What is Multimodal AI? A Complete Guide for Beginners

Humans naturally understand the world through multiple senses - we see images, hear sounds, read text, and watch videos simultaneously. But until recently, AI systems were limited to processing only one type of data at a time. Enter Multimodal AI - artificial intelligence that can understand and work with multiple types of data together, just like humans do.
What is Multimodal AI?
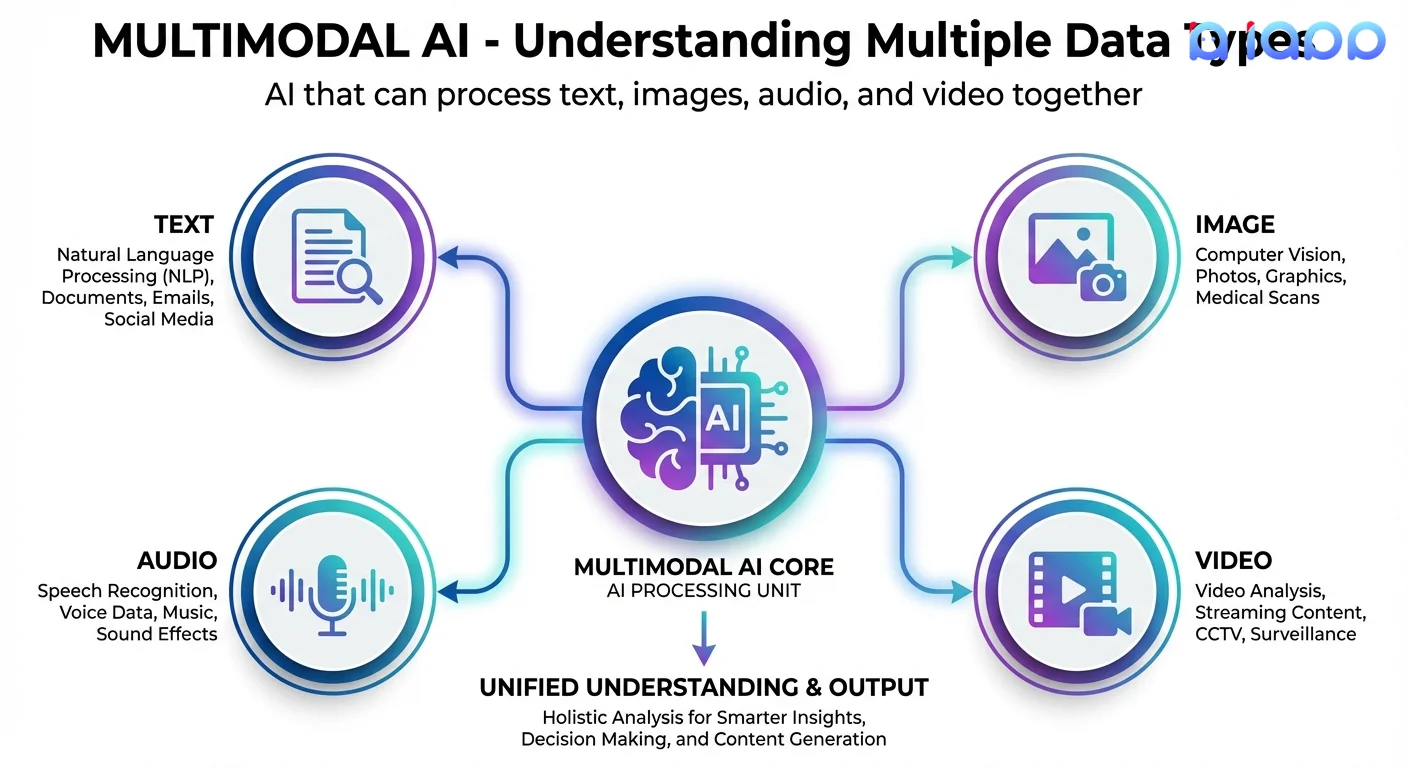
Multimodal AI refers to artificial intelligence systems that can process, understand, and generate multiple types of data (called "modalities") such as:
- Text - Written language, documents, chat messages
- Images - Photos, diagrams, charts, scanned documents
- Audio - Speech, music, sound effects
- Video - Moving images with or without sound
The key innovation is that multimodal AI doesn't just handle these separately - it understands the relationships between them. For example, it can look at an image and describe what's in it, or listen to speech and transcribe it accurately.
Simple Example
Traditional AI (Single Modality):
- Text AI: Can read and write text, but can't "see" images
- Image AI: Can recognize objects in photos, but can't describe them in words
- Audio AI: Can transcribe speech, but can't understand images
Multimodal AI:
- You show it a Thai ID card image, and it reads all the text, extracts the photo, verifies the document type, and outputs structured data
- You ask "What's in this image?" and it describes the scene in natural language
- You give it audio + video, and it understands context from both simultaneously
Types of Multimodal AI
1. Vision-Language Models (VLMs)
AI that combines image understanding with text processing.
