什么是多模态 AI?初学者完整指南

人类自然地通过多种感官理解世界——我们同时看到图像、听到声音、阅读文字和观看视频。但直到最近,AI 系统还只能一次处理一种类型的数据。欢迎来到**多模态 AI(Multimodal AI)**的世界——能够像人类一样同时理解和处理多种数据类型的人工智能。
什么是多模态 AI?
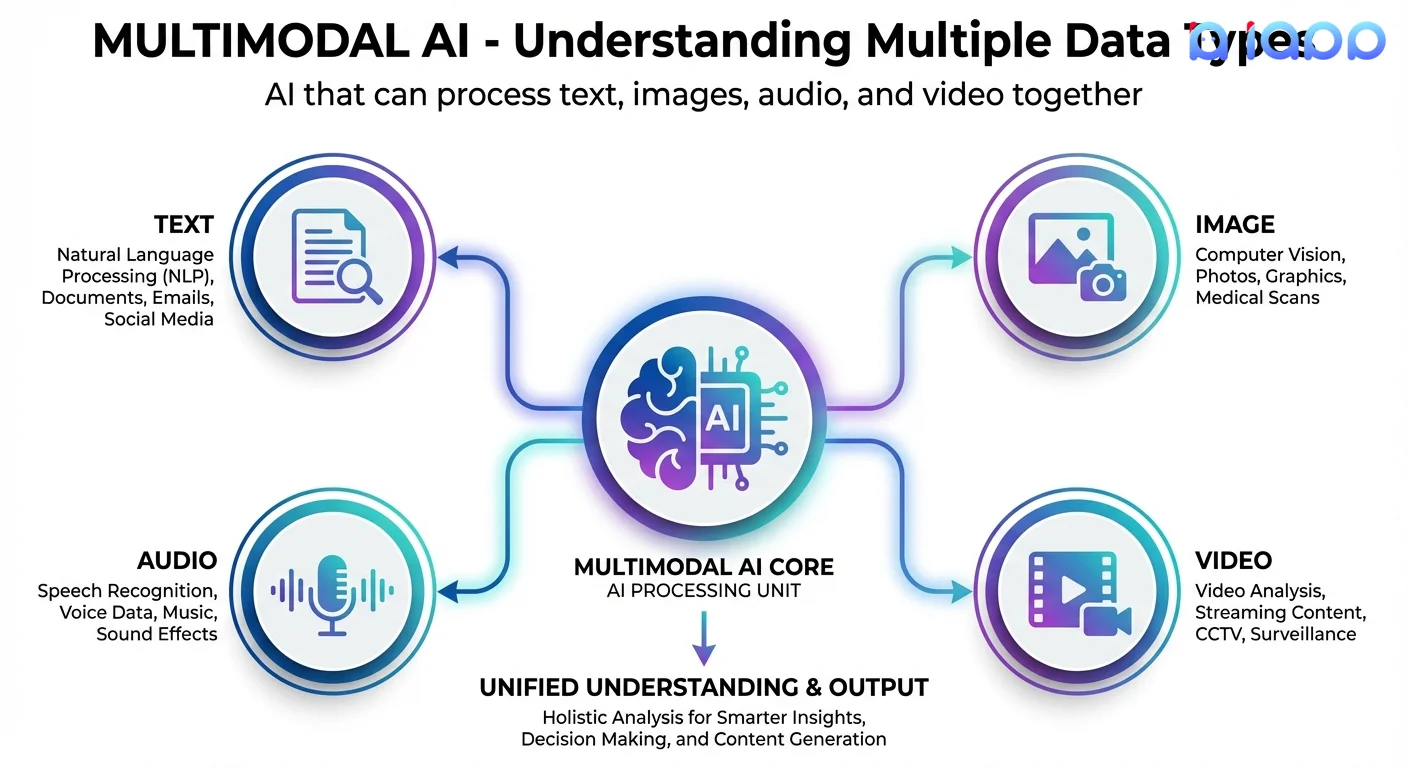
多模态 AI 指的是能够处理、理解和生成多种数据类型(称为"模态")的人工智能系统,例如:
- 文本 - 书面语言、文档、聊天消息
- 图像 - 照片、图表、图形、扫描文档
- 音频 - 语音、音乐、声音效果
- 视频 - 有声或无声的动态影像
关键的创新是多模态 AI 不仅分别处理这些数据——它还能理解它们之间的关系。例如,它可以查看图像并描述其中的内容,或者听取语音并准确转录。
简单示例
传统 AI(单一模态):
- 文本 AI:可以读写文字,但无法"看到"图像
- 图像 AI:可以识别照片中的物体,但无法用语言描述
- 音频 AI:可以转录语音,但无法理解图像
多模态 AI:
- 你给它看一张泰国身份证图片,它能读取所有文字、提取照片、验证文档类型,并输出结构化数据
- 你问"这张图片里有什么?"它用自然语言描述场景
- 你给它音频+视频,它同时从两者中理解上下文
多模态 AI 的类型
1. 视觉语言模型(VLMs)
结合图像理解和文本处理的 AI。
- 输入: 图像 + 文本提示
- 输出: 文字描述、答案、分析
- 示例: GPT-4V、Gemini、Claude Vision
- 应用场景: 图像描述、视觉问答、文档理解
2. 语音转文字 / 文字转语音
连接音频和文本模态的 AI。
- 语音转文字(STT): 将口语转换为书面文字
- 文字转语音(TTS): 将书面文字转换为自然语音
- 应用场景: 语音助手、转录、有声书生成
3. 文档 AI / OCR 系统
从文档图像中提取信息的 AI。
- 输入: 扫描文档、文字照片
- 输出: 结构化文本数据、表单字段
- 应用场景: 身份验证、发票处理、合同分析
4. 音视频模型
同时处理声音和视频的 AI。
- 输入: 带音轨的视频
- 输出: 转录、摘要、内容分析
- 应用场景: 视频搜索、内容审核、会议摘要
5. 任意到任意模型
最先进的多模态 AI,可以输入和输出任意组合。
- 输入: 任何模态(文本、图像、音频、视频)
- 输出: 任何模态
- 示例: GPT-4o、Gemini Ultra
- 应用场景: 创意工具、通用助手
关键 AI 术语解释(术语解读)
