什么是深度学习?初学者完整指南

当您的手机在瞬间识别您的脸、当Google翻译几乎完美地将泰语翻译成英语、或当ChatGPT生成类人回复时——这就是深度学习在工作。它是过去十年几乎所有重大AI突破背后的技术,正在改变计算机能做的事情。
什么是深度学习?
深度学习(Deep Learning) 是机器学习的一个子集,使用多层人工神经网络从大量数据中学习。深度学习中的"深度"指的是这些神经网络的层数深度——从简单的3层网络到具有数百层的大型模型。
可以这样理解:
- 传统编程: 人类编写明确的规则
- 机器学习: 计算机从数据中学习模式
- 深度学习: 计算机通过多层抽象学习复杂模式
深度学习的核心特点:
- 学习 从原始数据中获得层次化表示
- 自动发现 特征(无需手动特征工程)
- 处理 非结构化数据,如图像、音频和文本
- 扩展 随着更多数据和计算能力而提升
简单类比
想象教孩子识别猫:
- 传统编程: 列出每条规则(有毛、四条腿、尖耳朵、胡须...)
- 机器学习: 展示示例,让孩子找到��模式
- 深度学习: 孩子首先学习边缘 → 然后形状 → 然后身体部位 → 最后是整只猫
每一层都建立在前一层之上,学习越来越抽象的概念。
深度学习如何工作
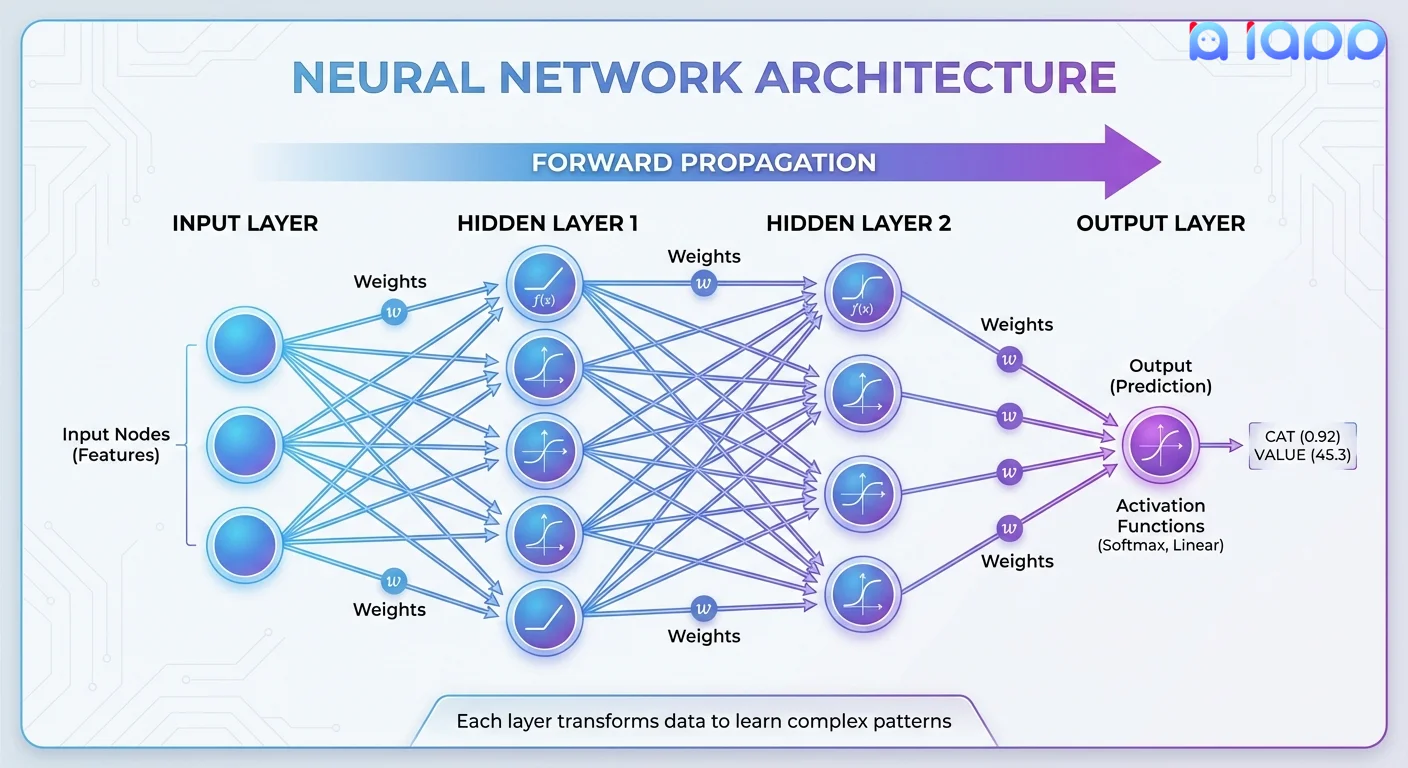
神经网络结构
1. 输入层(Input Layer)
- 接收原始数据(像素、词语、数字)
- 每个节点代表一个特征或输入值
2. 隐藏层("深度"部分)
- 多层转换数据
- 每层学习不同级别的抽象
- 更多层 = 更深的网络 = 更复杂的模式
3. 输出层(Output Layer)
- 产生最终预测
- 可以是类别标签、概率或生成的内容
学习过程
步骤1:前向传播(Forward Propagation)
数据从 input → 通过 hidden layers → 到 output
每个神经元应用:output = activation(weights × inputs + bias)
步骤2:计算损失(Calculate Loss)
将预测与实际答案比较
损失 = 预测的错误程度
步骤3:反向传播(Backpropagation)
计算每个权重对错误的贡献
将错误向后传播通过网络
步骤4:更新权重(Update Weights)
调整权重以减少错误
使用优化算法如SGD或Adam
步骤5:重复(Repeat)
在数千/数百万个示例上训练
直到模型达到良好的准确率
深度学习架构类型
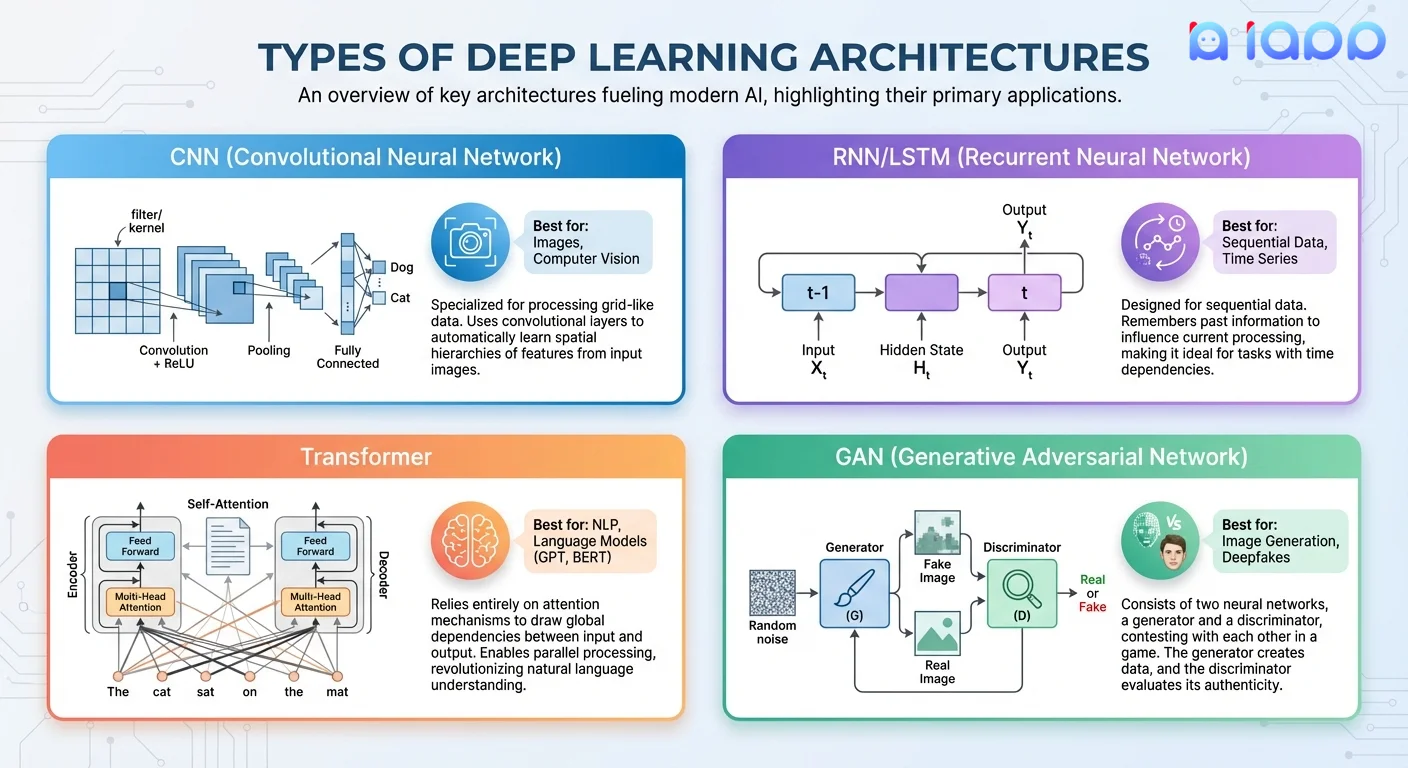
1. 卷积神经网络(CNN)
最适合: 图像、视频、计算机视觉任务
工作原理:
- 使用卷积滤波器检测模式
- 学习边缘 → 纹理 → 形状 → 物体
- 保持数据中的空间关系
应用:
- 图像分类(猫vs狗)
- 物体检测(在照片中找到人脸)
- OCR(从图像中读取文字)
- 医学图像分析
