Anomaly Detection คืออะไร? คู่มือฉบับสมบูรณ์สำหรับผู้เริ่มต้น

เมื่อธนาคารของคุณบล็อกธุรกรรมที่น่าสงสัยที่คุณไม่ได้ทำ เมื่อ AI ของโรงงานทำนายความล้มเหลวของเครื่องจักรก่อนที่จะเกิดขึ้น หรือเมื่อระบบรักษาความปลอดภัยตรวจจับว่ามีคนใช้รูปถ่ายที่พิมพ์ออกมาแทนใบหน้าจริง — นั่นคือ Anomaly Detection หรือการตรวจจับความผิดปกติกำลังทำงาน มันคือเทคโนโลยี AI ที่ค้นหาเข็มในกองฟาง รูปแบบผิดปกติหนึ่งเดียวในหลายล้านรูปแบบปกติ
Anomaly Detection คืออะไร?
Anomaly Detection (หรือเรียกว่า Outlier Detection การตรวจจับค่าผิดปกติ) คือเทคนิค AI ที่ระบุจุดข้อมูล เหตุการณ์ หรือรูปแบบที่เบี่ยงเบนอย่างมีนัยสำคัญจากบรรทัดฐานที่คาดหวัง มันเหมือนกับการมีสุนัขเฝ้าบ้านอัจฉริยะที่รู้ว่า "ปกติ" เป็นอย่างไร และแจ้งเตือนคุณทันทีเมื่อมีสิ่งผิดปกติเกิดขึ้น
หลักการทำงานของ Anomaly Detection:
- เรียนรู้ ว่าพฤติกรรมปกติเป็นอย่างไรจากข้อมูลในอดีต
- ติดตาม ข้อมูลที่เข้ามาแบบเรียลไทม์หรือเป็นกลุ่ม
- ระบุ การเบี่ยงเบนที่อาจบ่งบอกปัญหา การฉ้อโกง หรือโอกาส
- แจ้งเตือน เมื่อตรวจพบรูปแบบผิดปกติ
เปรียบเทียบง่ายๆ
ลองนึกภาพว่าคุณเป็นเจ้าหน้าที่รักษาความปลอดภัยที่ดูคนหลายร้อยคนเข้าอาคาร:
- วิธีแบบเดิม: คุณพยายามจดจำทุกคนและสังเกตสิ่งผิดปกติ (เป็นไปไม่ได้ในขนาดใหญ่)
- Anomaly detection: AI เรียนรู้รูปแบบการเข้าปกติ (เวลา ความถี่ พฤติกรรม) และแจ้งเตือนทันทีเมื่อมีคนเข้ามาตี 3 ใช้รูปแบบบัตรที่ผิดปกติ หรือประพฤติต่างไป
AI ไม่จำเป็นต้องรู้ทุกภัยคุกคามเฉพาะเจาะจง — มันแค่ต้องรู้จักเมื่อมีบางอย่างไม่เข้ากับรูปแบบที่สร้างไว้ของ "ปกติ"
Anomaly Detection ทำงานอย่างไร
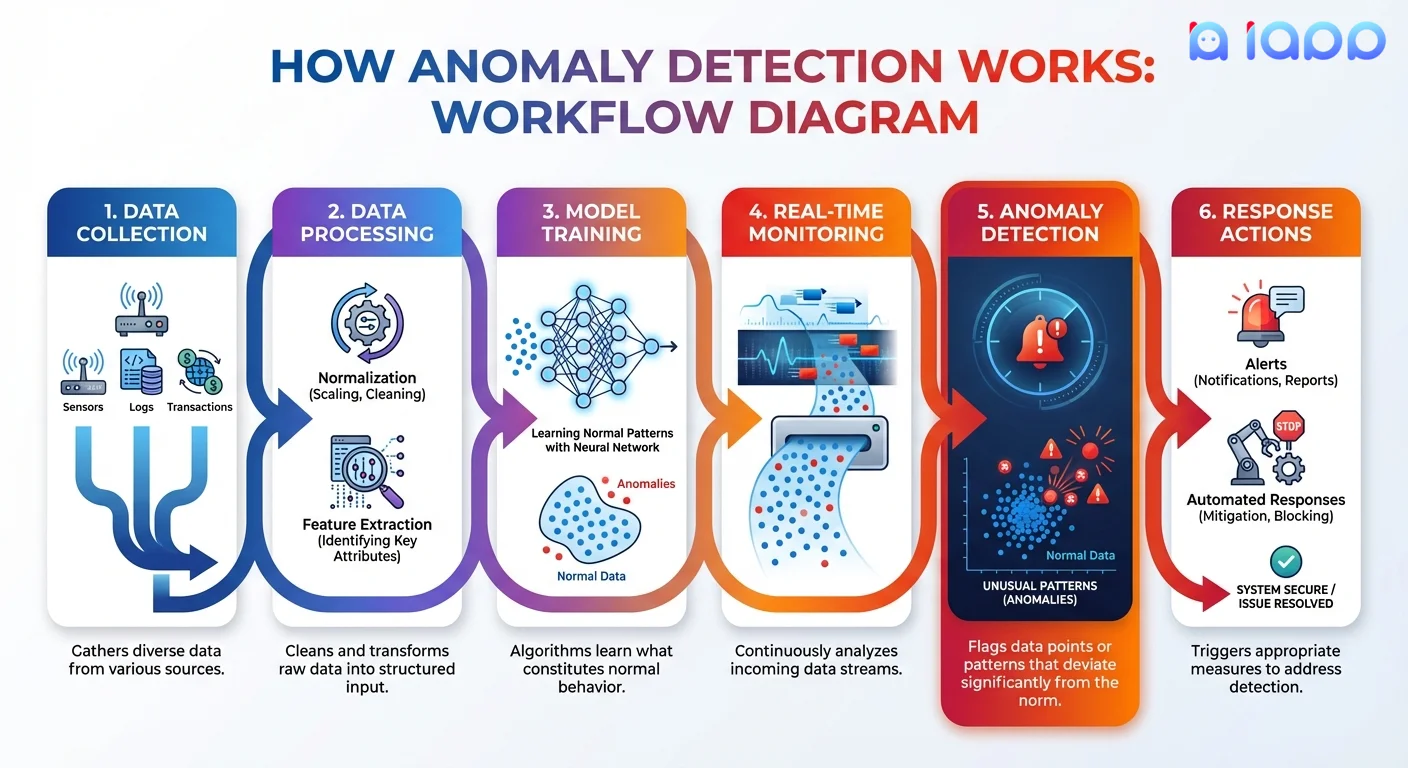
กระบวนการทีละขั้นตอน
1. การรวบรวมข้อมูล
- รวบรวมข้อมูลในอดีตที่แสดงพฤติกรรมปกติ
- แหล่งข้อมูล: บันทึกธุรกรรม กา�รอ่านค่าเซ็นเซอร์ ทราฟฟิกเครือข่าย พฤติกรรมผู้ใช้
- ยิ่งมีข้อมูลมาก โมเดลยิ่งเข้าใจ "ปกติ" ดีขึ้น
2. การเตรียมข้อมูล
- ทำความสะอาดและทำให้ข้อมูลเป็นมาตรฐาน
- จัดการค่าที่ขาดหายและค่าผิดปกติในข้อมูลฝึก
- ดึงคุณลักษณะที่เกี่ยวข้องสำหรับการวิเคราะห์
3. การฝึกโมเดล
- อัลกอริทึมเรียนรู้รูปแบบของพฤติกรรมปกติ
- สร้างการแทนค่าทางคณิตศาสตร์ของ "ปกติ"
- อัลกอริทึมที่แตกต่างเหมาะกับประเภทข้อมูลที่แตกต่างกัน