1. 模态(Modality)
定义: AI 可以处理的数据类型或形式。
简单类比: 把模态想象成不同的"感官"。就像人类有视觉、听觉、触觉、味觉和嗅觉,AI 可以有文本处理、图像识别、音频分析等。
常见模态: 文本、图像、音频、视频、传感器数据、3D 模型
2. 嵌入(Embedding)
定义: 将任何类型的数据(文本、图像、音频)转换为 AI 可以理解和比较的数字的方法。
简单类比: 就像把不同的语言翻译成一种通用语言。一旦所有东西都在同一种"数字语言"中,AI 就可以找到照片和其描述之间的关系。
重要性: 嵌入使多模态 AI 能够将"一张猫的照片"与文字"一只毛茸茸的猫坐在沙发上"联系起来。
3. 融合(Fusion)
定义: 结合来自多个模态的信息以做出更好预测的技术。
简单类比: 就像你结合所见和所闻来理解一部电影——单独一个都讲不完整个故事。
类型:
- 早期融合: 先合并��原始数据,然后处理
- 后期融合: 分别处理每个模态,然后合并结果
- 跨模态注意力: 让每个模态在处理过程中相互通知
4. 零样本/少样本学习
定义: AI 在没有专门训练的情况下处理新任务的能力。
简单类比: 就像一个英语说得好的人可以从上下文理解一个新的俚语,而不需要被教其定义。
多模态语境: 视觉语言模型可以回答关于从未见过的图像的问题,利用其一般理解。
5. OCR(光学字符识别)
定义: 将文字图像转换为机器可读文本的技术。
简单类比: 就像人类从照片中读取文字然后打出来,但由 AI 自动完成。
现代 OCR: 超越简单的字符识别——可以理解文档结构、表格、手写体和包括泰语在内的多种语言。
为什么多模态 AI 很重要
1. 更自然的交互
人类不只用一种方式交流。我们分享照片、语音消息、视频和文字。多模态 AI 让机器以我们自然交流的方式理解我们。
2. 更高的准确性
通过使用多个信息来源,多模态 AI 可以做出更准确的决策。一个既能看又能读文档的系统比只能做一件事的系统更可靠。
3. 复杂任务的自动化
许多现实世界的任务需要理解多种数据类型:
- 客户服务:文字聊天 + 语音通话 + 图片上传
- 文档处理:扫描图像 + 打印文字 + 手写笔记
- 质量控制:视觉检查 + 传感器读数 + 规格说明
4. 无障碍
多模态 AI 能够实现:
- 为视障人士提供文字转语音
- 为听障人士提供语音转文字
- 为屏幕阅读器提供图像描述
多模态 AI 解决什么问题?
| 问题 | 传统方法 | 多模态 AI 解决方案 |
|---|---|---|
| 身份验证 | 人工审核文档 | OCR + 人脸匹配 + 活体检测 |