- Input: Images + Text prompts
- Output: Text descriptions, answers, analysis
- Examples: GPT-4V, Gemini, Claude Vision
- Use cases: Image captioning, visual Q&A, document understanding
2. Speech-to-Text / Text-to-Speech
AI that bridges audio and text modalities.
- Speech-to-Text (STT): Converts spoken words to written text
- Text-to-Speech (TTS): Converts written text to natural-sounding speech
- Use cases: Voice assistants, transcription, audiobook generation
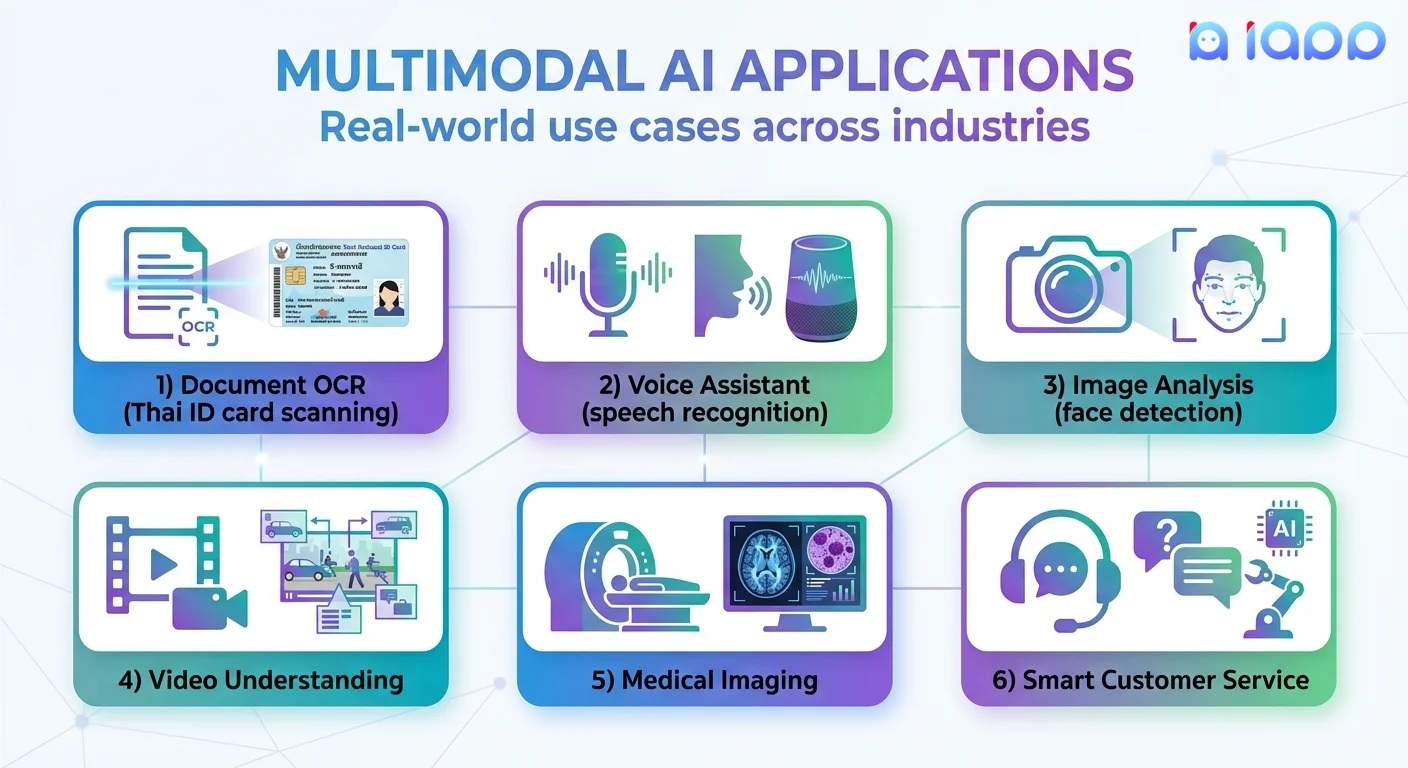
3. Document AI / OCR Systems
AI that extracts information from document images.
- Input: Scanned documents, photos of text
- Output: Structured text data, form fields
- Use cases: ID verification, invoice processing, contract analysis
4. Audio-Visual Models
AI that processes both sound and video together.
- Input: Video with audio track
- Output: Transcriptions, summaries, content analysis
- Use cases: Video search, content moderation, meeting summaries
5. Any-to-Any Models
The most advanced multimodal AI that can input and output any combination.