4. การติดตามแบบเรียลไทม์
- ข้อมูลใหม่ถูกป้อนเข้าโมเดลอย่างต่อเนื่อง
- แต่ละจุดข้อมูลถูกเปรียบเทียบกับรูปแบบที่เรียนรู้
- โมเดลคำนวณว่าแต่ละการสังเกต "ผิดปกติ" แค่ไหน
5. การให้คะแนนความผิดปกติ
- แต่ละจุดข้อมูลได้รับคะแนนความผิดปกติ
- คะแนนสูงขึ้นบ่งบอกการเบี่ยงเบนจากปกติมากขึ้น
- เกณฑ์กำหนดว่าอะไรจะทำให้เกิดการแจ้งเตือน
6. การตอบสนองและดำเนินการ
- ส่งการแจ้งเตือนไปยังทีมหรือระบบที่เกี่ยวข้อง
- สามารถทริกเกอร์การตอบสนองอัตโนมัติ
- คนตรวจสอบสำหรับการตัดสินใจที่สำคัญ
ประเภทของความผิดปกติ
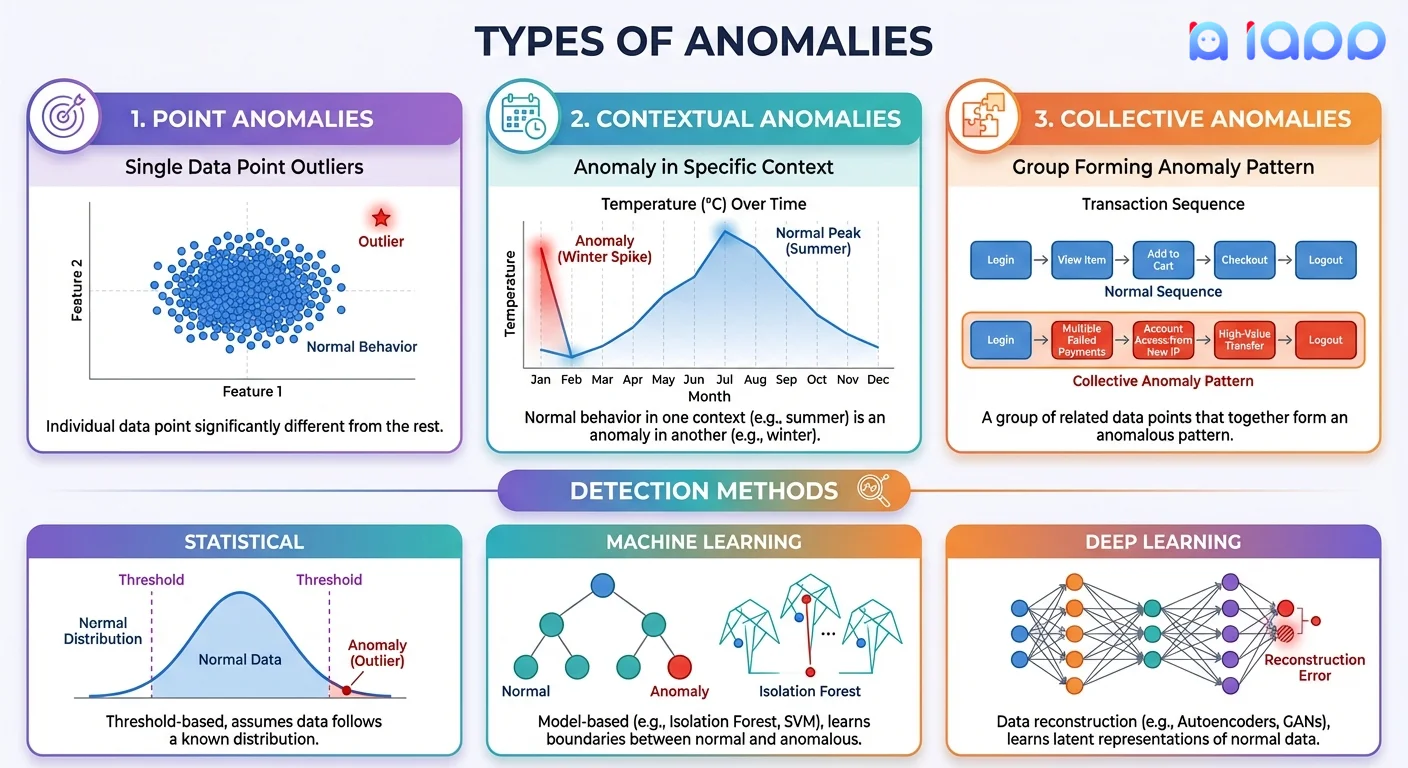
1. Point Anomalies (ความผิดปกติแบบจุด)
คืออะไร: จุดข้อมูลเดียวที่แตกต่างอย่างมีนัยสำคัญจากข้อมูลที่เหลือ
ตัวอย่าง:
- ธุรกรรมบัตรเครดิต ฿500,000 ในขณะที่ค่าเฉลี่ยของลูกค้าคือ ฿5,000
- การอ่านอุณหภูมิ 150°C ในห้องที่ปกติ 25°C
- ผู้ใช้ล็อกอินจากประเทศไทยในขณะที่เคยล็อกอินจากญี่ปุ่นเท่านั้น
ตรวจจับได้ดีด้วย: วิธีทางสถิติ, Isolation Forest, One-Class SVM
2. Contextual Anomalies (ความผิดปกติตามบริบท)
คืออะไร: จุดข้อมูลที่ผิดปกติเฉพาะในบริบทเฉพาะ แต่ปกติในบริบทอื่น
ตัวอย่าง:
- การใช้ไฟฟ้าสูงเป็นเรื่องปกติตอน 1 ทุ่ม (เวลาอาหารเย็น) แต่ผิดปกติตอนตี 3
- ยอดขายเพิ่ม 20% ปกติในช่วงสงกรานต์ แต่ผิดปกติในเดือนปกติ
- ทราฟฟิกเ�ครือข่ายพุ่งสูงเป็นเรื่องที่คาดหวังในเวลาทำการ แต่น่าสงสัยตอนเที่ยงคืน
ตรวจจับได้ดีด้วย: การวิเคราะห์ Time-series, LSTM neural networks, seasonal decomposition
3. Collective Anomalies (ความผิดปกติแบบกลุ่ม)
คืออะไร: กลุ่มของจุดข้อมูลที่รวมกันเป็นรูปแบบผิดปกติ แม้ว่าจุดแต่ละจุดอาจดูปกติ
ตัวอย่าง:
- ลำดับธุรกรรมขนาดเล็กที่รวมกันบ่งบอกการฟอกเงิน
- รูปแบบความพยายามล็อกอินล้มเหลวหลายบัญชี (การโจมตีแบบประสานงาน)
- การดริฟท์ของเซ็นเซอร์ค่อยๆ ที่บ่งบอกการเสื่อมสภาพของอุปกรณ์ตลอดเวลา
ตรวจจับได้ดีด้วย: Sequence models, recurrent neural networks, pattern mining
ประเภทของวิธี Anomaly Detection
1. วิธีทางสถิติ
ทำงานอย่างไร: สมมติว่าข้อมูลเป็นไปตามการแจกแจงทางสถิติ; จุดนอกช่วงที่คาดหวังคือความผิดปกติ
เทคนิคหลัก:
- Z-Score: วัดว่าจุดอยู่ห่างจากค่าเฉลี่ยกี่ส่วนเบี่ยงเบนมาตรฐาน