2. 循环神经网络(RNN/LSTM)
最适合: 序列数据、时间序列、语音
工作原理:
- 具有先前输入的"记忆"
- 逐个元素处理序列
- LSTM解决梯度消失问题
应用:
- 语音识别
- 语言建模
- 时间序列预测
- 音乐生成
用于: iApp的 语音转文字
3. Transformer
最适合: 自然语言处理、现代LLM
工作原理:
- 使用"注意力"机制对所有输入加权
- 并行处理整个序列(比RNN更快)
- 自注意力捕获长距离依赖
应用:
- 语言模型(GPT、BERT、LLaMA)
- 机器翻译
- 文本生成
- 问答系统
用于: iApp的 Chinda泰语LLM、翻译API
4. 生成对抗网络(GAN)
最适合: 生成新内容、图像合成
工作原理:
- 两个网络竞争:生成器vs判别器
- 生成器创建假数据;判�别器尝试检测假货
- 竞争使两者都改进,直到生成器创建逼真的输出
应用:
- 图像生成
- 风格迁移
- 数据增强
- 深度伪造
5. 自编码器(Autoencoder)
最适合: 压缩、异常检测、去噪
工作原理:
- 编码器将数据压缩为更小的表示
- 解码器从压缩形式重建原始数据
- 迫使网络学习本质特征
应用:
- 降维
- 异常检测
- 图像去噪
- 特征学习
深度学习关键术语解释(术语解析)
1. 神经元(节点)
是什么: 神经网络中的基本计算单元,接收输入,应用权重和函数,然后输出一个值。
简单类比: 就像脑细胞在从连接的细胞接收到足够信号时触发。
公式: output = activation(sum(weights × inputs) + bias)
2. 激活函数
是什么: 决定神经元是否应该"触发"以及触发强度的数学函数。
常见类型:
- ReLU(修正线性单元):
max(0, x)— 简单、快速、最流行 - Sigmoid: 将输出压缩到0-1 — 适合概率
- Softmax: 输出概率分布 — 用于分类
- Tanh: 压缩到-1到1 — 比sigmoid更适合隐藏层
重要性: 没有激活函数,无论有多少层,网络只能计算线性函数。激活函数添加非线性,使学习复杂模式成为可能。
3. 反向传播
是什么: 计算每个权重对预测错误贡献多少的算法,然后更新权重以减少未来错误。
简单类比: 就像追溯菜谱,找出是哪种配料导致菜品味道不对,然后调整用量。
过程:
- 在输出处计算错误
- 将错误向后传播通过各层
- 为每个权重计算梯度(调整方向)
- 使用梯度下降更新权重
4. Epoch、Batch、Iteration
Epoch: 完整遍历一次整个训练数据集
- 训练通常需要多个epochs(10-100+)
Batch: 一起处理的训练��数据子集
- Batch大小通常为32、64、128或256个样本
Iteration: 一次模型权重更新
- 每个epoch的iterations = 数据集大小 ÷ batch大小
示例: 10,000个训练样本,batch大小100