- Input: Any modality (text, image, audio, video)
- Output: Any modality
- Examples: GPT-4o, Gemini Ultra
- Use cases: Creative tools, universal assistants
Key AI Terms Explained (Jargon Buster)
1. Modality
What it is: A type or form of data that AI can process.
Simple analogy: Think of modalities as different "senses." Just as humans have sight, hearing, touch, taste, and smell, AI can have text processing, image recognition, audio analysis, etc.
Common modalities: Text, Image, Audio, Video, Sensor data, 3D models
2. Embedding
What it is: A way of converting any type of data (text, images, audio) into numbers that AI can understand and compare.
Simple analogy: Like translating different languages into one universal language. Once everything is in the same "number language," AI can find relationships between a photo and its description.
Why it matters: Embeddings allow multimodal AI to connect "a photo of a cat" with the text "fluffy feline sitting on a couch."
3. Fusion
What it is: The technique of combining information from multiple modalities to make better predictions.
Simple analogy: Like how you combine what you see AND hear to understand a movie - neither alone tells the complete story.
Types:
- Early fusion: Combine raw data first, then process
- Late fusion: Process each modality separately, combine results
- Cross-modal attention: Let each modality inform the others during processing
4. Zero-shot / Few-shot Learning
What it is: AI's ability to handle new tasks without being specifically trained for them.
Simple analogy: Like how a person who speaks English well can understand a new slang word from context, without being taught its definition.
In multimodal context: A vision-language model can answer questions about images it has never seen before, using its general understanding.
5. OCR (Optical Character Recognition)
What it is: Technology that converts images of text into machine-readable text.
Simple analogy: Like a human reading text from a photo and typing it out, but done automatically by AI.
Modern OCR: Goes beyond simple character recognition - can understand document structure, tables, handwriting, and multiple languages including Thai.
Why Multimodal AI Matters
1. More Natural Interaction
Humans don't communicate in just one way. We share photos, voice messages, videos, and text. Multimodal AI lets machines understand us the way we naturally communicate.
2. Better Accuracy
By using multiple sources of information, multimodal AI can make more accurate decisions. A system that sees AND reads a document is more reliable than one that only does one.
3. Automation of Complex Tasks
Many real-world tasks require understanding multiple data types:
- Customer service: Text chat + voice calls + image uploads
- Document processing: Scanned images + printed text + handwritten notes
- Quality control: Visual inspection + sensor readings + specifications
4. Accessibility
Multimodal AI enables:
- Text-to-speech for the visually impaired
- Speech-to-text for the hearing impaired
- Image descriptions for screen readers
What Problems Does Multimodal AI Solve?
| Problem | Traditional Approach | Multimodal AI Solution |
|---|---|---|
| ID Verification | Manual review of documents | OCR + Face matching + Liveness detection |
| Customer Support | Separate text/voice/image handling | Unified understanding of all inputs |
| Document Processing | Manual data entry | Automatic extraction from any document |
| Content Moderation | Separate image/text/video checks | Holistic content understanding |
| Medical Diagnosis | Single-modality analysis | Combined imaging + records + notes |
| Accessibility | Limited options | Universal translation between modalities |
How Multimodal AI Works
The Architecture
-
Encoders (One per modality)
- Text encoder: Converts text to numerical representations
- Image encoder: Converts images to feature vectors
- Audio encoder: Converts audio to spectral features
-
Fusion Layer
- Combines encoded representations
- Learns relationships between modalities
- Creates unified understanding
-
Decoder / Output Head
- Generates appropriate output
- Can be text, classification, structured data, etc.