- IQR (Interquartile Range): แจ้งเตือนจุดที่อยู่นอก Q1-1.5×IQR ถึง Q3+1.5×IQR
- Grubbs' Test: ทดสอบว่าค่าที่สุดขั้วที่สุดเป็นค่าผิดปกติหรือไม่
ข้อดี: เร็ว ตีความได้ง่าย ไม่ต้องการการฝึก ข้อเสีย: สมมติการแจกแจงปกติ มีปัญหากับรูปแบบซับซ้อน
2. วิธี Machine Learning
ทำงานอย่างไร: อัลกอริทึมเรียนรู้รูปแบบปกติจากข้อมูลและแจ้งเตือนการเบี่ยงเบน
เทคนิคหลัก:
- Isolation Forest: แยกความผิดปกติด้วยการแบ่งแบบสุ่ม (ความผิดปกติแยกง่ายกว่า)
- Local Outlier Factor (LOF): วัดการเบี่ยงเบนความหนาแน่นท้องถิ่น; จุดในพื้นที่ความหนาแน่นต่ำคือความผิดปกติ
- One-Class SVM: เรียนรู้ขอบเขตรอบข้อมูลปกติ; จุดนอกคือความผิดปกติ
- K-Means Clustering: จุดที่ไกลจากศูนย์กลางคลัสเตอร์คือความผิดปกติ
ข้อดี: จัดการรูปแบบซับซ้อน ทำงานกับข้อมูลหลายมิติได้ ข้อเสีย: ต้องการข้อมูลฝึก อาจต้องปรับแต่ง
3. วิธี Deep Learning
ทำงานอย่างไร: Neural networks เรียนรู้การแทนค่าที่ซับซ้อนของข้อมูลปกติ
เทคนิคหลัก:
- Autoencoders: เรียนรู้การบีบอัดและสร้างข้อมูลปกติใหม่; reconstruction error สูง = ความผิดปกติ
- Variational Autoencoders (VAE): Autoencoders แบบความน่าจะเป็นพร้อมการประมาณความไม่แน่นอน
- LSTM Networks: จับรูปแบบเวลาในข้อมูลลำดับ
- CNN สำหรับรูปภาพ: ตรวจจับความผิดปกติทางภาพในรูปภาพ (face spoofing, การตรวจจับข้อบกพร่อง)
ข้อดี: จัดการรูปแบบที่ซับซ้อนมาก ทำงานกับรูปภาพ/วิดีโอ/ลำดับได้ ข้อเสีย: ต้องการข้อมูลมากขึ้น ใช้การคำนวณสูง ตีความยากกว่า
คำศัพท์สำคัญอธิบาย (ศัพท์เทคนิคไขข้อข้องใจ)
1. False Positive vs False Negative
False Positive (ข้อผิดพลาดประเภท I): ระบบแจ้งเตือนว่าบางอย่างเป็นความผิดปกติ เมื่อจริงๆ แล้วมันปกติ
- ตัวอย่าง: ธนาคารบล็อกการซื้อที่ถูกต้องเพราะมัน "ดูน่าสงสัย"
- ผลกระทบ: ความรำคาญ เสียเวลาตรวจสอบ ลูกค้าไม่พอใจ
False Negative (ข้อผิดพลาดประเภท II): ระบบพลาดความผิดปกติจริง จำแนกว่าปกติ
- ตัวอย่าง: ธุรกรรมฉ้อโกงผ่านไปโดยไม่ถูกตรวจจับ
- ผลกระทบ: การละเมิดความปลอดภัย การสูญเสียทางการเงิน ปัญหาที่ไม่ถูกตรวจจับ
การแลกเปลี่ยน: การลด false positives มักเพิ่ม false negatives และในทางกลับกัน ความสมดุลที่ถูกต้องขึ้นอยู่กับต้นทุนของข้อผิดพลาดแต่ละประเภ�ท
2. Threshold (เกณฑ์)