- 1 epoch = 100 iterations
- 50 epochs = 5,000 iterations
5. 过拟合vs欠拟合(深度学习背景)
过拟合: 网络记住训练数据但在新数据上失败
- 迹象: 训练准确率高,验证准确率低
- 解决方案: Dropout、正则化、更多数据、数据增强、早停
欠拟合: 网络太简单无法捕获模式
- 迹象: 训练和验证准确率都低
- 解决方案: 更多层、更多神经元、更长训练、更好的架构
Dropout: 在训练期间随机"关闭"神经元以防止过拟合——就像训练一个团队,每次练习不同成员缺席,迫使每个人都有能力。
为什么深度学习重要
1. 自动特征学习
与传统ML不同,深度学习自己发现相关特征:
- 无需手动特征工程
- 发现人类可能错过的模式
- 处理原始、非结构化数据
2. 前所未有的准确性
深度学习在以下方面达到人类水平(或更好)的表现:
- 图像识别(ImageNet)
- 语音识别(语音助手)
- 游戏(AlphaGo、国际象棋)
- 语言理解(GPT-4)
3. 处理复杂数据
擅长处理:
- 图像和视频
- 自然语言
- 语音和音频
- 多模态组合
4. 随数据和计算扩展
更多数据 + 更多计算能力 = 更好的结果
- 更大的模型学习更复杂的模式
- 性能随规模持续提升
5. 迁移学习
预训练模型可以针对新任务进行微调:
- 不需要从头开始训练
- 新应用需要更少数据
- 更快的开发时间
深度学习解决什么问题?
| 问题 | 传统方法 | 深度学习解决方案 |
|---|---|---|
| 图像识别 | 手工特征 + 分类器 | CNN自动学习特征 |
| 语音识别 | 声学模型 + 语言模型 | 端到端神经网络 |
| 机器翻译 | 基于规则或统计MT | 使用Transformer的神经MT |
| 人脸识别 | 手动特征提取 | 深度CNN与嵌入 |
| 文本生成 | 模板或马尔可夫链 | 大型语言模型 |
| 游戏 | 硬编码策略 | 强化学习 + 神经网络 |
泰国的深度学习:实际应用
1. 泰语文档OCR
使用 泰语OCR API:
- 在数百万泰语文档上训练的深度CNN
- 识别泰语文字、手写和各种字体
- 从身份证、护照、收据中提取结构化数据
- 为泰国银行和金融科技提供eKYC支持
2. 泰语语音识别
使用 语音转文字:
- 在泰语语音数据上训练的深度神经网络
- 处理声调、地方口音和方言
- 实时转录能力
- 为语音助手和呼叫中心自动化提供支持
3. 泰语语言理解
使用 DeepSeek V4:
- 基于Transformer的大型语言模型
- 在泰语文本语料库上训练
- 理解上下文、语法和细微差别
- 为聊天机器人、内容生成和文本分析提供支持
4. 人脸识别与验证
使用 人脸识别:
- 用于人脸检测和嵌入的深度CNN
- 活体检测防止欺骗
- 在不同角度、光线和年龄下工作
- 银行级安全性用于身份验证
5. 神经机器翻译