Example Flow: Thai ID Card Processing
Input: Photo of Thai National ID Card
Step 1: Image Encoder
→ Detects document boundaries
→ Identifies card type (Thai ID)
→ Locates text regions and photo
Step 2: OCR Processing
→ Extracts Thai text from each region
→ Handles Thai script nuances
→ Reads both printed and machine text
Step 3: Face Processing
→ Extracts face from ID photo
→ Creates face embedding
→ Ready for verification
Step 4: Fusion & Validation
→ Combines all extracted data
→ Validates field formats
→ Cross-checks consistency
Output: Structured JSON with all fields
{
"name_th": "สมชาย ใจดี",
"name_en": "Somchai Jaidee",
"id_number": "1-1234-56789-01-2",
"birth_date": "1990-01-15",
"face_embedding": [...],
"confidence": 0.98
}
Multimodal AI in Thailand: Real Applications
1. Thai Document OCR
Using Thai National ID OCR:
- Scans Thai ID cards, passports, driver's licenses
- Extracts Thai and English text accurately
- Handles various document conditions and angles
- Returns structured data for easy integration
2. Face Verification & eKYC
Combining Face Recognition with document AI:
- Matches face from ID card to selfie photo
- Liveness Detection prevents photo spoofing
- Complete eKYC workflow in seconds
- Bank-grade security standards
3. Thai Speech Recognition
Using Thai Speech-to-Text:
- Converts Thai speech to text with high accuracy
- Handles various Thai dialects and accents
- Real-time transcription for call centers
- Meeting transcription and voice commands
4. Thai Text-to-Speech
Using Thai Text-to-Speech:
- Natural-sounding Thai voice synthesis
- Multiple voice options (male/female)
- IVR systems and voice assistants
- Audiobook and content narration
5. Multilingual Translation
Using Translation API:
- Translate between Thai, English, Chinese, Japanese
- Combine with speech for real-time interpretation
- Document translation with formatting preserved
Building with iApp's Multimodal AI
iApp Technology provides comprehensive multimodal AI APIs for Thai businesses:
Available Components
| Modality | iApp Product | Capabilities |
|---|---|---|
| Image → Text | Thai OCR APIs | ID cards, documents, receipts |
| Image → Data | Face Recognition | Face detection, matching, liveness |
| Audio → Text | Speech-to-Text | Thai speech transcription |
| Text → Audio | Text-to-Speech | Natural Thai voice synthesis |
| Text → Text | Translation | Multilingual translation |
| Text → Text | OpenThai Chinda | Thai language understanding |
Example: Complete eKYC Flow
import requests
def complete_ekyc_verification(id_card_image, selfie_image):
"""
Complete eKYC using multimodal AI:
1. OCR to extract ID data (Image → Text)
2. Face extraction from ID (Image → Embedding)
3. Selfie face extraction (Image → Embedding)
4. Face comparison (Embedding → Match score)
5. Liveness check (Video → Boolean)
"""
# Step 1: Extract data from ID card
ocr_response = requests.post(
'https://api.iapp.co.th/thai-national-id-ocr/v3',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': id_card_image}
)
id_data = ocr_response.json()
# Step 2: Compare faces
face_response = requests.post(
'https://api.iapp.co.th/face-recognition/v1/compare',
headers={'apikey': 'YOUR_API_KEY'},
files={
'image1': id_card_image,
'image2': selfie_image
}
)
face_match = face_response.json()
# Step 3: Verify liveness (anti-spoofing)
liveness_response = requests.post(
'https://api.iapp.co.th/liveness-detection/v1',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': selfie_image}
)
is_live = liveness_response.json()
return {
'id_data': id_data,
'face_match_score': face_match['similarity'],
'is_live_person': is_live['is_live'],
'verified': face_match['similarity'] > 0.8 and is_live['is_live']
}
Getting Started with Multimodal AI
Step 1: Identify Your Use Case
Common starting points:
- Document processing: Start with Thai OCR
- Voice applications: Start with Speech APIs
- Identity verification: Start with eKYC suite
Step 2: Try the APIs
Test with real data:
- Get your API key
- Try the interactive demos on each product page
- Review the response formats
Step 3: Integrate
- Use our REST APIs from any programming language
- SDKs available for Python, JavaScript, and more
- Comprehensive documentation with examples
Resources
- Get API Access: API Key Management
- Try Thai OCR: Document OCR Demo
- Try Speech AI: Speech-to-Text Demo
- Explore All APIs: Complete API Catalog
- Join Community: Discord
The Future of Multimodal AI
Trends to Watch
- Real-time Processing: Faster models enabling live video analysis and simultaneous translation
- On-device Multimodal: Running complex multimodal AI on smartphones and edge devices
- Thai-specific Models: Better Thai language and document understanding
- Generative Multimodal: AI that creates images, audio, and video from text prompts
- Universal Models: Single models handling all modalities seamlessly
Why Thai Businesses Should Act Now
- Competitive Advantage: Automate document and voice workflows before competitors
- Customer Experience: Offer seamless multi-channel support
- Cost Reduction: Replace manual data entry and verification
- Accuracy Improvement: Reduce human errors in document processing
- Scale Operations: Handle more volume without proportional staff increases
Conclusion
Multimodal AI represents a fundamental shift toward AI systems that understand the world more like humans do - through multiple senses working together. From reading Thai ID cards to transcribing voice calls to verifying identities, multimodal AI is transforming how businesses operate.
For Thai businesses, iApp Technology provides the complete toolkit: Thai OCR for documents, Face Recognition for identity, Speech-to-Text for voice, and Thai LLM for language understanding - all optimized for Thai language and use cases.
Ready to add multimodal AI to your applications? Sign up for free and start with our Thai OCR or Speech APIs today!
Questions? Join our Discord Community or email us at support@iapp.co.th.
iApp Technology Co., Ltd. Thailand's Leading AI Technology Company