คืออะไร: ขอบเขตที่แยก "ปกติ" จาก "ผิดปกติ" ตามคะแนนความผิดปกติ
อธิบายง่ายๆ: คิดว่ามันเป็นปุ่มความไวต่อการตรวจจับ เกณฑ์ต่ำจับความผิดปกติมากขึ้น (แต่ก็มี false positives มากขึ้น) เกณฑ์สูงพลาดความผิดปกติบางส่วน (false positives น้อยลง แต่ false negatives มากขึ้น)
ตัวอย่าง:
- คะแนนความผิดปกติ > 0.9: เข้มงวดมาก แจ้งเตือนเฉพาะความผิดปกติที่ชัดเจน
- คะแนนความผิดปกติ > 0.5: ปานกลาง แจ้งเตือนกรณีที่น่าสงสัย
- คะแนนความผิดปกติ > 0.3: ไวต่อการตรวจจับ แจ้งเตือนทุกอย่างที่ผิดปกติเล็กน้อย
3. Reconstruction Error (ความคลาดเคลื่อนในการสร้างใหม่)
คืออะไร: ในการตรวจจับโดยใช้ autoencoder คือความแตกต่างระหว่างข้อมูลที่ป้อนเข้าและความพยายามของโมเดลในการสร้างมันใหม่
อธิบายง่ายๆ: โมเดลเรียนรู้การบีบอัดและคลายข้อมูลปกติ เมื่อมันเห็นความผิดปกติที่มันไม่เคยเรียนรู้ มันสร้างมันใหม่ได้ไม่ดี ความแตกต่าง (ความคลาดเคลื่อน) ยิ่งใหญ่ ยิ่งมีโอกาสเป็นความผิดปกติ
ตัวอย่าง: Autoencoder ที่ฝึกกับใบหน้าจริงมีปัญหาในการสร้างรูปถ่ายที่พิมพ์หรือหน้ากากใหม่ ส่งผลให้ reconstruction error สูง → ตรวจจับว่าเป็น face spoofing
4. Anomaly Score (คะแนนความผิดปกติ)
คืออะไร: ค่าตัวเลขที่บ่งบอกว่าจุดข้อมูลมีโอกาสเป็นความผิดปกติแค่ไหน (โดยปกติ 0-1 หรือไม่มีขอบเขต)
อธิบายง่ายๆ: "คะแนนความแปลก" ของจุดข้อมูล คะแนนสูงขึ้นหมายถึงผิดปกติมากขึ้น การตีความที่แน่นอนขึ้นอยู่กับอัลกอริทึม
ตัวอย่าง:
- คะแนน 0.1: ปกติมาก ไม่ต้องกังวล
- คะแนน 0.5: ค่อนข้างผิดปกติ ควรติดตาม
- คะแนน 0.95: ผิดปกติมาก ต้องตรวจสอบทันที
5. Baseline / Normal Profile (โปรไฟล์พื้นฐาน)
คืออะไร: การแทนค่าที่เรียนรู้ของสิ่งที่ "ปกติ" เป็นอย่างไรสำหรับระบบ
อธิบายง่ายๆ: ก่อนตรวจจับความผิดปกติ ระบบต้องเข้าใจก่อนว่าปกติเป็นอย่างไร baseline นี้สร้างจากข้อมูลในอดีตของการทำงานปกติ
ทำไมถึงสำคัญ: baseline ที่กำหนดไม่ดีนำไปสู่การตรวจจับที่ไม่ดี ถ้าข้อมูลฝึกมีความผิดปกติ โมเดลอาจพิจารณาว่ามันปกติ
ทำไม Anomaly Detection ถึงสำคัญ
1. การป้องกันการฉ้อโกง
ปัญหา: การฉ้อโกงทางการเงินสร้างความเสียหายให้ธุรกิจหลายพันล้านต่อปี โซลูชัน: ตรวจจับธุรกรรมที่น่าสงสัยแบบเรียลไทม์
ผลกระทบจริง:
- บล็อกธุรกรรมบัตรเครดิตฉ้อโกงก่อนเสร็จสิ้น
- ตรวจจับความพยายามยึดครองบัญชี
- ระบุรูปแบบการฟอกเงิน