| 客户支持 | 分别处理文字/语音/图像 | 统一理解所有输入 |
| 文档处理 | 手动数据录入 | 从任何文档自动提取 |
| 内容审核 | 分别检查图像/文字/视频 | 整体内容理解 |
| 医疗诊断 | 单模态分析 | 结合影像 + 病历 + 笔记 |
| 无障碍 | 有限选项 | 模态之间的通用转换 |
多模态 AI 如何工作
架构
-
编码器(每个模态一个)
- 文本编码器:将文本转换为数字表示
- 图像编码器:将图像转换为特征向量
- 音频编码器:将音频转换为频谱特征
-
融合层
- 合并编码后的表示
- 学习模态之间的关系
- 创建统一的理解
-
解码器/输出头
- 生成适当的输出
- 可以是文本、分类、结构化数据等
示例流程:泰国身份证处理
输入:泰国国民身份证照片
步骤 1:图像编码器
→ 检测文档边界
→ 识别卡片类型(泰国身份证)
→ 定位文字区域和照片
步骤 2:OCR 处理
→ 从每个区域提取泰语文字
→ 处理泰语脚本的细微差别
→ 读取打印和机打文字
步骤 3:人脸处理
→ 从身份证照片提取人脸
→ 创建人脸嵌入
→ 准备验证
步骤 4:融合与验证
→ 合并所有提取的数据
→ 验证字段格式
→ 交叉检查一致性
输出:包含所有字段的结构化 JSON
{
"name_th": "สมชาย ใจดี",
"name_en": "Somchai Jaidee",
"id_number": "1-1234-56789-01-2",
"birth_date": "1990-01-15",
"face_embedding": [...],
"confidence": 0.98
}
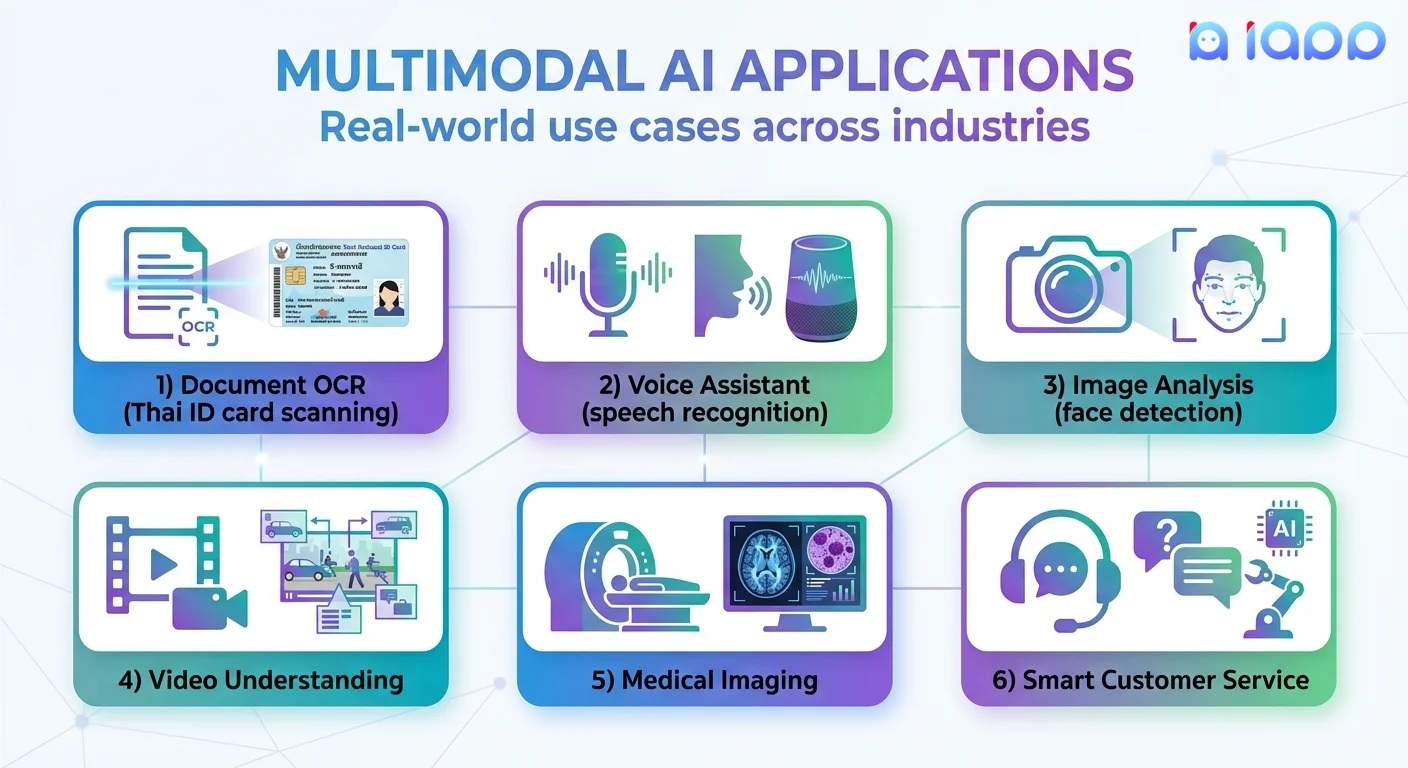
多模态 AI 在泰国的实际应用
1. 泰语文档 OCR
- 扫描泰国身份证、护照、驾照
- 准确提取泰语和英语文字
- 处理各种文档状况和角度
- 返回结构化数据便于集成
2. 人脸验证与 eKYC
结合 Face Recognition 与文档 AI:
- 将身份证人脸与自拍照匹配
- Liveness Detection 防止照片欺骗
- 几秒钟内完成 eKYC 流程
- 银行级安全标准
3. 泰语语音识别
- 高准确度将泰语语音转换为文字
- 处理各种泰语方言和口音
- 呼叫中心实时转录
- 会议转录和语音命令
4. 泰语文字转语音
- 自然流畅的泰语语音合成
- 多种声音选项(男/女)
- IVR 系统和语音助手
- 有声书和内容旁白
5. 多语言翻译
使用 Translation API:
- 在泰语、英语、中文、日语之间翻译