使用 翻译API:
- 用于泰语-英语-中文翻译的Transformer模型
- 保持上下文和含义
- 处理习语和文化表达
- 实时翻译能力
使用iApp的深度学习API构建
iApp Technology提供预训练的深度学习模型作为易用的API:
可用的深度学习服务
| 深度学习任务 | iApp产品 | 架构 |
|---|---|---|
| 泰语OCR | 泰语OCR API | CNN + Transformer |
| 语音识别 | 语音转文字 | 深度神经网络 |
| 人脸识别 | 人脸识别 | 深度CNN |
| 泰语语言 | Chinda泰语LLM | Transformer (LLM) |
| 翻译 | 翻译API | 神经MT |
| 文字转语音 | 文字转语音 | 神经TTS |
示例:使用深度学习进行泰语OCR
import requests
def extract_text_with_deep_learning(image_path):
"""
使用iApp的深度学习OCR从泰语文档中提取文本
"""
with open(image_path, 'rb') as f:
response = requests.post(
'https://api.iapp.co.th/thai-national-id-ocr/v3',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': f}
)
result = response.json()
# 深度学习模型已提取结构化数据
return {
'name_th': result.get('name_th'),
'name_en': result.get('name_en'),
'id_number': result.get('id_number'),
'date_of_birth': result.get('date_of_birth'),
'confidence': result.get('confidence')
}
# 使用示例
data = extract_text_with_deep_learning('thai_id_card.jpg')
print(f"提取的姓名: {data['name_th']}")
print(f"置信度: {data['confidence']}")
示例:深度学习用于泰语文本生成
import requests
def generate_with_thai_llm(prompt):
"""
使用Chinda泰语LLM(基于Transformer)进行文本生成
"""
response = requests.post(
'https://api.iapp.co.th/v3/llm/deepseek-v4/chat/completions',
headers={
'apikey': 'YOUR_API_KEY',