2. Cybersecurity
ปัญหา: การโจมตีทางไซเบอร์พัฒนาเร็วกว่าระบบตามกฎจะปรับตัวได้ โซลูชัน: AI ตรวจจับพฤติกรรมเครือข่ายผิดปกติโดยไม่มีกฎที่กำหนดไว้ล่วงหน้า
ผลกระทบจริง:
- ตรวจจับการโจมตี zero-day ตามพฤติกรรม ไม่ใช่ลายเซ็น
- ระบุภัยคุกคามจากภายใน
- ตรวจจับความพยายามขโมยข้อมูล
3. Predictive Maintenance
ปัญหา: ความล้มเหลวของอุปกรณ์ทำให้เกิดการหยุดทำงานที่มีค่าใช้จ่ายสูง โซลูชัน: ตรวจจับสัญญาณเตือนล่วงหน้าในข้อมูลเซ็นเซอร์
ผลกระทบจริง:
- ทำนายความล้มเหลวของเครื่องจักรล่วงหน้าหลายวัน
- ลดการหยุ��ดทำงานที่ไม่ได้วางแผน 30-50%
- ปรับตารางการบำรุงรักษาให้เหมาะสม
4. การยืนยันตัวตน
ปัญหา: ผู้ฉ้อโกงใช้รูปถ่ายปลอม หน้ากาก และวิดีโอเพื่อหลีกเลี่ยงระบบไบโอเมตริกซ์ โซลูชัน: Face liveness detection ระบุความพยายาม spoofing
ผลกระทบจริง:
- ตรวจจับรูปถ่ายที่พิมพ์ หน้ากาก และการเล่นซ้ำจากหน้าจอ
- รักษาความปลอดภัยแอปพลิเคชัน eKYC และธนาคาร
- บรรลุความแม่นยำ 99%+ ในการตรวจจับ spoofing
5. Quality Control
ปัญหา: การตรวจสอบด้วยตนเองไม่สามารถจับข้อบกพร่องทั้งหมดได้ โซลูชัน: AI ตรวจจับความผิดปกติทางภาพในผลิตภัณฑ์
ผลกระทบจริ�ง:
- การตรวจจับข้อบกพร่องอัตโนมัติในการผลิต
- คุณภาพที่สม่ำเสมอทั่วทุกผลิตภัณฑ์
- ลดต้นทุนการตรวจสอบโดยคน
ปัญหาที่ Anomaly Detection แก้ได้
| อุตสาหกรรม | ปัญหา | โซลูชัน Anomaly Detection |
|---|---|---|
| ธนาคาร | การฉ้อโกงบัตรเครดิต | การติดตามธุรกรรมแบบเรียลไทม์ |
| ประกันภัย | เคลมฉ้อโกง | การตรวจจับรูปแบบในข้อมูลเคลม |
| การแพทย์ | การฉ้อโกงทางการแพทย์ | การตรวจจับรูปแบบการเรียกเก็บเงินผิดปกติ |
| การผลิต | ความล้มเหลวของอุปกรณ์ | การติดตามความผิดปกติของเซ็นเซอร์ |
| ค้าปลีก | การสูญหายของสินค้า | รูปแบบการขาย/สินค้าคงคลังผ��ิดปกติ |
| โทรคมนาคม | การบุกรุกเครือข่าย | การตรวจจับความผิดปกติของทราฟฟิก |
| eKYC | การปลอมตัวตน | Face liveness detection |
Anomaly Detection ในประเทศไทย: การประยุกต์ใช้จริง
1. ธนาคารและบริการทางการเงิน
กรณีใช้งาน: ธนาคารไทยตรวจจับธุรกรรมฉ้อโกง
วิธีการทำงาน:
- ติดตามธุรกรรมนับล้านต่อวัน
- เรียนรู้รูปแบบการใช้จ่ายปกติต่อลูกค้า
- แจ้งเตือนจำนวนเงิน สถานที่ หรือเวลาที่ผิดปกติ
- บล็อกธุรกรรมที่น่าสงสัยแบบเรียลไทม์
