เท่ามนุษย์ (หรือดีกว่า) ใน:
- การจดจำรูปภาพ (ImageNet)
- การรู้จำเสียงพูด (ผู้ช่วยเสียง)
- การเล่นเกม (AlphaGo, หมากรุก)
- การเข้าใจภาษา (GPT-4)
3. จัดการข้อมูลที่ซับซ้อน
เก่งในการประมวลผล:
- รูปภาพและวิดีโอ
- ภาษาธรรมชาติ
- เสียงพูดและเสียง
- การผสมผสานหลายรูปแบบ
4. ขยายขนาดได้ตามข้อมูลและการประมวลผล
ข้อมูลมากขึ้น + พลังการประมวลผลมากขึ้น = ผลลัพธ์ดีขึ้น
- โมเดลใหญ่ขึ้นเรียนรู้รูปแบบที่ซับซ้อนมากขึ้น
- ประสิทธิภาพดีขึ้นเรื่อยๆ ตามขนาด
5. Transfer Learning
โมเดลที่เทรนไว้แล้วสามารถปรับแต่งสำหรับงานใหม่:
- ไม่ต้องเทรนจากศูนย์
- ต้องการข้อมูลน้อยลงสำหรับแอปพลิเคชันใหม่
- เวลาพัฒนาเร็วขึ้น
Deep Learning แก้ปัญหาอะไร?
| ปัญหา | วิธีดั้งเดิม | วิธี Deep Learning |
|---|---|---|
| การรู้จำรูปภาพ | Features ที่กำหนดด้วยมือ + classifier | CNN เรียนรู้ features อัตโนมัติ |
| การรู้จำเสียงพูด | Acoustic models + language models | Neural networks แบบ end-to-end |
| การแปลภาษาด้วยเครื่อง | Rule-based หรือ statistical MT | Neural MT ด้วย Transformers |
| การจดจำใบหน้า | การสกัด features ด้วยมือ | Deep CNNs พร้อม embeddings |
| การสร้างข้อความ | Templates หรือ Markov chains | Large Language Models |
| การเล่นเกม | กลยุทธ์ที่ hard-coded | Reinforcement learning + neural nets |
Deep Learning ในประเทศไทย: การประยุกต์ใช้จริง
1. Thai Document OCR
ใช้ Thai OCR APIs:
- Deep CNNs ที่เทรนด้วยเอกสารไทยนับล้านฉบับ
- จดจำอั�กษรไทย ลายมือ และฟอนต์หลากหลาย
- สกัดข้อมูลแบบมีโครงสร้างจากบัตรประชาชน พาสปอร์ต ใบเสร็จ
- ขับเคลื่อน eKYC สำหรับธนาคารและ fintech ไทย
2. Thai Speech Recognition
ใช้ Speech-to-Text:
- Deep neural networks ที่เทรนด้วยข้อมูลเสียงภาษาไทย
- จัดการวรรณยุกต์ สำเนียงท้องถิ่น และภาษาถิ่น
- ความสามารถถอดเสียงแบบเรียลไทม์
- ขับเคลื่อนผู้ช่วยเสียงและระบบ call center อัตโนมัติ
3. Thai Language Understanding
ใช้ DeepSeek V4:
- โมเดลภาษาขนาดใหญ่แบบ Transformer
- เทรนด้วยคลังข้อความภาษาไทย
- เข้าใจบริบท ไวยากรณ์ และความละเอียดอ่อน
- ขับเคลื่อน chatbots, การสร้างเนื้อหา และการวิ�เคราะห์ข้อความ
4. Face Recognition & Verification
ใช้ Face Recognition:
- Deep CNNs สำหรับการตรวจจับและสร้าง embedding ใบหน้า
- Liveness detection ป้องกันการปลอมแปลง
- ทำงานได้ในมุม แสง และอายุที่แตกต่างกัน
- ความปลอดภัยระดับธนาคารสำหรับการยืนยันตัวตน
5. Neural Machine Translation
ใช้ Translation API:
- โมเดล Transformer สำหรับการแปลไทย-อังกฤษ-จีน
- รักษาบริบทและความหมาย
- จัดการสำนวนและการแสดงออกทางวัฒนธรรม
- ความสามารถแปลแบบเรียลไทม์
สร้างแอปพลิเคชันด้วย Deep Learning APIs ของ iApp
iApp Technology ให้บริการโมเดล Deep Learning ที่เทรนไว้แล้วในรูปแบบ APIs ที่ใช้งานง่าย:
บริการ Deep Learning ที่มี
| งาน Deep Learning | ผลิตภัณฑ์ iApp | สถาปัตยกรรม |
|---|---|---|
| Thai OCR | Thai OCR APIs | CNN + Transformer |
| Speech Recognition | Speech-to-Text | Deep Neural Network |
| Face Recognition | Face Recognition | Deep CNN |
| Thai Language | OpenThai Chinda | Transformer (LLM) |
| Translation | Translation API | Neural MT |
| Text-to-Speech | Text-to-Speech | Neural TTS |
ตัวอย่าง: ใช้ Deep Learning สำหรับ Thai OCR
import requests
def extract_text_with_deep_learning(image_path):
"""
ใช้ Deep Learning OCR ของ iApp สกัดข้อความจากเอกสารไทย
"""
with open(image_path, 'rb') as f:
response = requests.post(
'https://api.iapp.co.th/thai-national-id-ocr/v3',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': f}
)
result = response.json()
# โมเดล Deep Learning สกัดข้อมูลแบบมีโครงสร้างแล้ว
return {
'name_th': result.get('name_th'),
'name_en': result.get('name_en'),
'id_number': result.get('id_number'),
'date_of_birth': result.get('date_of_birth'),
'confidence': result.get('confidence')
}
# ตัวอย่างการใช้งาน
data = extract_text_with_deep_learning('thai_id_card.jpg')
print(f"ชื่อที่สกัดได้: {data['name_th']}")
print(f"ความมั่นใจ: {data['confidence']}")
ตัวอย่าง: Deep Learning สำหรับการสร้างข้อความภาษาไทย
import requests
def generate_with_thai_llm(prompt):
"""
ใช้ OpenThai Chinda (แบบ Transformer) สำหรับการสร้างข้อความ
"""
response = requests.post(
'https://api.iapp.co.th/v3/llm/deepseek-v4/chat/completions',
headers={
'apikey': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
json={
'model': 'deepseek-v4-flash',
'messages': [{
'role': 'user',
'content': prompt
}],
'max_tokens': 512
}
)
return response.json()['choices'][0]['message']['content']
# ตัวอย่างการใช้งาน
result = generate_with_thai_llm("อธิบ��ายว่า Deep Learning คืออะไร ใน 3 ประโยค")
print(result)
เริ่มต้นกับ Deep Learning
สำหรับผู้ใช้ธุรกิจ
คุณไม่จำเป็นต้องสร้างโมเดล Deep Learning ด้วยตัวเอง! ใช้โมเดลที่เทรนไว้แล้วผ่าน APIs:
- ระบุ use case ของคุณ: การประมวลผลเอกสาร? เสียง? การจดจำใบหน้า? การสร้างข้อความ?