- 结合语音实现实时口译
- 保留格式的文档翻译
使用 iApp 的多模态 AI 构建
iApp Technology 为泰国企业提供全面的多模态 AI API:
可用组件
| 模态 | iApp 产品 | 功能 |
|---|---|---|
| 图像 → 文字 | Thai OCR APIs | 身份证、文档、收据 |
| 图像 → 数据 | Face Recognition | 人脸检测、匹配、活体 |
| 音频 → 文字 | Speech-to-Text | 泰语语音转录 |
| 文字 → 音频 | Text-to-Speech | 自然泰语语音合成 |
| 文字 → 文字 | Translation | 多语言翻译 |
| 文字 → 文字 | OpenThai Chinda | 泰语语言理解 |
示例:完整 eKYC 流程
import requests
def complete_ekyc_verification(id_card_image, selfie_image):
"""
使用多模态 AI 完成 eKYC:
1. OCR 提取身份证数据(图像 → 文字)
2. 从身份证提取人脸(图像 → 嵌入)
3. 自拍人脸提取(图像 → 嵌入)
4. 人脸比对(嵌入 → 匹配分数)
5. 活体检测(视频 → 布尔值)
"""
# 步骤 1:从身份证提取数据
ocr_response = requests.post(
'https://api.iapp.co.th/thai-national-id-ocr/v3',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': id_card_image}
)
id_data = ocr_response.json()
# 步骤 2:比对人脸
face_response = requests.post(
'https://api.iapp.co.th/face-recognition/v1/compare',
headers={'apikey': 'YOUR_API_KEY'},
files={
'image1': id_card_image,
'image2': selfie_image
}
)
face_match = face_response.json()
# 步骤 3:验证活体(防欺骗)
liveness_response = requests.post(
'https://api.iapp.co.th/liveness-detection/v1',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': selfie_image}