ความท้าทายเฉพาะประเทศไทยที่แก้ได้:
- ตรวจจับการฉ้อโกงในช่วงปริมาณสูง (สงกรานต์ ปลายปี)
- เข้าใจรูปแบบการใช้จ่ายของคนไทย
- ปกป้องผู้ใช้ mobile banking
2. eKYC และ Face Spoofing Detection
กรณีใช้งาน: ป้องกันการฉ้อโกงตัวตนในการเปิดบัญชีดิจิทัล
วิธีการทำงาน:
- ตรวจจับว่ารูปใบหน้ามาจากคนจริงหรือความพยายาม spoofing
- ระบุรูปถ่ายที่พิมพ์ หน้ากาก การแสดงจากหน้าจอ การเล่นวิดีโอซ้ำ
- ให้คะแนนความเป็นคนจริงสำหรับแต่ละความพยายามยืนยัน
ตัวอย่างกับ iApp API:
import requests
# ตรวจจับความพยายาม face spoofing
with open('face_image.jpg', 'rb') as f:
response = requests.post(
'https://api.iapp.co.th/v3/store/ekyc/face-passive-liveness',
headers={'apikey': 'YOUR_API_KEY'},
files={'file': f}
)
result = response.json()
# Output: {"predict": "REAL", "score": 0.9987, ...}
# หรือ: {"predict": "SPOOF", "score": 0.9999, ...}
Face Passive Liveness Detection ของ iApp ได้รับการรับรอง iBeta Level 1 บรรลุความแม่นยำ 99.43% จากการทดสอบ 7,680 ครั้ง
3. Content Moderation
กรณีใช้งาน: ตรวจจับเนื้อหาที่เป็นพิษหรือไม่เหมาะสมบนแพลตฟอร์มไทย
วิธีการทำงาน:
- ติดตามเนื้อหาที่ผู้ใช้สร้างขึ้น
- จำแนกข้อความว่าเป็นพิษหรือไม่เป็นพิษ
- แจ้งเตือนรูปแบบเนื้อหาผิดปกติ (แคมเปญสแปม การโจมตีประสานงาน)
ตัวอย่างกับ iApp API:
import requests
# ตรวจจับเนื้อหาภาษาไทยที่เป็นพิษ
response = requests.post(
'https://api.iapp.co.th/v3/store/nlp/toxicity-classification',
headers={'apikey': 'YOUR_API_KEY'},
params={'text': 'ข้อความที่ต้องการตรวจสอบ'}
)
result = response.json()
# {"label": "toxic", "score": 0.89} หรือ {"label": "non_toxic", "score": 0.92}
4. Quality Control ในการผลิต
กรณีใช้งาน: โรงงานไทยตรวจจับข้อบกพร่องของผลิตภัณฑ์
วิธีการทำงาน:
- กล้องจับภาพผลิตภัณฑ์บนสายการผลิต
- AI เปรียบเทียบกับลักษณะผลิตภัณฑ์ "ปกติ" ที่เรียนรู้
- แจ้งเตือนความผิดปกติทางภาพ (รอยขีดข่วน ชิ้นส่วนที่หายไป ความแตกต่างของสี)
5. Smart City และ IoT
กรณีใช้งาน: การติดตามโครงสร้างพื้นฐานและสาธารณูปโภค
วิธีการทำงาน:
- รวบรวมข้อมูลจากเซ็นเซอร์ (มิเตอร์น้ำ มิเตอร์ไฟฟ้า การจราจร)
- ตรวจจับรูปแบบผิดปกติที่บ่งบอกการรั่วไหล การขโมย หรือความล้มเหลว