'Content-Type': 'application/json'
},
json={
'model': 'deepseek-v4-flash',
'messages': [{
'role': 'user',
'content': prompt
}],
'max_tokens': 512
}
)
return response.json()['choices'][0]['message']['content']
# 使用示例
result = generate_with_thai_llm("用3句话解释什么是深度学习")
print(result)
开始深度学习
面向商业用户
您不需要从头构建深度学习模型!通过API使用预训练模型:
- 确定您的用例: 文档处理�?语音?人脸识别?文本生成?
- 选择合适的API: 浏览iApp的API目录
- 获取API密钥: 免费注册
- 集成: 从任何语言进行简单的REST API调用
- 扩展: 按使用量付费
面向开发者和数据科学家
想更深入了解深度学习?
- 学习基础: 从基本神经网络开始,然后CNN、RNN、Transformer
- 使用框架练习: TensorFlow、PyTorch、Keras
- 参加课程: Fast.ai、Coursera深度学习专项、Stanford CS231n
- 构建项目: 将深度学习应用于实际问题
- 使用预训练模型: Hugging Face、TensorFlow Hub、PyTorch Hub
资源
深度学习的未来
值得关注的趋势
- 基础模型: 大型预训练模型(GPT-4、Claude、Gemini)作为多个应用的基础
- 多模态模型: 单一模型同时理解文本、图像、音频、视频
- 高效AI: 更小、更快的模型用于边缘设备(移动设备、物联网)
- AI代理: 深度学习驱动自主决策系统
- 负责任的AI: 关注公平性、可解释性和安全性
为什么泰国企业应该现在利用深度学习
- 竞争优势: AI驱动的自动化和洞察
- 降低成本: 自动化重复性工作
- 更好的客户体验: 个性化和更快的服务
- 创新: 深度学习实现的新产品和服务
- 国际标准: 泰语特定模型达到国际质量水平
结论
深度学习是推��动现代AI的突破性技术——从识别人脸到理解语言再到生成内容。通过使用多层神经网络,深度学习可以自动从原始数据中学习复杂模式,在许多任务中实现超人表现。
好消息是,您不需要博士学位或昂贵的基础设施就能从深度学习中受益。iApp Technology提供预训练的深度学习模型作为简单的API——泰语OCR用于文档处理,语音转文字用于语音,人脸识别用于身份验证,Chinda泰语LLM用于泰语理解。
准备好将深度学习添加到您的应用程序了吗? 免费注册,今天就开始使用我们的AI驱动API!
有问题? 加入我们的 Discord社区 或发送邮件至 support@iapp.co.th
iApp Technology Co., Ltd. 泰国领先的AI技术公司