)
is_live = liveness_response.json()
return {
'id_data': id_data,
'face_match_score': face_match['similarity'],
'is_live_person': is_live['is_live'],
'verified': face_match['similarity'] > 0.8 and is_live['is_live']
}
开始使用多模态 AI
步骤 1:确定您的用例
常见起点:
- 文档处理: 从 Thai OCR 开始
- 语音应用: 从 Speech APIs 开始
- 身份验证: 从 eKYC 套件 开始
步骤 2:试用 API
用真实数据测试:
- 获取您的 API 密钥
- 在每个产品页面尝试交互式演示
- 查看响应格式
步骤 3:集成
- 从任何编程语言使用我们的 REST API
- 提供 Python、JavaScript 等 SDK
- 带示例的完整文档
资源�
多模态 AI 的未来
值得关注的趋势
- 实时处理: 更快的模型实现实时视频分析和同步翻译
- 设备端多模态: 在智能手机和边缘设备上运行复杂的多模态 AI
- 泰语专用模型: 更好的泰语语言和文档理解
- 生成式多模态: 从文本提示创建图像、音频和视频的 AI
- 通用模型: 无缝处理所有模态的单一模型
为什么泰国企业应该现在行动
- 竞争优势: 在竞争对手之��前自动化文档和语音工作流
- 客户体验: 提供无缝的多渠道支持
- 降低成本: 替代人工数据录入和验证
- 提高准确性: 减少文档处理中的人为错误
- 扩展运营: 处理更多业务量而无需成比例增加员工
结论
多模态 AI 代表着向更像人类理解世界的 AI 系统的根本转变——通过多种感官协同工作。从读取泰国身份证到转录电话到验证身份,多模态 AI 正在改变企业运营方式。
对于泰国企业,iApp Technology 提供完整的工具包:Thai OCR 用于文档、Face Recognition 用于身份、Speech-to-Text 用于语音、Thai LLM 用于语言理解——所有这些都针对泰语和泰国用例进行了优化。
准备好将多模态 AI 添加到您的应用程序了吗? 免费注册 并立即开始使用我们的泰语 OCR 或语音 API!
有问题吗? 加入我们的 Discord 社区 或发送邮件至 support@iapp.co.th。
iApp Technology Co., Ltd. 泰国领先的 AI 技术公司