- เปิดใช้งาน predictive maintenance สำหรับโครงสร้างพื้นฐานของเมือง
วิธีใช้ iApp Anomaly Detection APIs
iApp Technology ให้บริการ Anomaly Detection APIs พร้อมใช้งานจริงสำหรับกรณีใช้งานต่างๆ
Face Liveness Detection (Anti-Spoofing)
ตรวจจับว่ารูปใบหน้ามาจากคนจริงหรือความพยายาม spoofing
curl -X POST 'https://api.iapp.co.th/v3/store/ekyc/face-passive-liveness' \
-H 'apikey: YOUR_API_KEY' \
-F 'file=@face_image.jpg'
การตอบสนอง:
{
"predict": "SPOOF",
"score": 0.9999,
"data": {
"SPOOF": 0.9999,
"REAL": 0.0001
}
}
Toxicity Detection
ตรวจจับเนื้อหาผิดปกติ/เป็นพิษในข้อความภาษาไทย
curl -X POST 'https://api.iapp.co.th/v3/store/nlp/toxicity-classification' \
-H 'apikey: YOUR_API_KEY' \
-d 'text=ข้อความที่ต้องการตรวจสอบ'
ตัวอย่าง Python: Face Spoofing Detection
import requests
def detect_spoofing(image_path, api_key):
"""ตรวจจับว่ารูปใบหน้าเป็นของจริงหรือปลอม"""
with open(image_path, 'rb') as f:
response = requests.post(
'https://api.iapp.co.th/v3/store/ekyc/face-passive-liveness',
headers={'apikey': api_key},
files={'file': f}
)
result = response.json()
is_real = result['predict'] == 'REAL'
confidence = result['score']
print(f"การตรวจจับ: {'คนจริง' if is_real else 'ความพยายาม Spoofing'}")
print(f"ความมั่นใ��จ: {confidence:.2%}")
return result
# การใช้งาน
result = detect_spoofing('selfie.jpg', 'YOUR_API_KEY')
เริ่มต้นกับ Anomaly Detection
สำหรับผู้ใช้ธุรกิจ
- ระบุกรณีใช้งานของคุณ: คุณพยายามตรวจจับความผิดปกติอะไร? (การฉ้อโกง ข้อบกพร่อง การบุกรุก การปลอม)
- รวบรวมข้อมูลในอดีต: คุณต้องการตัวอย่างพฤติกรรมปกติเพื่อฝึกโมเดล
- เลือกแนวทางที่ถูกต้อง: APIs สำเร็จรูป (เช่น iApp) หรือโมเดลที่กำหนดเอง
- เริ่มต้นด้วยการทดลอง: ทดสอบกับชุดย่อยก่อนการใช้งานเต็มรูปแบบ
- ติดตามและปรับแต่ง: ปรับเกณฑ์ตามอัตรา false positive/negative
สำหรับนักพัฒนา
- รับการเข้าถึง API: สมัคร API Key ฟรี
- อ่านเอกสาร: Face Liveness Detection, Toxicity Classification
- ทดสอบกับข้อมูลตัวอย่าง: ใช้ demo แบบโต้ตอบ
- บูรณาการ: เพิ่ม anomaly detection เข้ากับแอปพลิเคชันของคุณ