- เลือก API ที่เหมาะสม: ดูรายการ API ของ iApp
- รับ API key ของคุณ: สมัครฟรี
- เชื่อมต่อ: เรียก REST API ง่ายๆ จากภาษาใดก็ได้
- ขยาย: จ่ายเฉพาะที่ใช้
สำหรับนักพัฒนาและ Data Scientists
ต้องการเข้าใจ Deep Learning ลึกขึ้น?
- เรียนพื้นฐาน: เริ่มจาก neural networks พื้นฐาน จากนั้น CNNs, RNNs, Transformers
- ฝึกกับ frameworks: TensorFlow, PyTorch, Keras
- เรียนคอร์ส: Fast.ai, Coursera Deep Learning Specialization, Stanford CS231n
- สร้างโปรเจค: ประยุกต์ใช้ Deep Learning กับปัญหาจริง
- ใช้โมเดลที่เทรนไว้แล้ว: Hugging Face, TensorFlow Hub, PyTorch Hub
แหล่งข้อมูล
- รับการเข้าถึง API: จัดการ API Key
- ทดลอง Thai OCR: สาธิต Document OCR
- ทดลอง Speech AI: สาธิต Speech-to-Text
- ทดลอง Thai LLM: สาธิต Chinda
- เข้าร่วมชุมชน: Discord
อนาคตของ Deep Learning
เทรนด์ที่ต้องจับตา
- Foundation Models: โมเดลที่เทรนไว้ขนาดใหญ่ (GPT-4, Claude, Gemini) เป็นฐานสำหรับหลายแอปพลิเคชัน
- Multimodal Models: โมเดลเดียวเข้าใจข้อความ รูปภาพ เสียง วิดีโอ ร่วมกัน
- Efficient AI: โมเดลเล็กลง เร็วขึ้น สำหรับอุปกรณ์ edge (มือถือ, IoT)
- AI Agents: Deep Learning ขับเคลื่อนระบบตัดสินใจอัตโนมัติ
- Responsible AI: เน้นความยุติธรรม ความสามารถอธิบายได้ และความปลอดภัย
ทำไมธุรกิจไทยควรใช้ Deep Learning ตอนนี้
- ความได้เปรียบในการแข่งขัน: การ automation และ insights ที่ขับเคลื่อนด้วย AI
- ลดต้นทุน: ทำงานซ้ำๆ อัตโนมัติ
- ประสบการณ์ลูกค้าที่ดีขึ้น: การ personalization และบริการที่เร็วขึ้น
- นวัตกรรม: ผลิตภัณฑ์และบริการใหม่ที่ Deep Learning เปิดให้เป็นไปได้
- มาตรฐานโลก: โมเดลเฉพาะภาษาไทยที่ทัดเทียมคุณภาพระดับนานาชาติ
สรุป
Deep Learning คือเทคโนโลยีก้าวกระโดดที่ขับเคลื่�อน AI สมัยใหม่ — ตั้งแต่การจดจำใบหน้าไปจนถึงการเข้าใจภาษาและการสร้างเนื้อหา ด้วยการใช้โครงข่ายประสาทเทียมหลายชั้น Deep Learning สามารถเรียนรู้รูปแบบที่ซับซ้อนจากข้อมูลดิบโดยอัตโนมัติ ทำได้ดีกว่ามนุษย์ในหลายงาน
ข่าวดีคือ คุณไม่จำเป็นต้องมีปริญญาเอกหรือโครงสร้างพื้นฐานราคาแพงเพื่อได้ประโยชน์จาก Deep Learning iApp Technology ให้บริการโมเดล Deep Learning ที่เทรนไว้แล้วในรูปแบบ APIs ที่ง่าย — Thai OCR สำหรับการประมวลผลเอกสาร, Speech-to-Text สำหรับเสียง, Face Recognition สำหรับการยืนยันตัวตน และ OpenThai Chinda สำหรับการเข้าใจภาษาไทย
พร้อมที่จะเพิ่ม Deep Learning ในแอปพลิเคชันของคุณ? สมัครฟรี และเริ่มใช้ AI-powered APIs ของเราวันนี้!
มีคำถาม? เข้าร่วม Discord Community หรืออีเมลหาเราที่ support@iapp.co.th
iApp Technology Co., Ltd. บริษัท AI ชั้นนำของประเทศไทย