- ติดตามประสิทธิภาพ: ตรวจสอบความแม่นยำในการตรวจจับและปรับเกณฑ์
แหล่งข้อมูล
- Face Spoofing Detection: Face Passive Liveness API
- Content Moderation: Toxicity Classification API
- Face Verification: Face Verification API
- รับ API Key: การจัดการ API Key
- เข้าร่วมชุมชน: Discord
อนาคตของ Anomaly Detection
แนวโน้มที่ต้องจับตาในปี 2025
- Edge AI: Anomaly detection โดยตรงบนอุปกรณ์ (IoT sensors, กล้อง) สำหรับการตอบสนองทันที
- Federated Learning: ฝึกโมเดลข้ามข้อมูลกระจายโดยไม่ต้องรวมศูนย์ข้อมูลที่ละเอียดอ่อน
- Explainable AI: โมเดลที่อธิบายว่าทำไมบางอย่างถูกแจ้งเตือนว่าผิดปกติ
- Multimodal Detection: การรวมสัญญาณข้อความ รูปภาพ เสียง และพฤติกรรม
- Self-Adaptive Systems: โมเดลที่อัปเดต baseline อัตโนมัติเมื่อรูปแบบปกติวิวัฒนาการ
ทำไมธุรกิจไทยควรลงทุน��ตอนนี้
- เศรษฐกิจดิจิทัลที่เติบโต: ธุรกรรมดิจิทัลมากขึ้น = โอกาสการฉ้อโกงมากขึ้น
- การปฏิบัติตามกฎระเบียบ: ธปท. และ ก.ล.ต. กำหนดให้มีการตรวจจับการฉ้อโกงที่แข็งแกร่ง
- ความได้เปรียบทางการแข่งขัน: ความปลอดภัยที่ดีกว่าสร้างความไว้วางใจของลูกค้า
- การลดต้นทุน: การตรวจจับอัตโนมัติ vs การตรวจสอบด้วยตนเอง
- การป้องกันแบบเรียลไทม์: หยุดภัยคุกคามก่อนที่ความเสียหายจะเกิดขึ้น
สรุป
Anomaly Detection คือเทคโนโลยี AI ที่ค้นหาสิ่งผิดปกติในหลายสิ่งปกติ — ธุรกรรมฉ้อโกงในหลายล้านธุรกรรมที่ถูกต้อง ใบหน้าที่ปลอมแปลงในการยืนยันตัวจริง เครื่องจักรที่กำลังเสียในหลายเครื่องที่สมบูรณ์ ด้วยการเรียนรู้ว่า "ปกติ" เป็นอย่างไร ระบบเหล่านี้สามารถระบุภัยคุกคาม การฉ้อโกง และปัญหาที่เป็นไปไม่ได้ที่จะจับได้ด้วยตนเอง
สำหรับธุรกิจไทย การมี anomaly detection ที่แข็งแกร่งไม่ใช่ตัวเลือกอีกต่อไป ไม่ว่าคุณจะปกป้องตัวตนลูกค้าด้วย Face Liveness Detection ตรวจสอบเนื้อหาด้วย Toxicity Classification หรือรักษาความปลอดภัยธุรกรรม iApp Technology ให้บริการ APIs พร้อมใช้งานจริงที่สร้างสำหรับความต้องการธุรกิจไทย
พร้อมที่จะตรวจจับความผิดปกติในธุรกิจของคุณ? สมัครฟรี และเริ่มปกป้องระบบของคุณวันนี้!
มีคำถาม? เข้าร่วม Discord Community หรืออีเมลหาเราที่ support@iapp.co.th
iApp Technology Co., Ltd. บร��ิษัท AI ชั้นนำของประเทศไทย
แหล่งข้อมูล: